
สร้าง MongoDB Replica ที่มีประสิทธิภาพในเวลาบันทึก (4 วิธี)
เผยแพร่แล้ว: 2023-03-11MongoDB เป็นฐานข้อมูล NoSQL ที่ใช้เอกสารคล้าย JSON พร้อมสคีมาแบบไดนามิก เมื่อทำงานกับฐานข้อมูล เป็นเรื่องดีเสมอที่จะมีแผนฉุกเฉินในกรณีที่เซิร์ฟเวอร์ฐานข้อมูลของคุณล้มเหลว แถบด้านข้าง คุณสามารถลดโอกาสที่จะเกิดขึ้นได้โดยใช้ประโยชน์จากเครื่องมือการจัดการที่ดีสำหรับเว็บไซต์ WordPress ของคุณ
นี่คือเหตุผลว่าทำไมการมีสำเนาข้อมูลของคุณจำนวนมากจึงเป็นประโยชน์ นอกจากนี้ยังลดเวลาแฝงในการอ่าน ในขณะเดียวกันก็สามารถปรับปรุงความสามารถในการปรับขนาดและความพร้อมใช้งานของฐานข้อมูล นี่คือที่มาของการจำลองแบบ ซึ่งหมายถึงการปฏิบัติในการซิงโครไนซ์ข้อมูลระหว่างฐานข้อมูลต่างๆ
ในบทความนี้ เราจะเจาะลึกถึงลักษณะเด่นต่างๆ ของการจำลองแบบ MongoDB เช่น คุณลักษณะและกลไก เป็นต้น
การจำลองแบบใน MongoDB คืออะไร?
ใน MongoDB ชุดเรพลิเคทจะทำการจำลองแบบ นี่คือกลุ่มของเซิร์ฟเวอร์ที่รักษาชุดข้อมูลเดียวกันผ่านการจำลองแบบ คุณสามารถใช้การจำลองแบบ MongoDB เป็นส่วนหนึ่งของการทำโหลดบาลานซ์ได้ ที่นี่ คุณสามารถกระจายการดำเนินการเขียนและอ่านในทุกอินสแตนซ์ โดยขึ้นอยู่กับกรณีการใช้งาน
MongoDB Replica Set คืออะไร?
ทุกอินสแตนซ์ของ MongoDB ที่เป็นส่วนหนึ่งของชุดจำลองที่กำหนดเป็นสมาชิก ชุดแบบจำลองทุกชุดจำเป็นต้องมีสมาชิกหลักและสมาชิกรองอย่างน้อยหนึ่งคน
สมาชิกหลักคือจุดเชื่อมต่อหลักสำหรับการทำธุรกรรมกับชุดเรพลิคา นอกจากนี้ยังเป็นสมาชิกเดียวที่สามารถยอมรับการดำเนินการเขียนได้ การจำลองแบบจะคัดลอก oplog ของตัวหลัก (บันทึกการทำงาน) ก่อน ถัดไป จะทำซ้ำการเปลี่ยนแปลงที่บันทึกไว้ในชุดข้อมูลรองตามลำดับ ดังนั้น ทุกชุดแบบจำลองสามารถมีสมาชิกหลักได้ครั้งละหนึ่งตัวเท่านั้น ไพรมารีต่างๆ ที่ได้รับการดำเนินการเขียนอาจทำให้เกิดความขัดแย้งของข้อมูล
โดยปกติแล้ว แอปพลิเคชันจะสอบถามเฉพาะสมาชิกหลักสำหรับการดำเนินการเขียนและอ่านเท่านั้น คุณสามารถออกแบบการตั้งค่าของคุณให้อ่านจากสมาชิกรองตั้งแต่หนึ่งคนขึ้นไป การถ่ายโอนข้อมูลแบบอะซิงโครนัสอาจทำให้การอ่านโหนดรองให้บริการข้อมูลเก่าได้ ดังนั้น การจัดเรียงดังกล่าวจึงไม่เหมาะสำหรับทุกกรณีการใช้งาน
คุณสมบัติชุดแบบจำลอง
กลไกการเฟลโอเวอร์อัตโนมัติทำให้ชุดจำลองของ MongoDB แตกต่างจากคู่แข่ง ในกรณีที่ไม่มีโหนดหลัก การเลือกตั้งอัตโนมัติระหว่างโหนดรองจะเลือกโหนดหลักใหม่
MongoDB Replica Set เทียบกับ MongoDB Cluster
ชุดแบบจำลอง MongoDB จะสร้างชุดข้อมูลชุดเดียวกันหลายชุดในโหนดชุดแบบจำลอง เป้าหมายหลักของชุดแบบจำลองคือ:
