
วิธีสร้างฐานข้อมูล MongoDB: 6 ประเด็นสำคัญที่ต้องรู้
เผยแพร่แล้ว: 2022-11-07ขึ้นอยู่กับข้อกำหนดสำหรับซอฟต์แวร์ของคุณ คุณอาจจัดลำดับความสำคัญของความยืดหยุ่น ความสามารถในการปรับขนาด ประสิทธิภาพ หรือความเร็ว ดังนั้นนักพัฒนาซอฟต์แวร์และธุรกิจจึงมักสับสนขณะเลือกฐานข้อมูลตามความต้องการ หากคุณต้องการฐานข้อมูลที่มีความยืดหยุ่นสูงและปรับขยายได้ และการรวบรวมข้อมูลสำหรับการวิเคราะห์ลูกค้า MongoDB อาจเหมาะสำหรับคุณ!
ในบทความนี้ เราจะพูดถึงโครงสร้างของฐานข้อมูล MongoDB และวิธีการสร้าง ตรวจสอบ และจัดการฐานข้อมูลของคุณ! มาเริ่มกันเลย.
โครงสร้างฐานข้อมูล MongoDB เป็นอย่างไร?
MongoDB เป็นฐานข้อมูล NoSQL ที่ไม่มีสคีมา ซึ่งหมายความว่าคุณไม่ได้ระบุโครงสร้างสำหรับตาราง/ฐานข้อมูลเหมือนกับที่คุณทำกับฐานข้อมูล SQL
คุณรู้หรือไม่ว่าฐานข้อมูล NoSQL นั้นเร็วกว่าฐานข้อมูลเชิงสัมพันธ์จริง ๆ ? ทั้งนี้เนื่องมาจากคุณลักษณะต่างๆ เช่น การสร้างดัชนี การแบ่งส่วนข้อมูล และไปป์ไลน์การรวม MongoDB เป็นที่รู้จักสำหรับการดำเนินการค้นหาที่รวดเร็ว นี่คือเหตุผลที่บริษัทต่างๆ เช่น Google, Toyota และ Forbes เป็นที่ต้องการ
ด้านล่างนี้ เราจะสำรวจลักษณะสำคัญบางประการของ MongoDB
เอกสาร
MongoDB มีโมเดลข้อมูลเอกสารที่เก็บข้อมูลเป็นเอกสาร JSON เอกสารจะจับคู่กับออบเจ็กต์ในโค้ดของแอปพลิเคชันอย่างเป็นธรรมชาติ ทำให้นักพัฒนาใช้งานได้ง่ายยิ่งขึ้น
ในตารางฐานข้อมูลเชิงสัมพันธ์ คุณต้องเพิ่มคอลัมน์เพื่อเพิ่มฟิลด์ใหม่ นั่นไม่ใช่กรณีที่มีฟิลด์ในเอกสาร JSON ช่องในเอกสาร JSON อาจแตกต่างกันไปในแต่ละเอกสาร ดังนั้นจึงไม่เพิ่มลงในทุกระเบียนในฐานข้อมูล
เอกสารสามารถจัดเก็บโครงสร้างเช่นอาร์เรย์ที่สามารถซ้อนเพื่อแสดงความสัมพันธ์แบบลำดับชั้นได้ นอกจากนี้ MongoDB ยังแปลงเอกสารเป็นประเภทไบนารี JSON (BSON) ซึ่งช่วยให้เข้าถึงได้เร็วขึ้นและรองรับข้อมูลประเภทต่างๆ ได้มากขึ้น เช่น สตริง จำนวนเต็ม หมายเลขบูลีน และอื่นๆ อีกมากมาย!
ชุดจำลอง
เมื่อคุณสร้างฐานข้อมูลใหม่ใน MongoDB ระบบจะสร้างสำเนาข้อมูลของคุณอีกอย่างน้อย 2 ชุดโดยอัตโนมัติ สำเนาเหล่านี้เรียกว่า "ชุดแบบจำลอง" และจะทำซ้ำข้อมูลระหว่างกันอย่างต่อเนื่อง เพื่อให้มั่นใจว่าข้อมูลของคุณจะพร้อมใช้งานได้ดีขึ้น พวกเขายังให้การป้องกันการหยุดทำงานระหว่างความล้มเหลวของระบบหรือการบำรุงรักษาตามแผน
ของสะสม
คอลเลกชันคือกลุ่มของเอกสารที่เกี่ยวข้องกับฐานข้อมูลเดียว คล้ายกับตารางในฐานข้อมูลเชิงสัมพันธ์
อย่างไรก็ตาม คอลเล็กชันมีความยืดหยุ่นมากกว่ามาก ประการหนึ่ง พวกเขาไม่พึ่งพาสคีมา ประการที่สอง เอกสารไม่จำเป็นต้องเป็นประเภทข้อมูลเดียวกัน!
หากต้องการดูรายการคอลเล็กชันที่เป็นของฐานข้อมูล ให้ใช้คำสั่ง listCollections
ท่อรวม
คุณสามารถใช้เฟรมเวิร์กนี้เพื่อรวมโอเปอเรเตอร์และนิพจน์ต่างๆ เข้าด้วยกัน มีความยืดหยุ่นเพราะช่วยให้คุณสามารถประมวลผล แปลง และวิเคราะห์ข้อมูลของโครงสร้างใดก็ได้
ด้วยเหตุนี้ MongoDB จึงมีกระแสข้อมูลและฟีเจอร์ที่รวดเร็วในโอเปอเรเตอร์และนิพจน์ 150 ตัว นอกจากนี้ยังมีหลายขั้นตอน เช่น เวที Union ซึ่งรวบรวมผลลัพธ์จากหลายคอลเลกชันได้อย่างยืดหยุ่น
ดัชนี
คุณสามารถจัดทำดัชนีฟิลด์ใดก็ได้ในเอกสาร MongoDB เพื่อเพิ่มประสิทธิภาพและปรับปรุงความเร็วในการสืบค้น การทำดัชนีช่วยประหยัดเวลาโดยการสแกนดัชนีเพื่อจำกัดเอกสารที่ตรวจสอบ มันจะดีกว่าการอ่านเอกสารทุกฉบับในคอลเล็กชันหรือไม่?
คุณสามารถใช้กลยุทธ์การทำดัชนีต่างๆ รวมถึงดัชนีผสมในหลายฟิลด์ ตัวอย่างเช่น สมมติว่าคุณมีเอกสารหลายฉบับที่มีชื่อและนามสกุลของพนักงานในช่องที่แยกจากกัน หากคุณต้องการส่งคืนชื่อและนามสกุล คุณสามารถสร้างดัชนีที่มีทั้ง "นามสกุล" และ "ชื่อ" สิ่งนี้จะดีกว่าการมีดัชนีหนึ่งรายการใน “นามสกุล” และดัชนีอีกรายการหนึ่งบน “ชื่อ”
คุณสามารถใช้ประโยชน์จากเครื่องมือต่างๆ เช่น Performance Advisor เพื่อทำความเข้าใจเพิ่มเติมว่าการสืบค้นใดจะได้รับประโยชน์จากดัชนี
ชาร์ดิง
Sharding กระจายชุดข้อมูลเดียวในหลายฐานข้อมูล จากนั้นชุดข้อมูลดังกล่าวสามารถจัดเก็บไว้บนเครื่องหลายเครื่องเพื่อเพิ่มความจุในการจัดเก็บข้อมูลทั้งหมดของระบบ เนื่องจากจะแยกชุดข้อมูลขนาดใหญ่ออกเป็นชิ้นเล็กๆ และจัดเก็บไว้ในโหนดข้อมูลต่างๆ
MongoDB ชาร์ดข้อมูลในระดับคอลเล็กชัน แจกจ่ายเอกสารในคอลเล็กชันข้ามชาร์ดในคลัสเตอร์ สิ่งนี้ทำให้มั่นใจได้ถึงความสามารถในการปรับขนาดโดยอนุญาตให้สถาปัตยกรรมจัดการกับแอพพลิเคชั่นที่ใหญ่ที่สุด
วิธีสร้างฐานข้อมูล MongoDB
คุณจะต้องติดตั้งแพ็คเกจ MongoDB ที่เหมาะสมกับระบบปฏิบัติการของคุณก่อน ไปที่หน้า 'ดาวน์โหลด MongoDB Community Server' จากตัวเลือกที่มี ให้เลือกรูปแบบ "เวอร์ชัน", "แพ็คเกจ" ล่าสุดเป็นไฟล์ zip และ "แพลตฟอร์ม" เป็นระบบปฏิบัติการของคุณ แล้วคลิก "ดาวน์โหลด" ตามที่แสดงด้านล่าง:
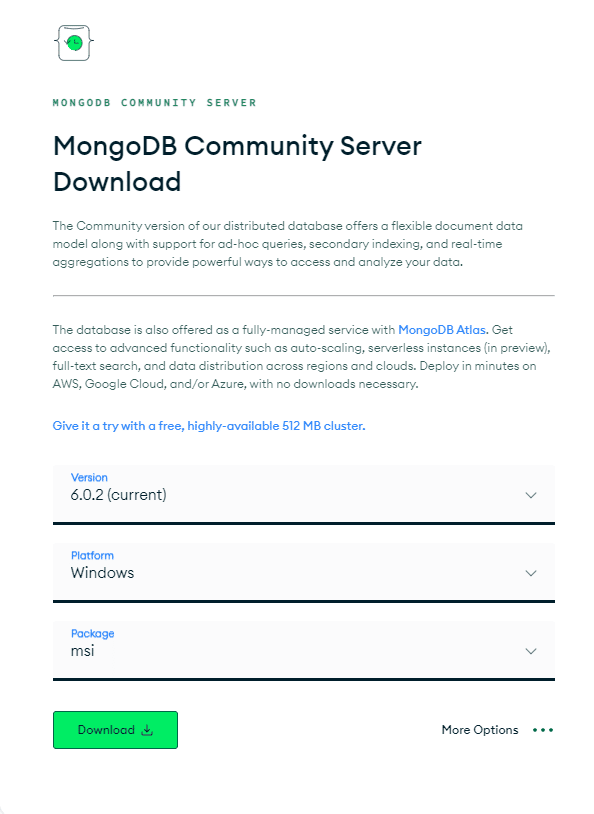
กระบวนการนี้ค่อนข้างตรงไปตรงมา ดังนั้น คุณจะมี MongoDB ติดตั้งในระบบของคุณในเวลาไม่นาน!
