
Robots.txt: что это такое и как его создать (полное руководство)
Опубликовано: 2023-05-05Если вы владеете веб-сайтом или управляете его содержимым, вы, вероятно, слышали о robots.txt. Это файл, который инструктирует роботов поисковых систем о том, как сканировать и индексировать страницы вашего веб-сайта. Несмотря на его важность для поисковой оптимизации (SEO), многие владельцы веб-сайтов упускают из виду значение хорошо разработанного файла robots.txt.
В этом полном руководстве мы рассмотрим, что такое robots.txt, почему он важен для SEO и как создать файл robots.txt для вашего веб-сайта.
Что такое файл robots.txt?
robots.txt — это файл, который сообщает роботам поисковых систем (также известным как сканеры или пауки), какие страницы или разделы веб-сайта следует сканировать, а какие нет. Это простой текстовый файл, расположенный в корневом каталоге веб-сайта, и обычно он содержит список каталогов, файлов или URL-адресов, которые веб-мастер хочет заблокировать от индексации или сканирования поисковыми системами.
Вот как выглядит файл robots.txt:

Почему файл robots.txt важен?
Есть три основные причины, по которым файл robots.txt важен для вашего сайта:
1. Максимизируйте краулинговый бюджет
«Бюджет сканирования» означает количество страниц, которые Google будет сканировать на вашем сайте в любой момент времени. Число зависит от размера, состояния и количества обратных ссылок на вашем сайте.
Бюджет сканирования важен, потому что, если количество страниц на вашем сайте превысит бюджет сканирования, у вас будут страницы, которые не будут проиндексированы.
Кроме того, страницы, которые не проиндексированы, не будут ранжироваться ни за что.
Используя файл robots.txt для блокировки бесполезных страниц, робот Googlebot (веб-сканер Google) может потратить больше вашего краулингового бюджета на важные страницы.
2. Блокируйте непубличные страницы
На вашем сайте много страниц, которые вы не хотите индексировать.
Например, у вас может быть внутренняя страница результатов поиска или страница входа. Эти страницы должны существовать. Тем не менее, вы не хотите, чтобы на них попадали случайные люди.
В этом случае вы должны использовать robots.txt, чтобы запретить сканерам поисковых систем и ботам доступ к определенным страницам.
3. Запрет индексации ресурсов
Иногда вы захотите, чтобы Google исключил такие ресурсы, как PDF-файлы, видео и изображения, из результатов поиска.
Возможно, вы хотите сохранить эти ресурсы в секрете или хотите, чтобы Google уделял больше внимания важному контенту.
В таких случаях использование robots.txt — лучший способ предотвратить их индексацию.
Как работает файл robots.txt?
Файлы robots.txt указывают ботам поисковых систем, какие страницы или каталоги веб-сайта они должны или не должны сканировать или индексировать.
Во время сканирования роботы поисковых систем находят ссылки и переходят по ним. Этот процесс ведет их от сайта X к сайту Y и сайту Z через миллиарды ссылок и веб-сайтов.
Когда бот заходит на сайт, он первым делом ищет файл robots.txt.
Если он обнаружит его, он прочитает файл, прежде чем делать что-либо еще.
Например, предположим, что вы хотите разрешить всем ботам, кроме DuckDuckGo, сканировать ваш сайт:
User-agent: DuckDuckBot Disallow: /
Примечание. Файл robots.txt может содержать только инструкции; он не может их навязывать. Это похоже на кодекс поведения. Хорошие боты (например, поисковые роботы) будут следовать правилам, тогда как плохие боты (например, спам-боты) будут их игнорировать.
Как найти файл robots.txt?
Файл robots.txt, как и любой другой файл на вашем веб-сайте, размещается на вашем сервере.
Вы можете получить доступ к файлу robots.txt любого веб-сайта, введя полный URL-адрес домашней страницы, а затем добавив /robots.txt в конце, например https://pickupwp.com/robots.txt.
Однако, если на веб-сайте нет файла robots.txt, вы получите сообщение об ошибке «404 Not Found».
Как создать файл robots.txt?
Прежде чем показать, как создать файл robots.txt, давайте сначала рассмотрим синтаксис robots.txt.
Синтаксис файла robots.txt можно разбить на следующие компоненты:
- Пользовательский агент: указывает робота или поискового робота, к которому относится запись. Например, «User-agent: Googlebot» будет применяться только к поисковому роботу Google, а «User-agent: *» — ко всем поисковым роботам.
- Запретить: указывает страницы или каталоги, которые робот не должен сканировать. Например, «Запретить: /private/» запретит роботам сканировать любые страницы в «частном» каталоге.
- Разрешить: указывает страницы или каталоги, которые робот должен сканировать, даже если родительский каталог запрещен. Например, «Разрешить: /public/» позволит роботам сканировать любые страницы в «общедоступном» каталоге, даже если родительский каталог запрещен.
- Crawl-delay: указывает время в секундах, в течение которого робот должен ждать перед сканированием веб-сайта. Например, «Crawl-delay: 10» указывает роботу подождать 10 секунд, прежде чем сканировать веб-сайт.