- เสนอโซลูชันการสำรองข้อมูลในตัว
- เพิ่มความพร้อมใช้งานของข้อมูล
MongoDB คลัสเตอร์เป็นเกมบอลที่แตกต่างไปจากเดิมอย่างสิ้นเชิง มันกระจายข้อมูลไปยังโหนดจำนวนมากผ่านชาร์ดคีย์ กระบวนการนี้จะแยกส่วนข้อมูลออกเป็นหลายส่วนเรียกว่า ชาร์ด จากนั้นจะคัดลอกแต่ละส่วนย่อยไปยังโหนดอื่น คลัสเตอร์มีเป้าหมายเพื่อรองรับชุดข้อมูลขนาดใหญ่และการดำเนินการที่มีปริมาณงานสูง ทำได้โดยการปรับขนาดภาระงานในแนวนอน
นี่คือความแตกต่างระหว่างชุดแบบจำลองและคลัสเตอร์ในแง่ของคนธรรมดา:
- คลัสเตอร์กระจายภาระงาน นอกจากนี้ยังเก็บส่วนย่อยของข้อมูล (เศษ) ไว้ในเซิร์ฟเวอร์จำนวนมาก
- ชุดจำลองจะทำซ้ำชุดข้อมูลทั้งหมด
MongoDB อนุญาตให้คุณรวมฟังก์ชันเหล่านี้เข้าด้วยกันโดยสร้างคลัสเตอร์ที่แยกส่วน ที่นี่ คุณสามารถจำลองชิ้นส่วนทั้งหมดไปยังเซิร์ฟเวอร์สำรองได้ ซึ่งช่วยให้ชาร์ดมีความซ้ำซ้อนและความพร้อมใช้งานของข้อมูลสูง
การบำรุงรักษาและการตั้งค่าชุดจำลองอาจทำให้ต้องเสียภาษีและใช้เวลานานในทางเทคนิค และค้นหาบริการโฮสติ้งที่เหมาะสม? นั่นเป็นอาการปวดหัวอื่น ๆ ทั้งหมด ด้วยตัวเลือกที่มีอยู่มากมาย คุณจึงเสียเวลาไปกับการหาข้อมูลแทนที่จะต้องสร้างธุรกิจ
ให้ฉันอธิบายสั้น ๆ เกี่ยวกับเครื่องมือที่ทำทั้งหมดนี้และอื่น ๆ อีกมากมายเพื่อที่คุณจะได้กลับไปทำลายมันด้วยบริการ/ผลิตภัณฑ์ของคุณ
โซลูชันการโฮสต์แอปพลิเคชันของ Kinsta ซึ่งได้รับความไว้วางใจจากนักพัฒนามากกว่า 55,000 ราย คุณสามารถเริ่มต้นใช้งานด้วยขั้นตอนง่ายๆ เพียง 3 ขั้นตอน หากนั่นฟังดูดีเกินจริง ต่อไปนี้เป็นประโยชน์บางประการของการใช้ Kinsta:
- เพลิดเพลินกับประสิทธิภาพที่ดีขึ้นด้วยการเชื่อมต่อภายในของ Kinsta : ลืมเรื่องยุ่งยากกับฐานข้อมูลที่ใช้ร่วมกันไปได้เลย สลับไปยังฐานข้อมูลเฉพาะที่มีการเชื่อมต่อภายในที่ไม่มีการจำกัดจำนวนคิวรีหรือจำนวนแถว Kinsta เร็วกว่า ปลอดภัยกว่า และจะไม่เรียกเก็บเงินจากคุณสำหรับแบนด์วิธ/การรับส่งข้อมูลภายใน
- ชุดคุณลักษณะที่ปรับแต่งมาสำหรับนักพัฒนาซอฟต์แวร์ : ปรับขนาดแอปพลิเคชันของคุณบนแพลตฟอร์มที่แข็งแกร่งซึ่งรองรับ Gmail, YouTube และ Google Search มั่นใจได้เลยว่าคุณจะปลอดภัยที่สุดที่นี่
- เพลิดเพลินกับความเร็วที่เหนือชั้นด้วยศูนย์ข้อมูลที่คุณเลือก : เลือกภูมิภาคที่เหมาะกับคุณและลูกค้าของคุณมากที่สุด ด้วยศูนย์ข้อมูลกว่า 25 แห่งให้เลือก PoP กว่า 275 แห่ง ของ Kinsta รับประกันความเร็วสูงสุดและการแสดงตัวตนทั่วโลกสำหรับเว็บไซต์ของคุณ
ลองใช้โซลูชันการโฮสต์แอปพลิเคชันของ Kinsta ฟรีวันนี้!