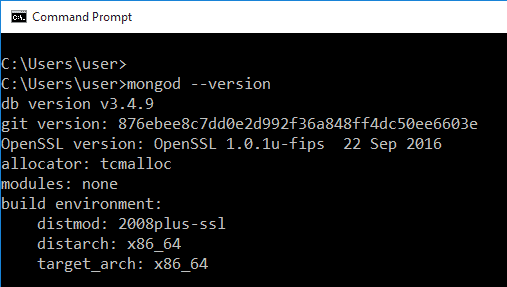
เมื่อคุณติดตั้งเสร็จแล้ว ให้เปิดพรอมต์คำสั่งแล้วพิมพ์ mongod -version เพื่อยืนยัน หากคุณไม่ได้รับผลลัพธ์ต่อไปนี้ แต่เห็นสตริงข้อผิดพลาด คุณอาจต้องติดตั้งใหม่:
การใช้ MongoDB Shell
ก่อนที่เราจะเริ่มต้น ตรวจสอบให้แน่ใจว่า:
- ลูกค้าของคุณมี Transport Layer Security และอยู่ในรายการที่อนุญาต IP ของคุณ
- คุณมีบัญชีผู้ใช้และรหัสผ่านบนคลัสเตอร์ MongoDB ที่ต้องการ
- คุณได้ติดตั้ง MongoDB บนอุปกรณ์ของคุณแล้ว
ขั้นตอนที่ 1: เข้าถึง MongoDB Shell
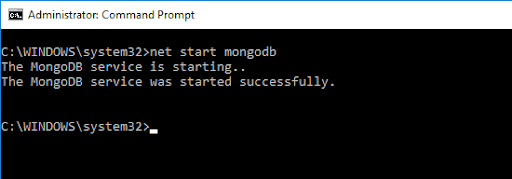
ในการเข้าถึงเชลล์ MongoDB ให้พิมพ์คำสั่งต่อไปนี้:
net start MongoDBสิ่งนี้ควรให้ผลลัพธ์ต่อไปนี้:
คำสั่งก่อนหน้านี้เริ่มต้นเซิร์ฟเวอร์ MongoDB ในการใช้งาน เราต้องพิมพ์ mongo ใน command prompt
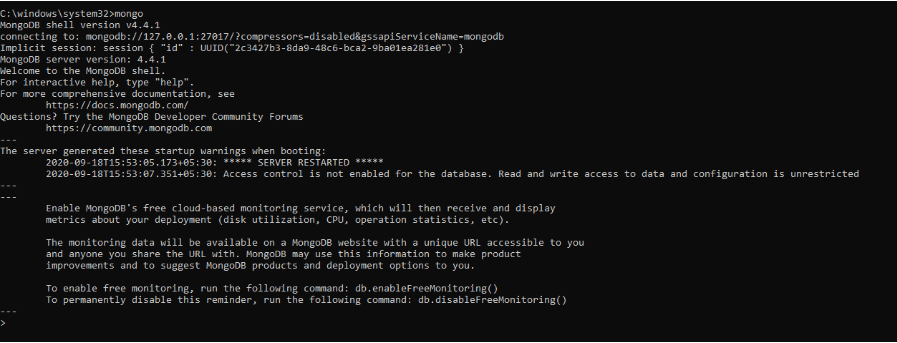
ในเชลล์ MongoDB เราสามารถรันคำสั่งเพื่อสร้างฐานข้อมูล แทรกข้อมูล แก้ไขข้อมูล ออกคำสั่งการดูแลระบบ และลบข้อมูล
ขั้นตอนที่ 2: สร้างฐานข้อมูลของคุณ
MongoDB ไม่มีคำสั่งสร้างฐานข้อมูลต่างจาก SQL แต่มีคีย์เวิร์ดที่เรียกว่า use ซึ่งสลับไปยังฐานข้อมูลที่ระบุ ถ้าไม่มีฐานข้อมูล จะเป็นการสร้างฐานข้อมูลใหม่ มิฉะนั้น จะลิงก์ไปยังฐานข้อมูลที่มีอยู่
ตัวอย่างเช่น เมื่อต้องการเริ่มต้นฐานข้อมูลที่เรียกว่า "บริษัท" ให้พิมพ์:
use Company 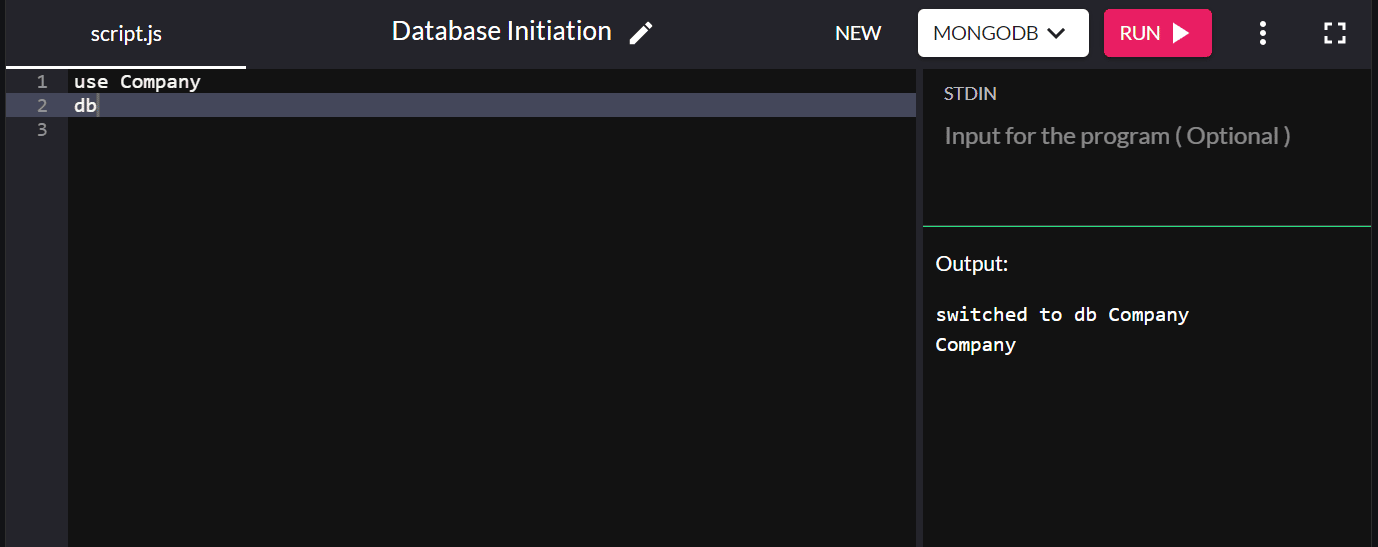
คุณสามารถพิมพ์ db เพื่อยืนยันฐานข้อมูลที่คุณเพิ่งสร้างในระบบของคุณ หากฐานข้อมูลใหม่ที่คุณสร้างขึ้นปรากฏขึ้น แสดงว่าคุณเชื่อมต่อสำเร็จแล้ว
หากคุณต้องการตรวจสอบฐานข้อมูลที่มีอยู่ ให้พิมพ์ show dbs แล้วระบบจะคืนค่าฐานข้อมูลทั้งหมดในระบบของคุณ:
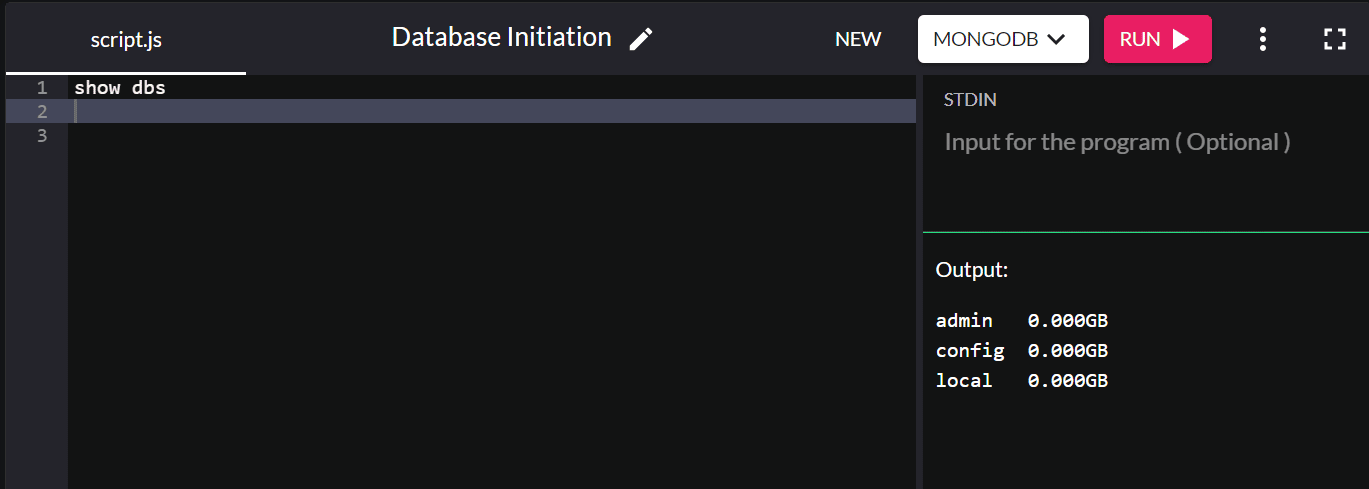
ตามค่าเริ่มต้น การติดตั้ง MongoDB จะสร้างฐานข้อมูลผู้ดูแลระบบ การกำหนดค่า และฐานข้อมูลในเครื่อง
คุณสังเกตเห็นว่าฐานข้อมูลที่เราสร้างไม่ปรากฏขึ้นหรือไม่ เนื่องจากเรายังไม่ได้บันทึกค่าลงในฐานข้อมูล! เราจะพูดถึงการแทรกภายใต้ส่วนการจัดการฐานข้อมูล
การใช้ Atlas UI
คุณสามารถเริ่มต้นใช้งาน Atlas บริการฐานข้อมูลของ MongoDB แม้ว่าคุณอาจต้องจ่ายเงินเพื่อเข้าถึงคุณลักษณะบางอย่างของ Atlas แต่ฟังก์ชันฐานข้อมูลส่วนใหญ่จะมีให้ในรุ่นฟรี คุณสมบัติของ Free Tier นั้นมากเกินพอที่จะสร้างฐานข้อมูล MongoDB
ก่อนที่เราจะเริ่มต้น ตรวจสอบให้แน่ใจว่า:
- IP ของคุณอยู่ในรายการที่อนุญาต
- คุณมีบัญชีผู้ใช้และรหัสผ่านบนคลัสเตอร์ MongoDB ที่คุณต้องการใช้
ในการสร้างฐานข้อมูล MongoDB ด้วย AtlasUI ให้เปิดหน้าต่างเบราว์เซอร์และลงชื่อเข้าใช้ https://cloud.mongodb.com จากเพจคลัสเตอร์ของคุณ คลิก Browse Collections หากไม่มีฐานข้อมูลในคลัสเตอร์ คุณสามารถสร้างฐานข้อมูลของคุณได้โดยคลิกที่ปุ่ม เพิ่มข้อมูลของฉันเอง
พร้อมท์จะขอให้คุณระบุฐานข้อมูลและชื่อคอลเลกชัน เมื่อคุณตั้งชื่อแล้ว ให้คลิก สร้าง เท่านี้ก็เรียบร้อย! ตอนนี้คุณสามารถป้อนเอกสารใหม่หรือเชื่อมต่อกับฐานข้อมูลโดยใช้ไดรเวอร์
การจัดการฐานข้อมูล MongoDB ของคุณ
ในส่วนนี้ เราจะพูดถึงวิธีที่ดีสองสามวิธีในการจัดการฐานข้อมูล MongoDB ของคุณอย่างมีประสิทธิภาพ คุณสามารถทำได้โดยใช้ MongoDB Compass หรือผ่านคอลเล็กชัน
การใช้คอลเลกชัน
ในขณะที่ฐานข้อมูลเชิงสัมพันธ์มีตารางที่กำหนดไว้อย่างดีพร้อมประเภทข้อมูลและคอลัมน์ที่ระบุ NoSQL มีคอลเลกชันแทนที่จะเป็นตาราง คอลเลกชันเหล่านี้ไม่มีโครงสร้างใดๆ และเอกสารสามารถเปลี่ยนแปลงได้ คุณสามารถมีชนิดข้อมูลและฟิลด์ที่แตกต่างกันโดยไม่ต้องจับคู่รูปแบบของเอกสารอื่นในคอลเลกชันเดียวกัน
สาธิตให้สร้างคอลเลกชันที่เรียกว่า "พนักงาน" และเพิ่มเอกสารเข้าไป:
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) หากการแทรกสำเร็จ มันจะส่งคืน WriteResult({ "nInserted" : 1 }) :