- Карта сайта: указывает расположение карты сайта веб-сайта. Например, «Карта сайта: https://www.example.com/sitemap.xml» сообщит роботу о расположении карты сайта веб-сайта.
Вот пример файла robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Примечание. Важно отметить, что файлы robots.txt чувствительны к регистру, поэтому важно использовать правильный регистр при указании URL-адресов.
Например, /public/ — это не то же самое, что /public/.
С другой стороны, такие директивы, как «Разрешить» и «Запретить», не чувствительны к регистру, поэтому вам решать, использовать их с заглавной буквы или нет.
Изучив синтаксис robots.txt, вы можете создать файл robots.txt с помощью генератора robots.txt или создать его самостоятельно.
Вот как создать файл robots.txt всего за четыре шага:
1. Создайте новый файл и назовите его Robots.txt.
Просто откройте документ .txt в любом текстовом редакторе или веб-браузере.
Затем дайте документу имя robots.txt. Для работы он должен называться robots.txt.
После этого вы можете начать вводить директивы.
2. Добавьте директивы в файл robots.txt
Файл robots.txt содержит одну или несколько групп директив, каждая из которых содержит несколько строк инструкций.
Каждая группа начинается с «User-agent» и содержит следующие данные:
- К кому относится группа (пользовательский агент)
- К каким каталогам (страницам) или файлам может получить доступ агент?
- К каким каталогам (страницам) или файлам агент не имеет доступа?
- Карта сайта (необязательно), чтобы информировать поисковые системы о сайтах и файлах, которые вы считаете важными.
Строки, не соответствующие ни одной из этих директив, сканеры игнорируют.
Например, вы хотите запретить Google сканировать ваш каталог /private/.

Это будет выглядеть так:
User-agent: Googlebot Disallow: /private/
Если бы у вас были подобные дальнейшие инструкции для Google, вы бы поместили их в отдельную строку прямо под следующим образом:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Кроме того, если вы закончили с конкретными инструкциями Google и хотите создать новую группу директив.
Например, если вы хотите, чтобы все поисковые системы не сканировали ваши каталоги /archive/ и /support/.
Это будет выглядеть так:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Когда вы закончите, вы можете добавить свою карту сайта.
Ваш заполненный файл robots.txt должен выглядеть следующим образом:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Затем сохраните файл robots.txt. Помните, что он должен называться robots.txt.
Дополнительные полезные правила robots.txt можно найти в этом полезном руководстве от Google.
3. Загрузите файл robots.txt
Сохранив файл robots.txt на свой компьютер, загрузите его на свой веб-сайт и сделайте его доступным для сканирования поисковыми системами.
К сожалению, нет никакого инструмента, который мог бы помочь с этим шагом.
Загрузка файла robots.txt зависит от файловой структуры вашего сайта и веб-хостинга.
Инструкции по загрузке файла robots.txt можно найти в Интернете или обратиться к своему хостинг-провайдеру.
4. Проверьте файл robots.txt
После того, как вы загрузили файл robots.txt, вы можете проверить, видит ли его кто-нибудь и может ли его прочитать Google.
Просто откройте новую вкладку в браузере и найдите файл robots.txt.
Например, https://pickupwp.com/robots.txt.
Если вы видите файл robots.txt, вы готовы протестировать разметку (HTML-код).
Для этого вы можете использовать тестер Google robots.txt.
Примечание. У вас есть учетная запись Search Console, настроенная для проверки файла robots.txt с помощью средства тестирования robots.txt.
Тестер robots.txt найдет любые синтаксические предупреждения или логические ошибки и выделит их.
Кроме того, он также показывает вам предупреждения и ошибки под редактором.
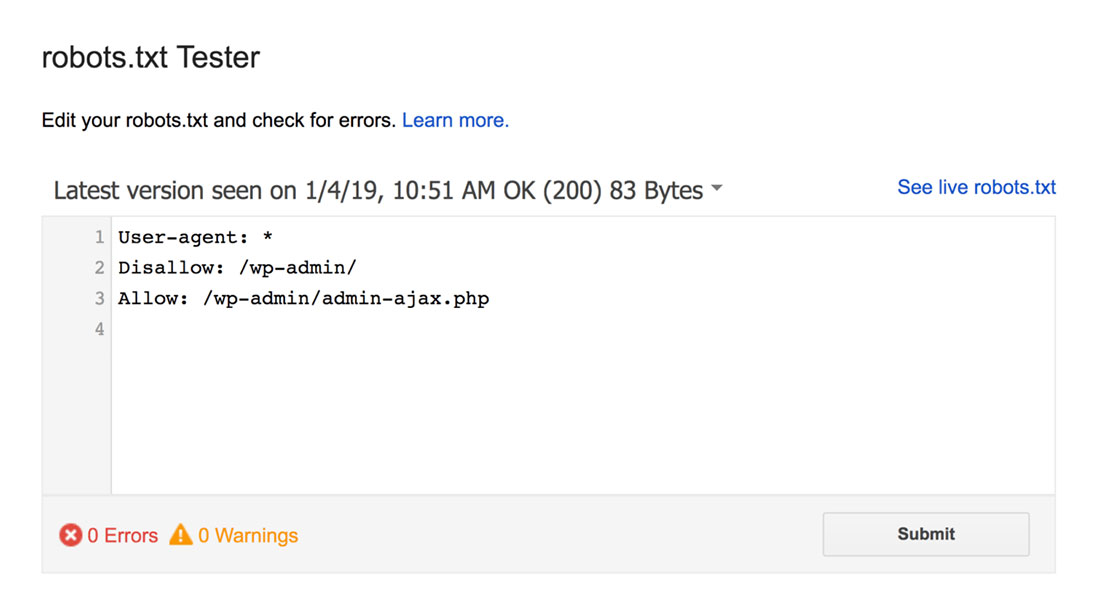
Вы можете редактировать ошибки или предупреждения на странице и повторно тестировать их так часто, как это необходимо.