การจำลองแบบทำงานใน MongoDB อย่างไร
ใน MongoDB คุณส่งการดำเนินการเขียนไปยังเซิร์ฟเวอร์หลัก (โหนด) หลักกำหนดการดำเนินการข้ามเซิร์ฟเวอร์รอง จำลองข้อมูล
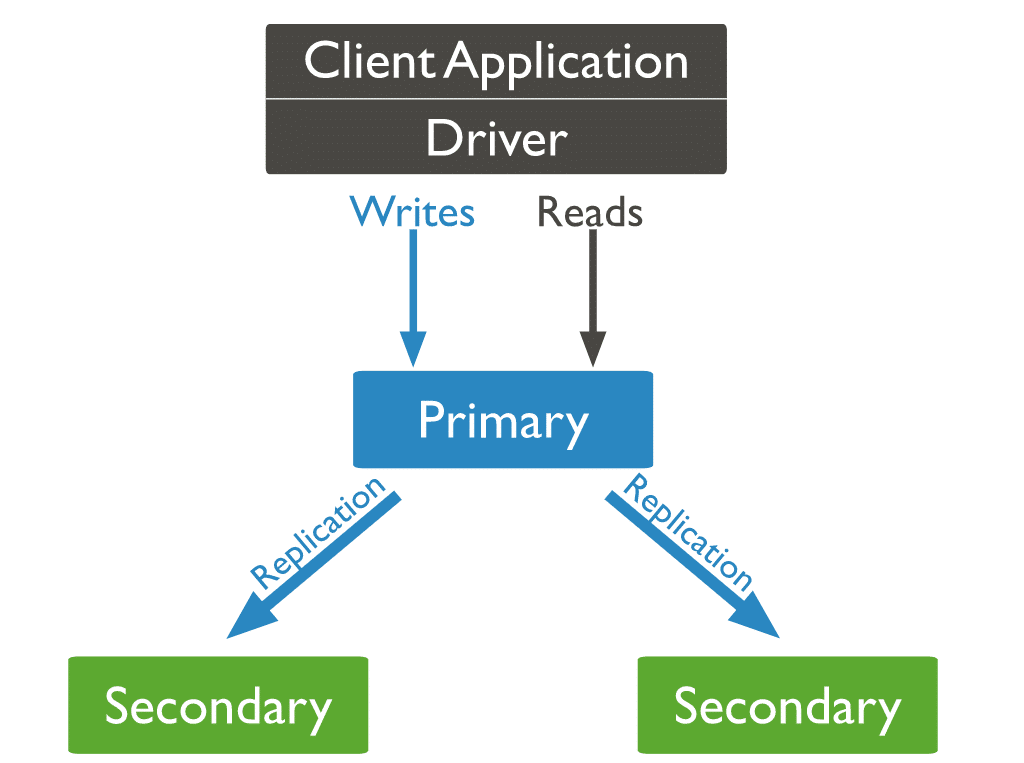
โหนด MongoDB สามประเภท
จากโหนด MongoDB ทั้งสามประเภท มีโหนดสองโหนดเกิดขึ้นก่อน: โหนดหลักและโหนดรอง โหนด MongoDB ประเภทที่สามที่มีประโยชน์ในระหว่างการจำลองแบบคือตัวตัดสิน โหนดอนุญาโตตุลาการไม่มีสำเนาของชุดข้อมูลและไม่สามารถกลายเป็นหลักได้ ต้องบอกว่าผู้ชี้ขาดมีส่วนร่วมในการเลือกตั้งขั้นต้น
ก่อนหน้านี้เราได้กล่าวถึงสิ่งที่จะเกิดขึ้นเมื่อโหนดหลักหยุดทำงาน แต่จะเกิดอะไรขึ้นหากโหนดรองพังทลาย ในสถานการณ์นั้น โหนดหลักจะกลายเป็นรองและฐานข้อมูลจะไม่สามารถเข้าถึงได้
การเลือกตั้งสมาชิก
การเลือกตั้งสามารถเกิดขึ้นได้ในสถานการณ์ต่อไปนี้:
- กำลังเริ่มต้นชุดจำลอง
- สูญเสียการเชื่อมต่อกับโหนดหลัก (ที่สามารถตรวจจับได้ด้วยการเต้นของหัวใจ)
- การบำรุงรักษาชุดเรพลิกาโดยใช้เมธอด
rs.reconfigหรือstepDown - การเพิ่มโหนดใหม่ให้กับชุดแบบจำลองที่มีอยู่
ชุดจำลองสามารถมีสมาชิกได้สูงสุด 50 คน แต่มีเพียง 7 คนหรือน้อยกว่าเท่านั้นที่สามารถลงคะแนนในการเลือกตั้งใดๆ
เวลาเฉลี่ยก่อนที่คลัสเตอร์จะเลือกหลักใหม่ไม่ควรเกิน 12 วินาที อัลกอริทึมการเลือกจะพยายามให้มีรองที่มีลำดับความสำคัญสูงสุด ในขณะเดียวกัน สมาชิกที่มีค่าลำดับความสำคัญเป็น 0 ไม่สามารถเป็นไพรมารีและไม่ได้มีส่วนร่วมในการเลือกตั้ง
ความกังวลในการเขียน
เพื่อความทนทาน การดำเนินการเขียนมีเฟรมเวิร์กเพื่อคัดลอกข้อมูลในจำนวนโหนดที่ระบุ คุณสามารถให้ข้อเสนอแนะแก่ลูกค้าได้ด้วยสิ่งนี้ กรอบนี้เรียกอีกอย่างว่า "ข้อกังวลในการเขียน" มีสมาชิกที่มีข้อมูลซึ่งจำเป็นต้องรับทราบข้อกังวลที่เป็นลายลักษณ์อักษรก่อนที่การดำเนินการจะกลับเป็นผลสำเร็จ โดยทั่วไป ชุดเรพลิกามีค่าเป็น 1 เป็นข้อกังวลในการเขียน ดังนั้น เฉพาะบุคคลหลักเท่านั้นที่ควรรับทราบการเขียนก่อนที่จะส่งคืนการรับทราบข้อกังวลในการเขียน
คุณสามารถเพิ่มจำนวนสมาชิกที่จำเป็นในการรับทราบการดำเนินการเขียน ไม่มีเพดานสำหรับจำนวนสมาชิกที่คุณสามารถมีได้ แต่ถ้าตัวเลขสูง คุณต้องจัดการกับเวลาแฝงที่สูง เนื่องจากลูกค้าต้องรอการตอบรับจากสมาชิกทุกท่าน นอกจากนี้คุณยังสามารถกำหนดข้อกังวลในการเขียนของ "เสียงส่วนใหญ่" ซึ่งจะคำนวณสมาชิกมากกว่าครึ่งหนึ่งหลังจากได้รับการตอบรับ