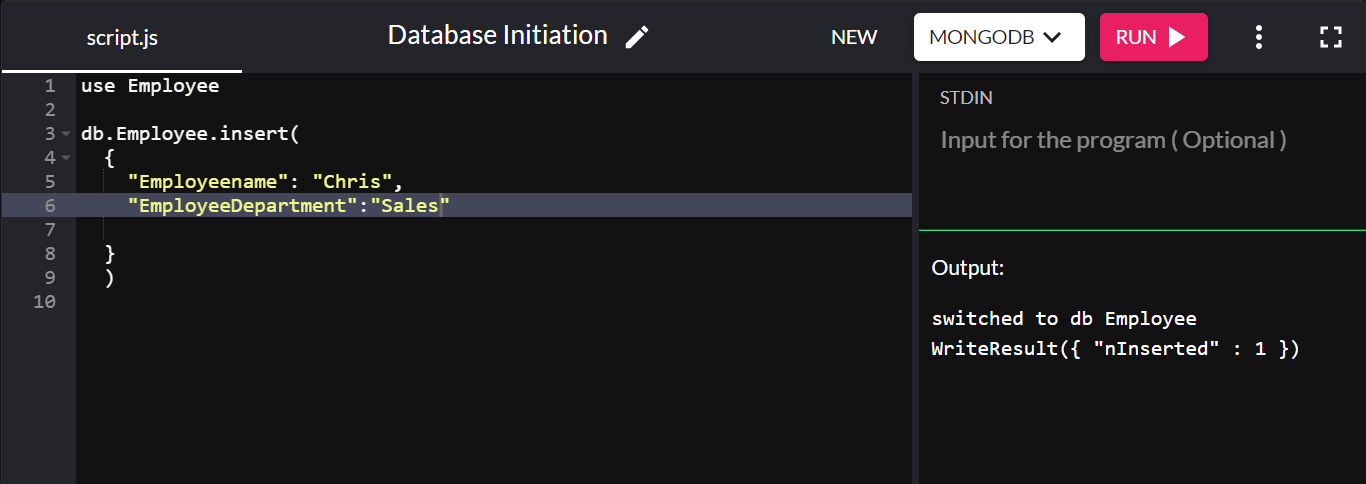
ในที่นี้ “db” หมายถึงฐานข้อมูลที่เชื่อมต่ออยู่ในปัจจุบัน “พนักงาน” คือคอลเล็กชันที่สร้างขึ้นใหม่บนฐานข้อมูลของบริษัท
เรายังไม่ได้ตั้งค่าคีย์หลักที่นี่ เนื่องจาก MongoDB จะสร้างฟิลด์คีย์หลักที่เรียกว่า “_id” โดยอัตโนมัติ และตั้งค่าเริ่มต้นเป็นฟิลด์คีย์หลัก
เรียกใช้คำสั่งด้านล่างเพื่อตรวจสอบคอลเลกชันในรูปแบบ JSON:
db.Employee.find().forEach(printjson)เอาท์พุท:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }ในขณะที่ค่า “_id” ถูกกำหนดโดยอัตโนมัติ คุณสามารถเปลี่ยนค่าของคีย์หลักเริ่มต้นได้ คราวนี้ เราจะแทรกเอกสารอื่นลงในฐานข้อมูล "พนักงาน" โดยมีค่า "_id" เป็น "1":
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) ในการรันคำสั่ง db.Employee.find().forEach(printjson) เราได้ผลลัพธ์ต่อไปนี้:
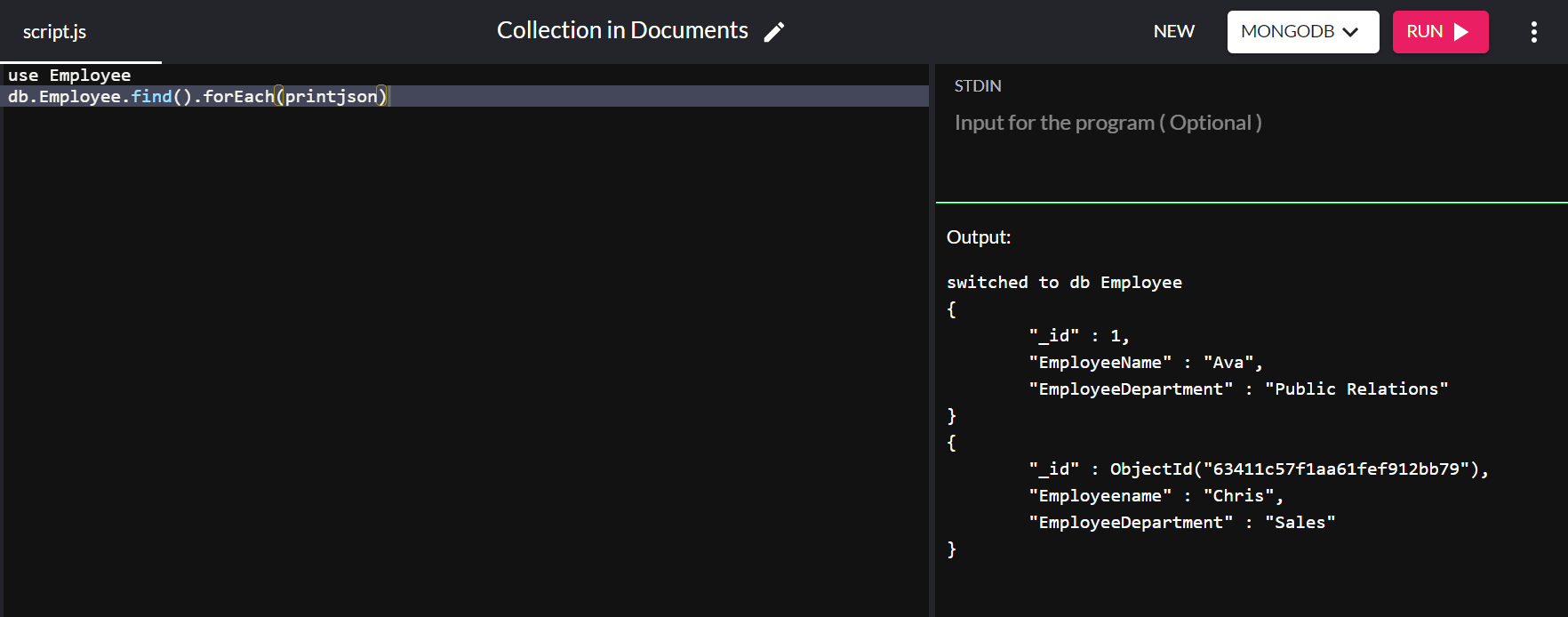
ในผลลัพธ์ข้างต้น ค่า "_id" สำหรับ "Ava" ถูกตั้งค่าเป็น "1" แทนที่จะกำหนดค่าโดยอัตโนมัติ
ตอนนี้เราได้เพิ่มค่าลงในฐานข้อมูลเรียบร้อยแล้ว เราสามารถตรวจสอบว่าค่าดังกล่าวปรากฏขึ้นภายใต้ฐานข้อมูลที่มีอยู่ในระบบของเราหรือไม่โดยใช้คำสั่งต่อไปนี้:
show dbs 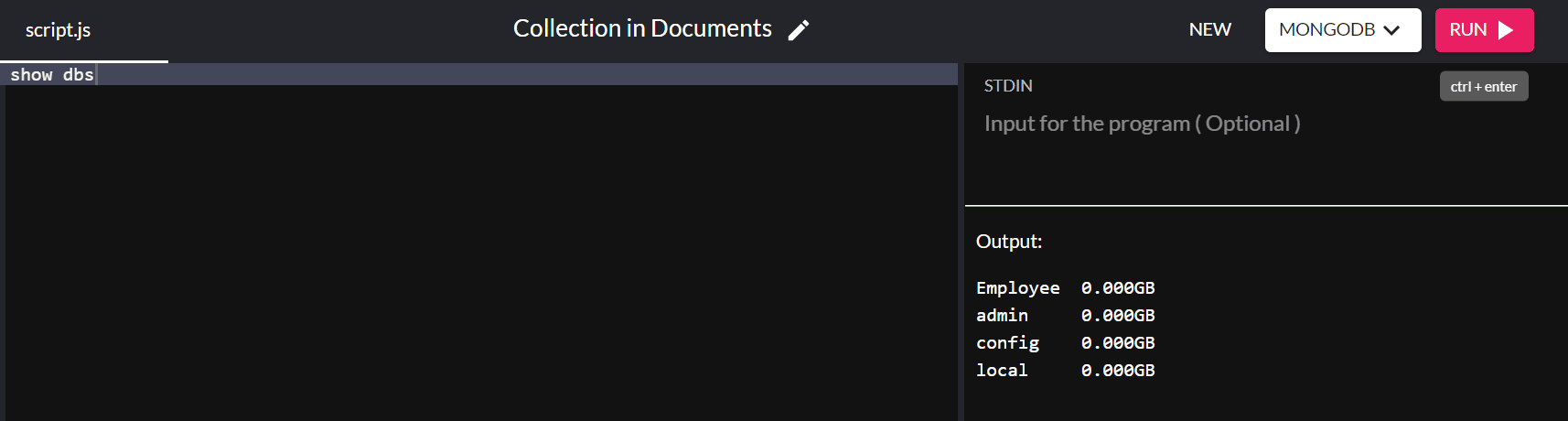
และโว้ว! คุณได้สร้างฐานข้อมูลในระบบของคุณสำเร็จแล้ว!
การใช้เข็มทิศ MongoDB
แม้ว่าเราจะสามารถทำงานกับเซิร์ฟเวอร์ MongoDB จากเชลล์ Mongo ได้ แต่บางครั้งมันก็น่าเบื่อหน่าย คุณอาจประสบปัญหานี้ในสภาพแวดล้อมการผลิต
อย่างไรก็ตาม มีเครื่องมือเข็มทิศ (ชื่อที่เหมาะสมว่า Compass) ที่สร้างโดย MongoDB ที่สามารถทำให้ง่ายขึ้นได้ มี GUI ที่ดีขึ้นและฟังก์ชันเพิ่มเติม เช่น การสร้างภาพข้อมูล การทำโปรไฟล์ประสิทธิภาพ และการเข้าถึง CRUD (สร้าง อ่าน อัปเดต ลบ) ข้อมูล ฐานข้อมูล และคอลเล็กชัน
คุณสามารถดาวน์โหลด Compass IDE สำหรับระบบปฏิบัติการของคุณและติดตั้งด้วยกระบวนการที่ตรงไปตรงมา
ถัดไป เปิดแอปพลิเคชันและสร้างการเชื่อมต่อกับเซิร์ฟเวอร์โดยวางสตริงการเชื่อมต่อ หากไม่พบ คุณสามารถคลิก กรอกข้อมูลในฟิลด์การเชื่อมต่อทีละ รายการ หากคุณไม่ได้เปลี่ยนหมายเลขพอร์ตขณะติดตั้ง MongoDB เพียงคลิกปุ่มเชื่อมต่อ เท่านี้ก็เรียบร้อย! มิฉะนั้น เพียงป้อนค่าที่คุณตั้งไว้และคลิก เชื่อมต่อ
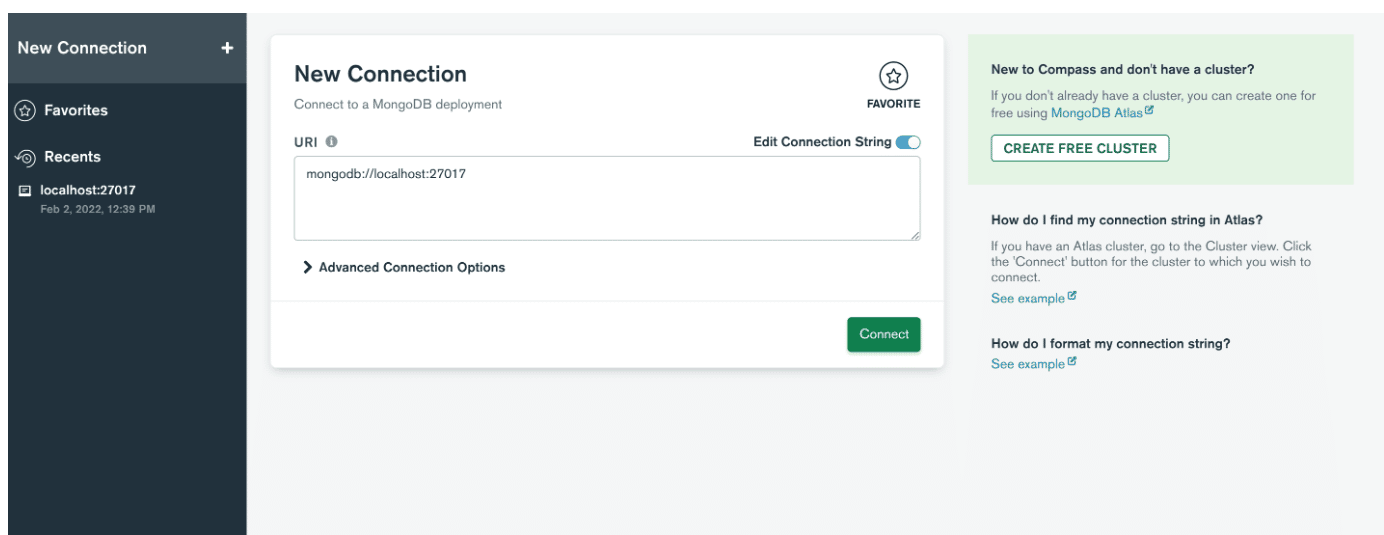
ถัดไป ระบุชื่อโฮสต์ พอร์ต และการตรวจสอบสิทธิ์ในหน้าต่างการเชื่อมต่อใหม่
ใน MongoDB Compass คุณสามารถสร้างฐานข้อมูลและเพิ่มคอลเล็กชันแรกพร้อมกันได้ นี่คือวิธีการ:
- คลิก สร้างฐานข้อมูล เพื่อเปิดพร้อมท์
- ป้อนชื่อฐานข้อมูลและคอลเล็กชันแรก
- คลิก สร้างฐานข้อมูล
คุณสามารถแทรกเอกสารเพิ่มเติมลงในฐานข้อมูลของคุณโดยคลิกที่ชื่อฐานข้อมูลของคุณ จากนั้นคลิกที่ชื่อคอลเลกชันเพื่อดูแท็บ เอกสาร จากนั้น คุณสามารถคลิกปุ่ม เพิ่มข้อมูล เพื่อแทรกเอกสารอย่างน้อยหนึ่งเอกสารลงในคอลเลกชั่นของคุณ
ขณะเพิ่มเอกสาร คุณสามารถป้อนทีละรายการหรือหลายเอกสารในอาร์เรย์ได้ หากคุณกำลังเพิ่มเอกสารหลายฉบับ ตรวจสอบให้แน่ใจว่าเอกสารที่คั่นด้วยเครื่องหมายจุลภาคเหล่านี้อยู่ในวงเล็บเหลี่ยม ตัวอย่างเช่น:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }สุดท้าย คลิก แทรก เพื่อเพิ่มเอกสารในคอลเลกชันของคุณ เนื้อหาของเอกสารจะมีลักษณะดังนี้:
{ "StudentID" : 1 "StudentName" : "JohnDoe" }ในที่นี้ ชื่อฟิลด์คือ “StudentID” และ “StudentName” ค่าของฟิลด์คือ “1” และ “JohnDoe” ตามลำดับ
คำสั่งที่เป็นประโยชน์
คุณสามารถจัดการคอลเลกชันเหล่านี้ผ่านการจัดการบทบาทและคำสั่งการจัดการผู้ใช้
คำสั่งการจัดการผู้ใช้
คำสั่งการจัดการผู้ใช้ MongoDB มีคำสั่งที่เกี่ยวข้องกับผู้ใช้ เราสามารถสร้าง อัปเดต และลบผู้ใช้โดยใช้คำสั่งเหล่านี้