Просто имейте в виду, что изменения, сделанные на странице, не сохраняются на вашем сайте.
Чтобы внести какие-либо изменения, скопируйте и вставьте это в файл robots.txt вашего сайта.
Лучшие практики robots.txt
Помните об этих рекомендациях при создании файла robots.txt, чтобы избежать некоторых распространенных ошибок.
1. Используйте новые строки для каждой директивы
Чтобы не запутать сканеры поисковых систем, добавляйте каждую директиву в новую строку в файле robots.txt. Это относится как к разрешающим, так и к запрещающим правилам.
Например, если вы не хотите, чтобы поисковый робот сканировал ваш блог или страницу контактов, добавьте следующие правила:
Disallow: /blog/ Disallow: /contact/
2. Используйте каждый пользовательский агент только один раз
У ботов нет проблем, если вы снова и снова используете один и тот же пользовательский агент.
Тем не менее, использование его только один раз сохраняет порядок и снижает вероятность человеческой ошибки.
3. Используйте подстановочные знаки для упрощения инструкций
Если вам нужно заблокировать большое количество страниц, добавление правила для каждой из них может занять много времени. К счастью, вы можете использовать подстановочные знаки для упрощения инструкций.
Подстановочный знак — это символ, который может представлять один или несколько символов. Наиболее часто используемым подстановочным знаком является звездочка (*).
Например, если вы хотите заблокировать все файлы, оканчивающиеся на .jpg, вы должны добавить следующее правило:
Disallow: /*.jpg
4. Используйте «$», чтобы указать конец URL-адреса
Знак доллара ($) — это еще один подстановочный знак, который можно использовать для обозначения конца URL-адреса. Это полезно, если вы хотите ограничить доступ к определенной странице, но не к последующим.
Предположим, вы хотите заблокировать страницу контакта, но не страницу успеха контакта, вы должны добавить следующее правило:
Disallow: /contact$
5. Используйте решетку (#), чтобы добавить комментарии
Все, что начинается с хеша (#), сканеры игнорируют.
В результате разработчики часто используют хэш для добавления комментариев в файл robots.txt. Это держит документ организованным и удобочитаемым.
Например, если вы хотите, чтобы все файлы заканчивались на .jpg, вы можете добавить следующий комментарий:
# Block all files that end in .jpg Disallow: /*.jpg
Это помогает любому понять, для чего предназначено правило и почему оно существует.
6. Используйте отдельные файлы robots.txt для каждого поддомена
Если у вас есть веб-сайт с несколькими поддоменами, рекомендуется создать для каждого из них отдельный файл robots.txt. Это позволяет систематизировать информацию и помогает сканерам поисковых систем легче понять ваши правила.
Подведение итогов!
Файл robots.txt — полезный инструмент SEO, поскольку он указывает ботам поисковых систем, что индексировать, а что нет.
Однако важно использовать его с осторожностью. Так как неправильная настройка может привести к полной деиндексации вашего сайта (например, с помощью Disallow:/).
Как правило, хороший способ — позволить поисковым системам сканировать как можно большую часть вашего сайта, сохраняя при этом конфиденциальную информацию и избегая дублирования контента. Например, вы можете использовать директиву Disallow, чтобы запретить доступ к определенным страницам или каталогам, или директиву Allow, чтобы переопределить правило Disallow для конкретной страницы.
Также стоит упомянуть, что не все боты следуют правилам, указанным в файле robots.txt, поэтому это не идеальный метод контроля того, что индексируется. Но это по-прежнему ценный инструмент в вашей стратегии SEO.
Мы надеемся, что это руководство поможет вам узнать, что такое файл robots.txt и как его создать.
Для получения дополнительной информации вы можете проверить эти другие полезные ресурсы:
- 15 практических советов по ведению блога для начинающих блоггеров
- Раскрытие силы ключевых слов с длинным хвостом (руководство для начинающих)
И, наконец, следите за нами в Twitter, чтобы получать регулярные обновления новых статей.