อ่านการตั้งค่า
สำหรับการดำเนินการอ่าน คุณสามารถระบุการตั้งค่าการอ่านที่อธิบายวิธีที่ฐานข้อมูลกำหนดคิวรีไปยังสมาชิกของชุดเรพลิกา โดยทั่วไป โหนดหลักจะได้รับการดำเนินการอ่าน แต่ไคลเอนต์สามารถกล่าวถึงการตั้งค่าการอ่านเพื่อส่งการดำเนินการอ่านไปยังโหนดรอง ต่อไปนี้คือตัวเลือกสำหรับการตั้งค่าการอ่าน:
- primaryPreferred : โดยปกติแล้ว การดำเนินการอ่านจะมาจากโหนดหลัก แต่ถ้าไม่พร้อมใช้งาน ข้อมูลจะถูกดึงมาจากโหนดรอง
- หลัก : การดำเนินการอ่านทั้งหมดมาจากโหนดหลัก
- รอง : การดำเนินการอ่านทั้งหมดดำเนินการโดยโหนดรอง
- ใกล้ที่สุด : ที่นี่ คำร้องขอการอ่านจะถูกส่งไปยังโหนดที่เข้าถึงได้ที่ใกล้ที่สุด ซึ่งสามารถตรวจจับได้โดยการรันคำสั่ง
pingผลลัพธ์ของการดำเนินการอ่านอาจมาจากสมาชิกใดๆ ของชุดจำลอง โดยไม่คำนึงว่าชุดนั้นจะเป็นชุดหลักหรือชุดรอง - secondaryPreferred : ที่นี่ การดำเนินการอ่านส่วนใหญ่มาจากโหนดรอง แต่ถ้าไม่มีเลย ข้อมูลจะถูกดึงมาจากโหนดหลัก
การซิงโครไนซ์ข้อมูลชุดการจำลองแบบ
เพื่อรักษาสำเนาล่าสุดของชุดข้อมูลที่ใช้ร่วมกัน สมาชิกรองของชุดจำลองจะทำซ้ำหรือซิงค์ข้อมูลจากสมาชิกคนอื่นๆ
MongoDB ใช้ประโยชน์จากการซิงโครไนซ์ข้อมูลสองรูปแบบ การซิงค์เริ่มต้นเพื่อเติมสมาชิกใหม่ด้วยชุดข้อมูลทั้งหมด การจำลองแบบเพื่อดำเนินการเปลี่ยนแปลงอย่างต่อเนื่องกับชุดข้อมูลทั้งหมด
การซิงค์เริ่มต้น
ระหว่างการซิงโครไนซ์เริ่มต้น โหนดรองรันคำสั่ง init sync เพื่อซิงโครไนซ์ข้อมูลทั้งหมดจากโหนดหลักไปยังโหนดรองอื่นที่มีข้อมูลล่าสุด ดังนั้น โหนดรองจะใช้ประโยชน์จากคุณลักษณะ tailable cursor อย่างสม่ำเสมอเพื่อสอบถามรายการ oplog ล่าสุดภายในคอลเล็กชัน local.oplog.rs ของโหนดหลัก และใช้การดำเนินการเหล่านี้ภายในรายการ oplog เหล่านี้
จาก MongoDB 5.2 การซิงค์เริ่มต้นอาจเป็นการคัดลอกไฟล์หรือแบบโลจิคัล
การซิงโครไนซ์เชิงตรรกะ
เมื่อคุณดำเนินการซิงค์แบบลอจิคัล MongoDB:
- พัฒนาดัชนีการรวบรวมทั้งหมดเมื่อมีการคัดลอกเอกสารสำหรับแต่ละคอลเลกชัน
- ทำซ้ำฐานข้อมูลทั้งหมดยกเว้นฐานข้อมูลในเครื่อง
