
Файл WordPress robots.txt… что это такое и что он делает
Опубликовано: 2020-11-25Вы когда-нибудь задумывались, что такое файл robots.txt и для чего он? Robots.txt используется для связи с поисковыми роботами (известными как боты), используемыми Google и другими поисковыми системами. Он сообщает им, какие части вашего сайта индексировать, а какие игнорировать. Таким образом, файл robots.txt может помочь (или потенциально сломать!) ваши усилия по SEO. Если вы хотите, чтобы ваш веб-сайт хорошо ранжировался, важно хорошо понимать robots.txt!
Где находится robots.txt?
WordPress обычно запускает так называемый «виртуальный» файл robots.txt, что означает, что он недоступен через SFTP. Однако вы можете просмотреть его основное содержимое, перейдя по адресу yourdomain.com/robots.txt. Вероятно, вы увидите что-то вроде этого:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpВ первой строке указывается, к каким ботам будут применяться правила. В нашем примере звездочка означает, что правила будут применяться ко всем ботам (например, от Google, Bing и так далее).
Вторая строка определяет правило, запрещающее ботам доступ к папке /wp-admin, а третья строка указывает, что ботам разрешено анализировать файл /wp-admin/admin-ajax.php.
Добавьте свои собственные правила
Для простого веб-сайта WordPress правил по умолчанию, применяемых WordPress к файлу robots.txt, может быть более чем достаточно. Однако, если вы хотите больше контроля и возможность добавлять свои собственные правила, чтобы дать более конкретные инструкции роботам поисковых систем о том, как индексировать ваш веб-сайт, вам нужно будет создать свой собственный физический файл robots.txt и поместить его в корень. каталог вашей установки.
Есть несколько причин, по которым может потребоваться перенастроить файл robots.txt и определить, что именно этим ботам будет разрешено сканировать. Одна из основных причин связана со временем, затрачиваемым ботом на сканирование вашего сайта. Google (и другие) не позволяют ботам проводить неограниченное время на каждом веб-сайте… с триллионами страниц им приходится применять более тонкий подход к тому, что их боты будут сканировать, а что проигнорируют в попытке извлечь наиболее полезную информацию. о веб-сайте.

Разместите свой сайт с Pressidium
60- ДНЕВНАЯ ГАРАНТИЯ ВОЗВРАТА ДЕНЕГ
Когда вы разрешаете ботам сканировать все страницы вашего веб-сайта, часть времени сканирования тратится на страницы, которые не являются важными или даже релевантными. Это оставляет им меньше времени, чтобы проработать наиболее важные области вашего сайта. Запрещая ботам доступ к некоторым частям вашего веб-сайта, вы увеличиваете время, доступное ботам для извлечения информации из наиболее важных частей вашего сайта (которые, как мы надеемся, в конечном итоге будут проиндексированы). Поскольку сканирование выполняется быстрее, Google с большей вероятностью повторно посетит ваш веб-сайт и обновит индекс вашего сайта. Это означает, что новые сообщения в блогах и другой свежий контент, скорее всего, будут индексироваться быстрее, что является хорошей новостью.
Примеры редактирования robots.txt
robots.txt предлагает много возможностей для настройки. Поэтому мы предоставили ряд примеров правил, которые можно использовать для определения того, как боты будут индексировать ваш сайт.
Разрешение или запрещение ботов
Во-первых, давайте посмотрим, как мы можем ограничить конкретного бота. Для этого все, что нам нужно сделать, это заменить звездочку (*) на имя пользовательского агента бота, который мы хотим заблокировать, например «MSNBot». Полный список известных пользовательских агентов доступен здесь.
User-agent: MSNBot Disallow: /Прочерк во второй строке ограничит доступ бота ко всем каталогам.
Чтобы позволить только одному боту сканировать наш сайт, мы будем использовать двухэтапный процесс. Сначала мы установили этого бота как исключение, а затем запретили всем ботам, например:
User-agent: Google Disallow: User-agent: * Disallow: /Чтобы разрешить доступ всем ботам ко всему контенту, мы добавляем эти две строки:
User-agent: * Disallow:Тот же эффект можно получить, просто создав файл robots.txt и оставив его пустым.
Блокировка доступа к определенным файлам
Хотите запретить ботам индексировать определенные файлы на вашем сайте? Это просто! В приведенном ниже примере мы запретили поисковым системам доступ ко всем файлам .pdf на нашем веб-сайте.
User-agent: * Disallow: /*.pdf$Символ «$» используется для обозначения конца URL-адреса. Поскольку это чувствительно к регистру, файл с именем my.PDF все равно будет просканирован (обратите внимание на CAPS).
Сложные логические выражения
Некоторые поисковые системы, такие как Google, понимают использование более сложных регулярных выражений. Однако важно отметить, что не все поисковые системы могут понимать логические выражения в файле robots.txt.