dropUser
คำสั่งนี้ลบผู้ใช้รายเดียวออกจากฐานข้อมูลที่ระบุ ด้านล่างเป็นไวยากรณ์:
db.dropUser(username, writeConcern) ที่นี่ username เป็นฟิลด์บังคับที่มีเอกสารที่มีการรับรองความถูกต้องและการเข้าถึงข้อมูลเกี่ยวกับผู้ใช้ ฟิลด์ตัวเลือก writeConcern มีระดับของข้อกังวลในการเขียนสำหรับการดำเนินการสร้าง ระดับของข้อกังวลในการเขียนสามารถกำหนดได้โดยฟิลด์ตัวเลือก writeConcern
ก่อนปล่อยผู้ใช้ที่มีบทบาท userAdminAnyDatabase ตรวจสอบให้แน่ใจว่ามีผู้ใช้อื่นอย่างน้อยหนึ่งรายที่มีสิทธิ์การดูแลระบบผู้ใช้
ในตัวอย่างนี้ เราจะปล่อยผู้ใช้ “user26” ในฐานข้อมูลทดสอบ:
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})เอาท์พุท:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); truecreateUser
คำสั่งนี้สร้างผู้ใช้ใหม่สำหรับฐานข้อมูลที่ระบุดังนี้:
db.createUser(user, writeConcern) ที่นี่ user เป็นฟิลด์บังคับที่มีเอกสารที่มีการรับรองความถูกต้องและเข้าถึงข้อมูลเกี่ยวกับผู้ใช้ที่จะสร้าง ฟิลด์ตัวเลือก writeConcern มีระดับของข้อกังวลในการเขียนสำหรับการดำเนินการสร้าง ระดับของข้อกังวลในการเขียนสามารถกำหนดได้โดยฟิลด์ทางเลือก writeConcern
createUser จะส่งคืนข้อผิดพลาดของผู้ใช้ที่ซ้ำกัน หากผู้ใช้มีอยู่แล้วในฐานข้อมูล
คุณสามารถสร้างผู้ใช้ใหม่ในฐานข้อมูลทดสอบได้ดังนี้:
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );ผลลัพธ์จะเป็นดังนี้:
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }GrantRolesToUser
คุณสามารถใช้คำสั่งนี้เพื่อมอบบทบาทเพิ่มเติมให้กับผู้ใช้ ในการใช้งาน คุณต้องคำนึงถึงไวยากรณ์ต่อไปนี้:
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) คุณสามารถระบุทั้งบทบาทที่ผู้ใช้กำหนดและบทบาทในตัวในบทบาทที่กล่าวถึงข้างต้น หากคุณต้องการระบุบทบาทที่มีอยู่ในฐานข้อมูลเดียวกันกับที่ grantRolesToUser ทำงาน คุณสามารถระบุบทบาทด้วยเอกสารดังที่กล่าวไว้ด้านล่าง:
{ role: "<role>", db: "<database>" }หรือคุณสามารถระบุบทบาทด้วยชื่อของบทบาทได้ ตัวอย่างเช่น:
"readWrite"ถ้าคุณต้องการระบุบทบาทที่มีอยู่ในฐานข้อมูลอื่น คุณจะต้องระบุบทบาทด้วยเอกสารอื่น
ในการมอบบทบาทบนฐานข้อมูล คุณต้องมีการดำเนินการ grantRole บนฐานข้อมูลที่ระบุ
นี่คือตัวอย่างเพื่อให้คุณเห็นภาพที่ชัดเจน ยกตัวอย่างผู้ใช้ productUser00 ในฐานข้อมูลผลิตภัณฑ์ที่มีบทบาทต่อไปนี้:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] การดำเนินการ grantRolesToUser ให้ “productUser00” มีบทบาท readWrite บนฐานข้อมูลสต็อคและบทบาทการอ่านบนฐานข้อมูลผลิตภัณฑ์:
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })ผู้ใช้ productUser00 ในฐานข้อมูลผลิตภัณฑ์ตอนนี้มีบทบาทต่อไปนี้:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]ข้อมูลผู้ใช้
คุณสามารถใช้คำสั่ง usersInfo เพื่อส่งคืนข้อมูลเกี่ยวกับผู้ใช้ตั้งแต่หนึ่งรายขึ้นไป นี่คือไวยากรณ์:
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } ในแง่ของการเข้าถึง ผู้ใช้สามารถดูข้อมูลของตนเองได้ตลอดเวลา ในการดูข้อมูลของผู้ใช้รายอื่น ผู้ใช้ที่รันคำสั่งต้องมีสิทธิ์ที่รวมแอ็คชัน viewUser ในฐานข้อมูลของผู้ใช้รายอื่น
ในการรันคำสั่ง userInfo คุณสามารถรับข้อมูลต่อไปนี้ขึ้นอยู่กับตัวเลือกที่ระบุ:
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } ตอนนี้ คุณมีแนวคิดทั่วไปเกี่ยวกับสิ่งที่คุณสามารถทำได้ด้วยคำสั่ง usersInfo คำถามต่อไปที่อาจปรากฏขึ้นคือ คำสั่งใดจะมีประโยชน์ในการดูผู้ใช้เฉพาะและผู้ใช้หลายราย
ต่อไปนี้คือตัวอย่างที่มีประโยชน์สองตัวอย่างเพื่อแสดงให้เห็นสิ่งเดียวกัน:
หากต้องการดูสิทธิ์และข้อมูลเฉพาะสำหรับผู้ใช้เฉพาะ แต่ไม่ใช่ข้อมูลประจำตัว สำหรับผู้ใช้ "Anthony" ที่กำหนดไว้ในฐานข้อมูล "office" ให้ดำเนินการคำสั่งต่อไปนี้:
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )ถ้าคุณต้องการดูผู้ใช้ในฐานข้อมูลปัจจุบัน คุณสามารถพูดถึงผู้ใช้ตามชื่อเท่านั้น ตัวอย่างเช่น หากคุณอยู่ในฐานข้อมูลหลักและมีผู้ใช้ชื่อ “Timothy” อยู่ในฐานข้อมูลหลัก คุณสามารถเรียกใช้คำสั่งต่อไปนี้:
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) ถัดไป คุณสามารถใช้อาร์เรย์ได้หากต้องการดูข้อมูลสำหรับผู้ใช้ต่างๆ คุณสามารถใส่ฟิลด์ตัวเลือก showCredentials และ showPrivileges หรือเลือกที่จะไม่ใส่ก็ได้ นี่คือลักษณะของคำสั่ง:
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })เพิกถอนบทบาทจากผู้ใช้
คุณสามารถใช้คำสั่ง revokeRolesFromUser เพื่อลบบทบาทตั้งแต่หนึ่งบทบาทขึ้นไปจากผู้ใช้บนฐานข้อมูลที่มีบทบาท คำสั่ง revokeRolesFromUser มีไวยากรณ์ต่อไปนี้:
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) ในไวยากรณ์ที่กล่าวถึงข้างต้น คุณสามารถระบุทั้งบทบาทที่ผู้ใช้กำหนดและบทบาทที่สร้างขึ้นในฟิลด์ roles เช่นเดียวกับคำสั่ง grantRolesToUser คุณสามารถระบุบทบาทที่คุณต้องการเพิกถอนในเอกสารหรือใช้ชื่อได้
หากต้องการดำเนินการคำสั่ง revokeRolesFromUser ให้สำเร็จ คุณต้องมีการดำเนินการ revokeRole บนฐานข้อมูลที่ระบุ
นี่คือตัวอย่างในการขับเคลื่อนจุดกลับบ้าน เอนทิตี productUser00 ในฐานข้อมูลผลิตภัณฑ์มีบทบาทต่อไปนี้:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] คำสั่ง revokeRolesFromUser ต่อไปนี้จะลบบทบาทของผู้ใช้สองบทบาท: บทบาท "อ่าน" จาก products และบทบาท assetsWriter จากฐานข้อมูล "สินทรัพย์":
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )ผู้ใช้ “productUser00” ในฐานข้อมูลผลิตภัณฑ์ตอนนี้มีเพียงบทบาทเดียวที่เหลืออยู่:
"roles" : [ { "role" : "readWrite", "db" : "stock" } ]คำสั่งการจัดการบทบาท
บทบาทอนุญาตให้ผู้ใช้เข้าถึงทรัพยากร ผู้ดูแลระบบสามารถใช้บทบาทในตัวหลายอย่างเพื่อควบคุมการเข้าถึงระบบ MongoDB หากบทบาทไม่ครอบคลุมสิทธิ์ที่ต้องการ คุณยังสามารถดำเนินการต่อไปเพื่อสร้างบทบาทใหม่ในฐานข้อมูลเฉพาะ

dropRole
ด้วยคำสั่ง dropRole คุณสามารถลบบทบาทที่ผู้ใช้กำหนดออกจากฐานข้อมูลที่คุณรันคำสั่ง ในการรันคำสั่งนี้ ให้ใช้ไวยากรณ์ต่อไปนี้:
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) เพื่อให้การดำเนินการสำเร็จ คุณต้องมีการดำเนินการ dropRole บนฐานข้อมูลที่ระบุ การดำเนินการต่อไปนี้จะลบบทบาท writeTags ออกจากฐานข้อมูล "ผลิตภัณฑ์":
use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )createRole
คุณสามารถใช้คำสั่ง createRole เพื่อสร้างบทบาทและระบุสิทธิ์ได้ บทบาทจะนำไปใช้กับฐานข้อมูลที่คุณเลือกเรียกใช้คำสั่ง คำสั่ง createRole จะส่งคืนข้อผิดพลาดของบทบาทที่ซ้ำกัน หากมีบทบาทอยู่แล้วในฐานข้อมูล
ในการรันคำสั่งนี้ ให้ทำตามไวยากรณ์ที่กำหนด:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )สิทธิ์ของบทบาทจะนำไปใช้กับฐานข้อมูลที่สร้างบทบาท บทบาทสามารถสืบทอดสิทธิ์จากบทบาทอื่นในฐานข้อมูลได้ ตัวอย่างเช่น บทบาทที่สร้างขึ้นบนฐานข้อมูล "ผู้ดูแลระบบ" อาจมีสิทธิ์ที่ใช้กับคลัสเตอร์หรือฐานข้อมูลทั้งหมด นอกจากนี้ยังสามารถสืบทอดสิทธิ์จากบทบาทที่มีอยู่ในฐานข้อมูลอื่นๆ
ในการสร้างบทบาทในฐานข้อมูล คุณต้องมีสองสิ่ง:
- การดำเนินการ
grantRoleบนฐานข้อมูลนั้นเพื่อกล่าวถึงสิทธิ์สำหรับบทบาทใหม่รวมถึงการกล่าวถึงบทบาทที่จะสืบทอด - การดำเนินการ
createRoleบนทรัพยากรฐานข้อมูลนั้น
คำสั่ง createRole ต่อไปนี้จะสร้างบทบาทผู้ดูแลระบบ clusterAdmin บนฐานข้อมูลผู้ใช้:
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })GrantRolesToRole
ด้วยคำสั่ง grantRolesToRole คุณสามารถมอบบทบาทให้กับบทบาทที่ผู้ใช้กำหนดเองได้ คำสั่ง grantRolesToRole จะส่งผลต่อบทบาทบนฐานข้อมูลที่ดำเนินการคำสั่ง
คำสั่ง grantRolesToRole นี้มีรูปแบบดังนี้:
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) สิทธิ์การเข้าถึงจะคล้ายกับคำสั่ง grantRolesToUser คุณต้องมีการดำเนินการ grantRole บนฐานข้อมูลเพื่อการดำเนินการตามคำสั่งที่เหมาะสม
ในตัวอย่างต่อไปนี้ คุณสามารถใช้คำสั่ง grantRolesToUser เพื่ออัปเดตบทบาท productsReader ในฐานข้อมูล "ผลิตภัณฑ์" เพื่อสืบทอดสิทธิ์ของบทบาท productsWriter :
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )เพิกถอนสิทธิ์จากบทบาท
คุณสามารถใช้ revokePrivilegesFromRole เพื่อลบสิทธิ์ที่ระบุออกจากบทบาทที่ผู้ใช้กำหนดบนฐานข้อมูลที่ดำเนินการคำสั่ง เพื่อการดำเนินการที่เหมาะสม คุณต้องคำนึงถึงไวยากรณ์ต่อไปนี้:
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )หากต้องการเพิกถอนสิทธิ์ รูปแบบ "เอกสารทรัพยากร" ต้องตรงกับฟิลด์ "ทรัพยากร" ของสิทธิ์นั้น ฟิลด์ "การดำเนินการ" สามารถเป็นการจับคู่แบบตรงทั้งหมดหรือเป็นส่วนย่อยก็ได้
ตัวอย่างเช่น พิจารณาบทบาท manageRole ในฐานข้อมูลผลิตภัณฑ์ที่มีสิทธิ์ต่อไปนี้ซึ่งระบุฐานข้อมูล "ผู้จัดการ" เป็นทรัพยากร:
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }คุณไม่สามารถเพิกถอนการดำเนินการ "แทรก" หรือ "ลบ" จากคอลเลกชันเดียวในฐานข้อมูลผู้จัดการได้ การดำเนินการต่อไปนี้ไม่ทำให้เกิดการเปลี่ยนแปลงในบทบาท:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) หากต้องการเพิกถอนการดำเนินการ "แทรก" และ/หรือ "นำออก" จากบทบาท manageRole คุณต้องจับคู่เอกสารทรัพยากรให้ตรงกันทุกประการ ตัวอย่างเช่น การดำเนินการต่อไปนี้จะเพิกถอนเฉพาะการดำเนินการ "ลบ" จากสิทธิ์ที่มีอยู่:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )การดำเนินการต่อไปนี้จะลบสิทธิ์หลายรายการออกจากบทบาท "ผู้บริหาร" ในฐานข้อมูลผู้จัดการ:
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )บทบาทInfo
คำสั่ง rolesInfo จะส่งคืนข้อมูลสิทธิ์และการสืบทอดสำหรับบทบาทที่ระบุ รวมถึงบทบาทในตัวและที่ผู้ใช้กำหนด คุณยังสามารถใช้ประโยชน์จากคำสั่ง rolesInfo เพื่อดึงบทบาททั้งหมดที่มีขอบเขตไปยังฐานข้อมูล
เพื่อการดำเนินการที่เหมาะสม ให้ทำตามไวยากรณ์นี้:
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )ในการส่งคืนข้อมูลสำหรับบทบาทจากฐานข้อมูลปัจจุบัน คุณสามารถระบุชื่อได้ดังนี้:
{ rolesInfo: "<rolename>" }ในการส่งคืนข้อมูลสำหรับบทบาทจากฐานข้อมูลอื่น คุณสามารถพูดถึงบทบาทด้วยเอกสารที่กล่าวถึงบทบาทและฐานข้อมูล:
{ rolesInfo: { role: "<rolename>", db: "<database>" } }ตัวอย่างเช่น คำสั่งต่อไปนี้ส่งคืนข้อมูลการสืบทอดบทบาทสำหรับผู้บริหารบทบาทที่กำหนดไว้ในฐานข้อมูลผู้จัดการ:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) คำสั่งถัดไปนี้จะส่งคืนข้อมูลการสืบทอดบทบาท: accountManager บนฐานข้อมูลที่ดำเนินการคำสั่ง:
db.runCommand( { rolesInfo: "accountManager" } )คำสั่งต่อไปนี้จะส่งคืนทั้งสิทธิ์และการสืบทอดบทบาทสำหรับบทบาท "ผู้บริหาร" ตามที่กำหนดไว้ในฐานข้อมูลผู้จัดการ:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )หากต้องการกล่าวถึงหลายบทบาท คุณสามารถใช้อาร์เรย์ได้ คุณยังสามารถพูดถึงแต่ละบทบาทในอาร์เรย์เป็นสตริงหรือเอกสารได้
คุณควรใช้สตริงก็ต่อเมื่อมีบทบาทในฐานข้อมูลที่ดำเนินการคำสั่ง:
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }ตัวอย่างเช่น คำสั่งต่อไปนี้จะส่งคืนข้อมูลสำหรับสามบทบาทในสามฐานข้อมูลที่แตกต่างกัน:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )คุณสามารถรับทั้งสิทธิ์และมรดกบทบาทได้ดังนี้:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )การฝังเอกสาร MongoDB เพื่อประสิทธิภาพที่ดีขึ้น
ฐานข้อมูลเอกสาร เช่น MongoDB ให้คุณกำหนดสคีมาตามความต้องการของคุณ ในการสร้างสคีมาที่เหมาะสมที่สุดใน MongoDB คุณสามารถซ้อนเอกสารได้ ดังนั้น แทนที่จะจับคู่แอปพลิเคชันของคุณกับโมเดลข้อมูล คุณสามารถสร้างโมเดลข้อมูลที่ตรงกับกรณีการใช้งานของคุณได้
เอกสารฝังตัวช่วยให้คุณจัดเก็บข้อมูลที่เกี่ยวข้องที่คุณเข้าถึงร่วมกันได้ ขณะออกแบบสคีมาสำหรับ MongoDB ขอแนะนำให้คุณฝังเอกสารตามค่าเริ่มต้น ใช้การรวมและการอ้างอิงด้านฐานข้อมูลหรือด้านแอปพลิเคชันเฉพาะเมื่อจำเป็นเท่านั้น
ตรวจสอบให้แน่ใจว่าปริมาณงานสามารถดึงเอกสารได้บ่อยเท่าที่ต้องการ ในขณะเดียวกัน เอกสารก็ควรมีข้อมูลทั้งหมดที่จำเป็นด้วย นี่เป็นส่วนสำคัญสำหรับประสิทธิภาพอันยอดเยี่ยมของแอปพลิเคชันของคุณ
ด้านล่างนี้ คุณจะพบรูปแบบต่างๆ สองสามรูปแบบในการฝังเอกสาร:
รูปแบบเอกสารฝังตัว
คุณสามารถใช้สิ่งนี้เพื่อฝังโครงสร้างย่อยที่ซับซ้อนแม้แต่ในเอกสารที่ใช้ การฝังข้อมูลที่เชื่อมต่อในเอกสารฉบับเดียวสามารถลดจำนวนการดำเนินการอ่านที่จำเป็นในการรับข้อมูล โดยทั่วไป คุณควรจัดโครงสร้างสคีมาของคุณ เพื่อให้แอปพลิเคชันของคุณได้รับข้อมูลที่จำเป็นทั้งหมดในการดำเนินการอ่านครั้งเดียว ดังนั้น กฎที่ต้องจำไว้ในที่นี้คือ สิ่งที่ใช้ร่วมกันควรเก็บไว้ด้วยกัน
รูปแบบเซตย่อยที่ฝังตัว
รูปแบบชุดย่อยที่ฝังตัวเป็นเคสไฮบริด คุณจะใช้มันเพื่อแยกรายการที่เกี่ยวข้องกันยาวๆ ซึ่งคุณสามารถเก็บรายการเหล่านั้นไว้พร้อมสำหรับแสดง
นี่คือตัวอย่างที่แสดงรายการบทวิจารณ์ภาพยนตร์:
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }ตอนนี้ ลองนึกภาพบทวิจารณ์ที่คล้ายกันนับพันรายการ แต่คุณวางแผนที่จะแสดงสองรายการล่าสุดเมื่อคุณแสดงภาพยนตร์เท่านั้น ในสถานการณ์สมมตินี้ การจัดเก็บเซ็ตย่อยนั้นเป็นรายการภายในเอกสารภาพยนตร์:
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</codeพูดง่ายๆ ก็คือ หากคุณเข้าถึงชุดย่อยของรายการที่เกี่ยวข้องเป็นประจำ ตรวจสอบให้แน่ใจว่าคุณได้ฝังไว้
การเข้าถึงอิสระ
คุณอาจต้องการจัดเก็บเอกสารย่อยในคอลเลกชันเพื่อแยกเอกสารออกจากคอลเลกชันหลัก
ตัวอย่างเช่น ใช้สายผลิตภัณฑ์ของบริษัท หากบริษัทขายผลิตภัณฑ์ชุดเล็กๆ คุณอาจต้องการเก็บไว้ในเอกสารของบริษัท แต่ถ้าคุณต้องการใช้ซ้ำในบริษัทต่างๆ หรือเข้าถึงโดยตรงโดยหน่วยเก็บสต็อก (SKU) ของพวกเขา คุณก็ควรเก็บไว้ในคอลเล็กชันของพวกเขาด้วย
หากคุณจัดการหรือเข้าถึงเอนทิตีโดยอิสระ ให้สร้างคอลเล็กชันเพื่อจัดเก็บแยกไว้ต่างหากเพื่อแนวทางปฏิบัติที่ดีที่สุด
รายการที่ไม่มีขอบเขต
การจัดเก็บรายการสั้น ๆ ของข้อมูลที่เกี่ยวข้องในเอกสารของพวกเขามีข้อเสียเปรียบ ถ้ารายการของคุณยังคงเติบโตโดยไม่มีการเลือก คุณไม่ควรใส่ไว้ในเอกสารเดียว เนื่องจากคุณจะไม่สามารถสนับสนุนได้นานนัก
มีสองเหตุผลสำหรับเรื่องนี้ ประการแรก MongoDB มีการจำกัดขนาดของเอกสารเดียว ประการที่สอง หากคุณเข้าถึงเอกสารที่ความถี่มากเกินไป คุณจะเห็นผลลัพธ์เชิงลบจากการใช้หน่วยความจำที่ไม่สามารถควบคุมได้
พูดง่ายๆ ก็คือ หากรายการเริ่มเติบโตอย่างไม่มีขอบเขต ให้สร้างคอลเล็กชันเพื่อจัดเก็บแยกกัน
รูปแบบการอ้างอิงเพิ่มเติม
The extended reference pattern is like the subset pattern. It also optimizes information that you regularly access to store on the document.
Here, instead of a list, it's leveraged when a document refers to another that is present in the same collection. At the same time, it also stores some fields from that other document for ready access.