mongodสแกนทุกคอลเลกชันในฐานข้อมูลต้นทางทั้งหมดและแทรกข้อมูลทั้งหมดลงในสำเนาของคอลเลกชันเหล่านี้ - ดำเนินการเปลี่ยนแปลงทั้งหมดบนชุดข้อมูล ด้วยการใช้ประโยชน์จาก oplog จากแหล่งที่มา
mongodจะอัปเกรดชุดข้อมูลเพื่ออธิบายสถานะปัจจุบันของชุดแบบจำลอง - แยกบันทึก oplog ที่เพิ่มใหม่ระหว่างการคัดลอกข้อมูล ตรวจสอบให้แน่ใจว่าสมาชิกเป้าหมายมีพื้นที่ดิสก์เพียงพอภายในฐานข้อมูลภายในเครื่องเพื่อจัดเก็บบันทึก oplog เหล่านี้อย่างไม่แน่นอนในช่วงระยะเวลาของระยะการคัดลอกข้อมูลนี้
เมื่อการซิงค์ครั้งแรกเสร็จสิ้น สมาชิกจะเปลี่ยนจาก STARTUP2 เป็น SECONDARY
การซิงค์เริ่มต้นตามการคัดลอกไฟล์
คุณสามารถดำเนินการได้ทันทีหากคุณใช้ MongoDB Enterprise กระบวนการนี้รันการซิงค์เริ่มต้นโดยการทำซ้ำและย้ายไฟล์บนระบบไฟล์ วิธีการซิงค์นี้อาจเร็วกว่าการซิงค์เริ่มต้นเชิงตรรกะในบางกรณี โปรดทราบว่าการซิงค์เริ่มต้นตามการคัดลอกไฟล์อาจนำไปสู่การนับที่ไม่ถูกต้อง หากคุณเรียกใช้เมธอด count() โดยไม่มีเพรดิเคตเคียวรี
แต่วิธีนี้มีข้อ จำกัด พอสมควรเช่นกัน:
- ในระหว่างการซิงค์เริ่มต้นตามการคัดลอกไฟล์ คุณไม่สามารถเขียนไปยังฐานข้อมูลภายในเครื่องของสมาชิกที่กำลังซิงค์ได้ คุณไม่สามารถเรียกใช้การสำรองข้อมูลบนสมาชิกที่กำลังซิงค์หรือสมาชิกที่กำลังซิงค์จาก
- เมื่อใช้ประโยชน์จากเครื่องมือจัดเก็บข้อมูลที่เข้ารหัส MongoDB จะใช้รหัสต้นทางเพื่อเข้ารหัสปลายทาง
- คุณสามารถเรียกใช้การซิงค์เริ่มต้นจากสมาชิกหนึ่งรายต่อครั้งเท่านั้น
การจำลองแบบ
สมาชิกรองทำซ้ำข้อมูลอย่างสม่ำเสมอหลังจากการซิงค์ครั้งแรก สมาชิกรองจะทำซ้ำ oplog จากการซิงค์จากต้นทางและดำเนินการเหล่านี้ในกระบวนการแบบอะซิงโครนัส
รองสามารถแก้ไขการซิงค์จากต้นทางได้โดยอัตโนมัติตามความจำเป็น โดยอิงตามการเปลี่ยนแปลงของเวลา ping และสถานะของการจำลองแบบของสมาชิกรายอื่น
การจำลองแบบสตรีมมิ่ง
จาก MongoDB 4.4 การซิงค์จากแหล่งที่มาจะส่งสตรีมรายการ oplog อย่างต่อเนื่องไปยังรายการที่สองที่ซิงค์ การจำลองแบบสตรีมมิ่งช่วยลดความล่าช้าในการจำลองแบบในเครือข่ายที่มีโหลดสูงและมีความหน่วงแฝงสูง นอกจากนี้ยังสามารถ:
- ลดความเสี่ยงในการสูญเสียการดำเนินการเขียนด้วย
w:1เนื่องจากการเฟลโอเวอร์หลัก - ลดความเก่าสำหรับการอ่านจากรอง
- ลดเวลาแฝงในการดำเนินการเขียนด้วย
w:“majority”และw:>1ในระยะสั้น ข้อกังวลในการเขียนใด ๆ ที่ต้องรอการจำลองแบบ