Одним из примеров этого является использование символа $. В файлах robots.txt этот символ указывает на конец URL-адреса. Итак, в следующем примере мы заблокировали поисковым ботам чтение и индексацию файлов, оканчивающихся на .php.
Disallow: /*.php$Это означает, что /index.php не может быть проиндексирован, но /index.php?p=1 может быть. Это полезно только в очень специфических обстоятельствах и должно использоваться с осторожностью, иначе вы рискуете заблокировать доступ бота к файлам, которые вы не хотели!
Вы также можете установить разные правила для каждого бота, указав правила, которые применяются к ним индивидуально. Приведенный ниже пример кода ограничит доступ к папке wp-admin для всех ботов и в то же время заблокирует доступ ко всему сайту для поисковой системы Bing. Вы не обязательно захотите это сделать, но это полезная демонстрация того, насколько гибкими могут быть правила в файле robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /XML-карты сайта
XML-карты сайта действительно помогают поисковым роботам понять структуру вашего сайта. Но чтобы быть полезным, боту нужно знать, где находится карта сайта. «Директива карты сайта» используется для того, чтобы сообщить поисковым системам, что а) карта вашего сайта существует и б) где ее можно найти.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:Вы также можете указать несколько местоположений карты сайта:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowЗадержки сканирования ботов
Еще одна функция, которую можно реализовать с помощью файла robots.txt, — это указание ботам «замедлить» сканирование вашего сайта. Это может быть необходимо, если вы обнаружите, что ваш сервер перегружен высоким уровнем трафика ботов. Для этого вы должны указать пользовательский агент, который вы хотите замедлить, а затем добавить задержку.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10Цифра в кавычках (10) в этом примере — это задержка, которую вы хотите получить между сканированием отдельных страниц на вашем сайте. Итак, в приведенном выше примере мы попросили Bing Bot делать паузу в десять секунд между каждой страницей, которую он сканирует, тем самым давая нашему серверу немного передышки.
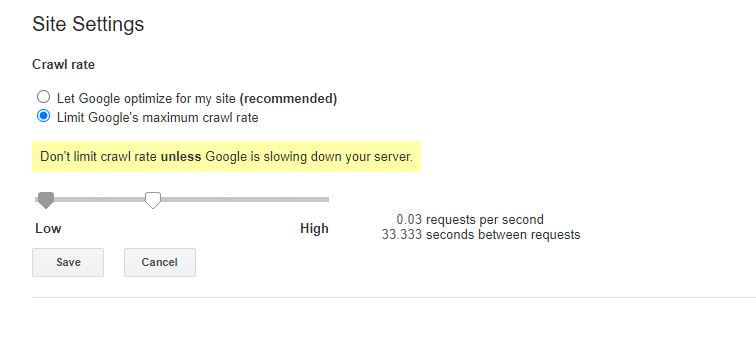
Единственная плохая новость об этом конкретном правиле robots.txt заключается в том, что бот Google его не соблюдает. Однако вы можете приказать их ботам замедлить работу из консоли поиска Google.
Примечания к правилам robots.txt:
- Все правила robots.txt чувствительны к регистру. Введите внимательно!
- Убедитесь, что перед командой в начале строки нет пробелов.
- Изменения, внесенные в robots.txt, могут занять 24-36 часов, прежде чем боты их заметят.
Как протестировать и отправить файл WordPress robots.txt
Когда вы создали новый файл robots.txt, стоит проверить, нет ли в нем ошибок. Вы можете сделать это с помощью Google Search Console.
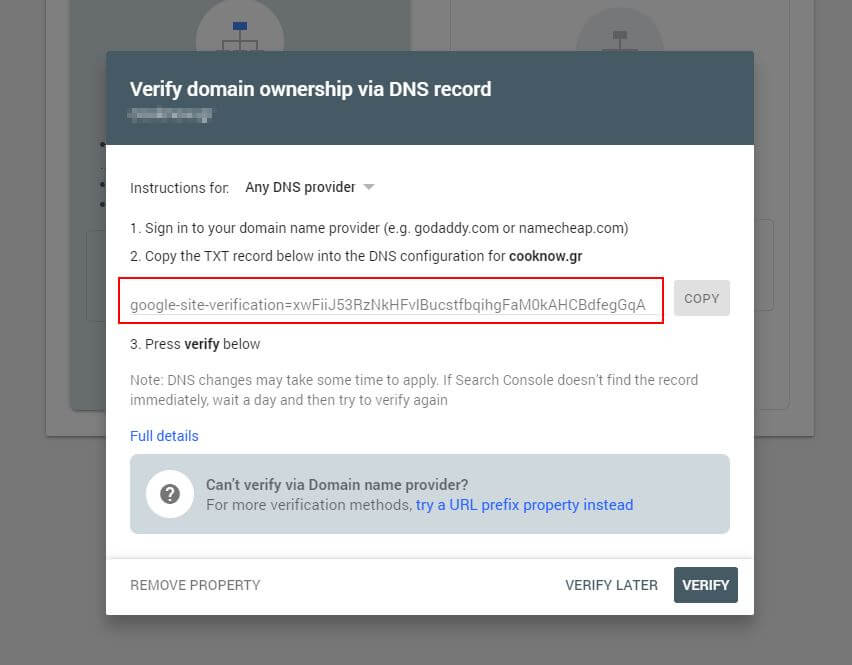
Во-первых, вам нужно будет указать свой домен (если у вас еще нет учетной записи Search Console для настройки веб-сайта). Google предоставит вам запись TXT, которую необходимо добавить в ваш DNS, чтобы подтвердить ваш домен.