For instance:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
System Memory
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
การเชื่อมต่อ
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
อัตราส่วนตัวเลขที่สูงชี้ไปที่การดำเนินการที่ไม่เหมาะสม การดำเนินการเหล่านี้สแกนเอกสารจำนวนมากเพื่อส่งคืนชิ้นส่วนที่เล็กกว่า
สแกนและสั่งซื้อ
ซึ่งจะอธิบายอัตราเฉลี่ยต่อวินาทีในช่วงตัวอย่างที่เลือกของข้อความค้นหา ส่งคืนผลลัพธ์ที่เรียงลำดับซึ่งไม่สามารถดำเนินการเรียงลำดับโดยใช้ดัชนีได้
คิว
คิวสามารถอธิบายจำนวนการดำเนินการที่รอการล็อก ไม่ว่าจะเขียนหรืออ่าน คิวสูงอาจแสดงถึงการมีอยู่ของการออกแบบสคีมาที่น้อยกว่าที่เหมาะสม นอกจากนี้ยังสามารถบ่งบอกถึงเส้นทางการเขียนที่ขัดแย้งกัน ผลักดันการแข่งขันสูงเหนือทรัพยากรฐานข้อมูล
ตัวชี้วัดการจำลองแบบ MongoDB
ต่อไปนี้คือตัวชี้วัดหลักสำหรับการตรวจสอบการจำลอง:
หน้าต่าง Oplog การจำลองแบบ
ตัวชี้วัดนี้แสดงรายการจำนวนชั่วโมงโดยประมาณที่มีอยู่ใน oplog การจำลองแบบหลัก หากความล่าช้ารองเกินจำนวนนี้ จะตามไม่ทันและจะต้องซิงค์ใหม่ทั้งหมด
การจำลองแบบล่าช้า
ความล่าช้าในการจำลองแบบถูกกำหนดให้เป็นจำนวนวินาทีโดยประมาณที่โหนดรองอยู่หลังโหนดหลักในการดำเนินการเขียน ความล่าช้าในการจำลองสูงจะชี้ไปที่ปัญหารองที่ประสบปัญหาในการทำซ้ำ อาจส่งผลต่อเวลาแฝงของการดำเนินการ เนื่องจากข้อกังวลด้านการอ่าน/เขียนของการเชื่อมต่อ
Headroom การจำลองแบบ
ตัวชี้วัดนี้อ้างถึงความแตกต่างระหว่างหน้าต่าง oplog ของการจำลองหลักและความล่าช้าในการจำลองแบบรอง หากค่านี้เป็นศูนย์ อาจทำให้ค่ารองเข้าสู่โหมดการกู้คืน
Opcounters -repl
Opcounters -repl ถูกกำหนดให้เป็นอัตราเฉลี่ยของการดำเนินการจำลองแบบที่ดำเนินการต่อวินาทีสำหรับช่วงตัวอย่างที่เลือก ด้วย opcounters -graph/metric คุณสามารถดูความเร็วการดำเนินงานและรายละเอียดของประเภทการดำเนินการสำหรับอินสแตนซ์ที่ระบุได้
Oplog GB/ชั่วโมง
สิ่งนี้ถูกกำหนดให้เป็นอัตราเฉลี่ยของกิกะไบต์ของ oplog หลักที่สร้างขึ้นต่อชั่วโมง ปริมาณ oplog ที่ไม่คาดคิดสูงอาจชี้ไปที่ปริมาณงานการเขียนที่ไม่เพียงพอหรือปัญหาการออกแบบสคีมา
เครื่องมือตรวจสอบประสิทธิภาพ MongoDB
MongoDB มีเครื่องมืออินเทอร์เฟซผู้ใช้ในตัวใน Cloud Manager, Atlas และ Ops Manager สำหรับการติดตามประสิทธิภาพ นอกจากนี้ยังมีคำสั่งและเครื่องมืออิสระบางอย่างเพื่อดูข้อมูลดิบมากขึ้น เราจะพูดถึงเครื่องมือบางอย่างที่คุณสามารถเรียกใช้จากโฮสต์ที่มีการเข้าถึงและบทบาทที่เหมาะสมในการตรวจสอบสภาพแวดล้อมของคุณ:
mongotop
คุณสามารถใช้คำสั่งนี้เพื่อติดตามระยะเวลาที่อินสแตนซ์ MongoDB ใช้ในการเขียนและอ่านข้อมูลต่อคอลเล็กชัน ใช้ไวยากรณ์ต่อไปนี้:
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
คำสั่งนี้ส่งคืนสถานะชุดเรพลิกา มันดำเนินการจากมุมมองของสมาชิกที่ดำเนินการวิธีการ
mongostat
คุณสามารถใช้คำสั่ง mongostat เพื่อดูภาพรวมอย่างรวดเร็วของสถานะของอินสแตนซ์เซิร์ฟเวอร์ MongoDB ของคุณ เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด คุณสามารถใช้เพื่อดูอินสแตนซ์เดียวสำหรับเหตุการณ์เฉพาะ เนื่องจากนำเสนอมุมมองแบบเรียลไทม์
ใช้ประโยชน์จากคำสั่งนี้เพื่อตรวจสอบสถิติพื้นฐานของเซิร์ฟเวอร์ เช่น ล็อกคิว การแบ่งการทำงาน สถิติหน่วยความจำ MongoDB และการเชื่อมต่อ/เครือข่าย:
mongostat <options> <connection-string> <polling interval in seconds>dbStats
คำสั่งนี้ส่งคืนสถิติการจัดเก็บสำหรับฐานข้อมูลเฉพาะ เช่น จำนวนดัชนีและขนาด ข้อมูลการรวบรวมทั้งหมดเทียบกับขนาดหน่วยเก็บข้อมูล และสถิติที่เกี่ยวข้องกับการรวบรวม (จำนวนคอลเลกชันและเอกสาร)
db.serverStatus()
คุณสามารถใช้คำสั่ง db.serverStatus() เพื่อให้มีภาพรวมของสถานะของฐานข้อมูล มันให้เอกสารที่แสดงถึงตัวนับตัววัดอินสแตนซ์ปัจจุบัน ดำเนินการคำสั่งนี้เป็นระยะเพื่อเปรียบเทียบสถิติเกี่ยวกับอินสแตนซ์
collStats
คำสั่ง collStats รวบรวมสถิติที่คล้ายกับที่เสนอโดย dbStats ที่ระดับการรวบรวม ผลลัพธ์ประกอบด้วยจำนวนอ็อบเจ็กต์ในคอลเล็กชัน จำนวนพื้นที่ดิสก์ที่ใช้โดยคอลเล็กชัน ขนาดของคอลเล็กชัน และข้อมูลที่เกี่ยวข้องกับดัชนีสำหรับคอลเล็กชันที่กำหนด
คุณสามารถใช้คำสั่งเหล่านี้ทั้งหมดเพื่อเสนอการรายงานตามเวลาจริงและการตรวจสอบเซิร์ฟเวอร์ฐานข้อมูล ที่ให้คุณตรวจสอบประสิทธิภาพและข้อผิดพลาดของฐานข้อมูล และช่วยในการตัดสินใจอย่างมีข้อมูลเพื่อปรับแต่งฐานข้อมูล
วิธีการลบฐานข้อมูล MongoDB
ในการวางฐานข้อมูลที่คุณสร้างใน MongoDB คุณต้องเชื่อมต่อผ่านคีย์เวิร์ด use
สมมติว่าคุณสร้างฐานข้อมูลชื่อ “วิศวกร” ในการเชื่อมต่อกับฐานข้อมูล คุณจะใช้คำสั่งต่อไปนี้:
use Engineers ถัดไป พิมพ์ db.dropDatabase() เพื่อกำจัดฐานข้อมูลนี้ หลังจากดำเนินการ นี่คือผลลัพธ์ที่คุณคาดหวังได้:
{ "dropped" : "Engineers", "ok" : 1 } คุณสามารถรันคำสั่ง showdbs เพื่อตรวจสอบว่าฐานข้อมูลยังคงมีอยู่หรือไม่
สรุป
ในการบีบค่าทุกหยดสุดท้ายจาก MongoDB คุณต้องมีความเข้าใจพื้นฐานที่ดี ดังนั้น การรู้จักฐานข้อมูล MongoDB อย่างหลังมือจึงเป็นสิ่งสำคัญ สิ่งนี้จำเป็นต้องทำความคุ้นเคยกับวิธีการสร้างฐานข้อมูลก่อน
ในบทความนี้ เราให้ความกระจ่างเกี่ยวกับวิธีการต่างๆ ที่คุณสามารถใช้เพื่อสร้างฐานข้อมูลใน MongoDB ตามด้วยคำอธิบายโดยละเอียดของคำสั่ง MongoDB บางส่วนที่จะช่วยให้คุณเข้าใจฐานข้อมูลของคุณ สุดท้าย เราได้สรุปการอภิปรายโดยพูดคุยถึงวิธีที่คุณสามารถใช้ประโยชน์จากเอกสารที่ฝังตัวและเครื่องมือตรวจสอบประสิทธิภาพใน MongoDB เพื่อให้แน่ใจว่าเวิร์กโฟลว์ของคุณทำงานได้อย่างมีประสิทธิภาพสูงสุด
คุณคิดอย่างไรกับคำสั่ง MongoDB เหล่านี้ เราพลาดมุมมองหรือวิธีการที่คุณอยากเห็นที่นี่หรือไม่? แจ้งให้เราทราบในความคิดเห็น!