การจำลองแบบมัลติเธรด
MongoDB ใช้ในการเขียนการดำเนินการเป็นชุดผ่านหลายเธรดเพื่อปรับปรุงการทำงานพร้อมกัน MongoDB จัดกลุ่มแบทช์ตามรหัสเอกสารในขณะที่ใช้การดำเนินการแต่ละกลุ่มด้วยเธรดที่แตกต่างกัน
MongoDB ดำเนินการเขียนบนเอกสารที่กำหนดตามลำดับการเขียนดั้งเดิมเสมอ สิ่งนี้เปลี่ยนไปใน MongoDB 4.0
จาก MongoDB 4.0 การดำเนินการอ่านที่กำหนดเป้าหมายรองและกำหนดค่าด้วยระดับข้อกังวลในการอ่านเป็น “majority” หรือ “local” จะอ่านจากสแน็ปช็อต WiredTiger ของข้อมูล หากการอ่านเกิดขึ้นในรองซึ่งมีการใช้แบทช์การจำลองแบบ การอ่านจากสแน็ปช็อตรับประกันการดูข้อมูลที่สอดคล้องกัน และช่วยให้การอ่านเกิดขึ้นพร้อมกันกับการจำลองแบบต่อเนื่องโดยไม่ต้องล็อก
ดังนั้น การอ่านรองที่ต้องการระดับข้อกังวลในการอ่านเหล่านี้จึงไม่จำเป็นต้องรอให้ใช้ชุดการจำลองแบบอีกต่อไป และสามารถจัดการได้เมื่อได้รับ
วิธีสร้างชุดแบบจำลอง MongoDB
ตามที่กล่าวไว้ก่อนหน้านี้ MongoDB จัดการการจำลองแบบผ่านชุดแบบจำลอง ในสองสามส่วนถัดไป เราจะเน้นวิธีการบางอย่างที่คุณสามารถใช้เพื่อสร้างชุดจำลองสำหรับกรณีการใช้งานของคุณ
วิธีที่ 1: การสร้าง MongoDB Replica Set ใหม่บน Ubuntu
ก่อนที่เราจะเริ่มต้น คุณจะต้องแน่ใจว่าคุณมีเซิร์ฟเวอร์อย่างน้อยสามเครื่องที่ใช้ Ubuntu 20.04 โดยติดตั้ง MongoDB ในแต่ละเซิร์ฟเวอร์
ในการตั้งค่าชุดเรพพลิกา จำเป็นต้องระบุที่อยู่ที่สมาชิกชุดเรพพลิกาแต่ละตัวสามารถเข้าถึงได้โดยสมาชิกคนอื่นๆ ในชุด ในกรณีนี้ เราจะเก็บสมาชิกสามตัวไว้ในเซต แม้ว่าเราจะสามารถใช้ที่อยู่ IP ได้ แต่ก็ไม่แนะนำเนื่องจากที่อยู่อาจเปลี่ยนแปลงโดยไม่คาดคิด ทางเลือกที่ดีกว่าสามารถใช้ชื่อโฮสต์ DNS แบบลอจิคัลเมื่อกำหนดค่าชุดเรพลิกา
เราสามารถทำได้โดยกำหนดค่าโดเมนย่อยสำหรับแต่ละสมาชิกการจำลองแบบ แม้ว่าวิธีนี้จะเหมาะสำหรับสภาพแวดล้อมที่ใช้งานจริง ส่วนนี้จะสรุปวิธีกำหนดค่าการแก้ไข DNS โดยการแก้ไขไฟล์โฮสต์ของเซิร์ฟเวอร์แต่ละเครื่อง ไฟล์นี้ช่วยให้เรากำหนดชื่อโฮสต์ที่อ่านได้ให้กับที่อยู่ IP ที่เป็นตัวเลข ดังนั้น หากที่อยู่ IP ของคุณมีการเปลี่ยนแปลง สิ่งที่คุณต้องทำก็เพียงแค่อัปเดตไฟล์โฮสต์บนเซิร์ฟเวอร์ทั้งสามเครื่อง แทนที่จะกำหนดค่าแบบจำลองที่ตั้งค่าใหม่หมด!