Как только это обновление DNS будет распространено (чувство нетерпения… попробуйте использовать Cloudflare для управления вашим DNS), вы можете посетить тестер robots.txt и проверить, есть ли какие-либо предупреждения о содержимом вашего файла robots.txt.
Еще одна вещь, которую вы можете сделать, чтобы проверить, имеют ли ваши правила желаемый эффект, — это использовать инструмент тестирования robots.txt, такой как Ryte.
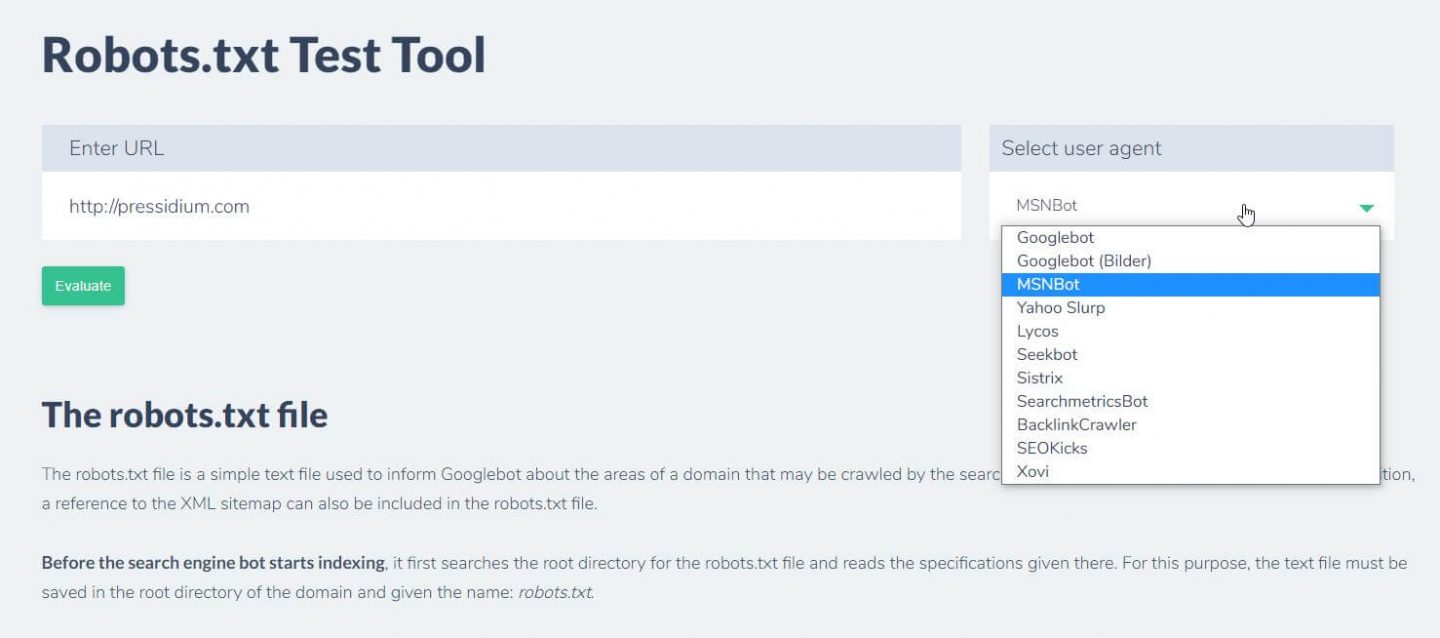
Вы просто вводите свой домен и выбираете пользовательский агент на панели справа. После отправки вы увидите свои результаты.
Вывод
Знание того, как использовать robots.txt, — еще один полезный инструмент в вашем наборе инструментов разработчика. Если единственное, что вы вынесете из этого руководства, — это возможность проверить, что ваш файл robots.txt не блокирует ботов, таких как Google (что вам вряд ли захочется делать), то это неплохо! Точно так же, как вы можете видеть, robots.txt предлагает целый ряд дополнительных средств контроля над вашим веб-сайтом, которые могут однажды пригодиться.