ส่วนใหญ่ hosts จะถูกเก็บไว้ในไดเร็กทอรี /etc/ ทำซ้ำคำสั่งด้านล่างสำหรับเซิร์ฟเวอร์ทั้งสามของคุณ:
sudo nano /etc/hostsในคำสั่งด้านบน เราใช้ nano เป็นตัวแก้ไขข้อความ อย่างไรก็ตาม คุณสามารถใช้ตัวแก้ไขข้อความใดก็ได้ที่คุณต้องการ หลังจากสองสามบรรทัดแรกที่กำหนดค่า localhost ให้เพิ่มรายการสำหรับแต่ละสมาชิกของชุดเรพลิกา รายการเหล่านี้อยู่ในรูปแบบของที่อยู่ IP ตามด้วยชื่อที่มนุษย์อ่านได้ที่คุณเลือก แม้ว่าคุณจะสามารถตั้งชื่อพวกเขาตามที่คุณต้องการ แต่อย่าลืมอธิบายให้ชัดเจนเพื่อที่คุณจะได้รู้จักความแตกต่างระหว่างสมาชิกแต่ละคน สำหรับบทช่วยสอนนี้ เราจะใช้ชื่อโฮสต์ด้านล่าง:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
เมื่อใช้ชื่อโฮสต์เหล่านี้ ไฟล์ /etc/hosts ของคุณจะมีลักษณะคล้ายกับบรรทัดที่ไฮไลต์ต่อไปนี้:

บันทึกและปิดไฟล์
หลังจากกำหนดค่าความละเอียด DNS สำหรับชุดเรพลิกาแล้ว เราจำเป็นต้องอัปเดตกฎไฟร์วอลล์เพื่ออนุญาตให้สื่อสารกันได้ รันคำสั่ง ufw ต่อไปนี้บน mongo0 เพื่อให้ mongo1 เข้าถึงพอร์ต 27017 บน mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 แทนที่พารามิเตอร์ mongo1_server_ip ให้ป้อนที่อยู่ IP จริงของเซิร์ฟเวอร์ mongo1 ของคุณ นอกจากนี้ หากคุณได้อัปเดตอินสแตนซ์ Mongo บนเซิร์ฟเวอร์นี้เพื่อใช้พอร์ตที่ไม่ใช่ค่าเริ่มต้น อย่าลืมเปลี่ยน 27017 เพื่อให้สอดคล้องกับพอร์ตที่อินสแตนซ์ MongoDB ของคุณใช้อยู่
ตอนนี้เพิ่มกฎไฟร์วอลล์อื่นเพื่อให้ mongo2 เข้าถึงพอร์ตเดียวกัน:
sudo ufw allow from mongo2_server_ip to any port 27017 แทนที่พารามิเตอร์ mongo2_server_ip ให้ป้อนที่อยู่ IP จริงของเซิร์ฟเวอร์ mongo2 จากนั้น อัปเดตกฎไฟร์วอลล์สำหรับเซิร์ฟเวอร์อีกสองเครื่องของคุณ รันคำสั่งต่อไปนี้บนเซิร์ฟเวอร์ mongo1 ตรวจสอบให้แน่ใจว่าได้เปลี่ยนที่อยู่ IP แทนที่พารามิเตอร์ server_ip เพื่อสะท้อนถึงสิ่งเหล่านั้นของ mongo0 และ mongo2 ตามลำดับ:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017สุดท้าย รันสองคำสั่งนี้บน mongo2 ตรวจสอบอีกครั้งว่าคุณป้อนที่อยู่ IP ที่ถูกต้องสำหรับแต่ละเซิร์ฟเวอร์:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017ขั้นตอนต่อไปคืออัปเดตไฟล์การกำหนดค่าของอินสแตนซ์ MongoDB แต่ละไฟล์เพื่ออนุญาตการเชื่อมต่อภายนอก คุณต้องแก้ไขไฟล์ปรับแต่งในแต่ละเซิร์ฟเวอร์เพื่อแสดงที่อยู่ IP และระบุชุดเรพลิกา แม้ว่าคุณสามารถใช้โปรแกรมแก้ไขข้อความที่ต้องการได้ แต่เรากำลังใช้โปรแกรมแก้ไขข้อความนาโนอีกครั้ง มาทำการแก้ไขต่อไปนี้ในแต่ละไฟล์ mongod.conf
บน mongo0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"ใน mongo1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"บน mongo2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodด้วยสิ่งนี้ คุณได้เปิดใช้งานการจำลองสำหรับอินสแตนซ์ MongoDB ของแต่ละเซิร์ฟเวอร์
ตอนนี้คุณสามารถเริ่มต้นชุดแบบจำลองโดยใช้เมธอด rs.initiate() วิธีการนี้จำเป็นสำหรับการดำเนินการบนอินสแตนซ์ MongoDB เดียวในชุดแบบจำลองเท่านั้น ตรวจสอบให้แน่ใจว่าชื่อชุดแบบจำลองและสมาชิกตรงกับการกำหนดค่าที่คุณทำในแต่ละไฟล์กำหนดค่าก่อนหน้านี้
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })หากเมธอดส่งกลับค่า "ok": 1 ในเอาต์พุต แสดงว่าชุดเรพลิเคทเริ่มต้นอย่างถูกต้อง ด้านล่างนี้เป็นตัวอย่างของผลลัพธ์ที่ควรมีลักษณะดังนี้:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }ปิดเซิร์ฟเวอร์ MongoDB
คุณสามารถปิดเซิร์ฟเวอร์ MongoDB ได้โดยใช้เมธอด db.shutdownServer() ด้านล่างนี้เป็นไวยากรณ์สำหรับสิ่งเดียวกัน ทั้ง force และ timeoutsecs เป็นพารามิเตอร์ทางเลือก
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) วิธีนี้อาจล้มเหลวหากสมาชิกชุดแบบจำลอง mongod รันการดำเนินการบางอย่างเมื่อสร้างดัชนี หากต้องการขัดจังหวะการดำเนินการและบังคับให้สมาชิกปิดระบบ คุณสามารถป้อน force พารามิเตอร์บูลีนให้เป็นจริงได้
รีสตาร์ท MongoDB ด้วย –replSet
หากต้องการรีเซ็ตการกำหนดค่า ตรวจสอบให้แน่ใจว่าทุกโหนดในชุดเรพลิกาของคุณหยุดทำงาน จากนั้นลบฐานข้อมูลโลคัลสำหรับทุก ๆ โหนด เริ่มต้นอีกครั้งโดยใช้แฟล็ก –replSet และรัน rs.initiate() บนอินสแตนซ์ mongod เพียงตัวเดียวสำหรับชุดเรพพลิกา
mongod --replSet "rs0" rs.initiate() สามารถใช้เอกสารการกำหนดค่าชุดแบบจำลองเพิ่มเติม ได้แก่:
- ตัวเลือก
Replication.replSetNameหรือ—replSetเพื่อระบุชื่อชุดของแบบจำลองในช่อง_id - อาร์เรย์ของสมาชิกซึ่งมีหนึ่งเอกสารสำหรับแต่ละสมาชิกชุดเรพพลิกา
เมธอด rs.initiate() ทริกเกอร์การเลือกตั้งและเลือกสมาชิกคนใดคนหนึ่งให้เป็นสมาชิกหลัก
เพิ่มสมาชิกในชุดแบบจำลอง
หากต้องการเพิ่มสมาชิกในชุด ให้เริ่ม mongod instance บนเครื่องต่างๆ ถัดไป เริ่มไคลเอนต์ mongo และใช้คำสั่ง rs.add()
คำสั่ง rs.add() มีไวยากรณ์พื้นฐานดังต่อไปนี้:
rs.add(HOST_NAME:PORT)ตัวอย่างเช่น,
สมมติว่า mongo1 เป็นอินสแตนซ์ mongod ของคุณและกำลังฟังพอร์ต 27017 ใช้คำสั่งไคลเอ็นต์ Mongo rs.add() เพื่อเพิ่มอินสแตนซ์นี้ไปยังชุดเรพพลิกา

rs.add("mongo1:27017") หลังจากที่คุณเชื่อมต่อกับโหนดหลักแล้ว คุณจะสามารถเพิ่มอินสแตนซ์ mongod ไปยังชุดเรพลิกาได้ หากต้องการตรวจสอบว่าคุณเชื่อมต่อกับอุปกรณ์หลักหรือไม่ ให้ใช้คำสั่ง db.isMaster()
ลบผู้ใช้
หากต้องการลบสมาชิก เราสามารถใช้ rs.remove()
ในการทำเช่นนั้น ก่อนอื่นให้ปิดอินสแตนซ์ mongod ที่คุณต้องการลบโดยใช้เมธอด db.shutdownServer() ที่เรากล่าวถึงข้างต้น
ถัดไป เชื่อมต่อกับหลักปัจจุบันของชุดจำลอง ในการพิจารณาหลักปัจจุบัน ให้ใช้ db.hello() ในขณะที่เชื่อมต่อกับสมาชิกใดๆ ของชุดแบบจำลอง เมื่อคุณกำหนดคำสั่งหลักได้แล้ว ให้รันคำสั่งใดคำสั่งหนึ่งต่อไปนี้:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 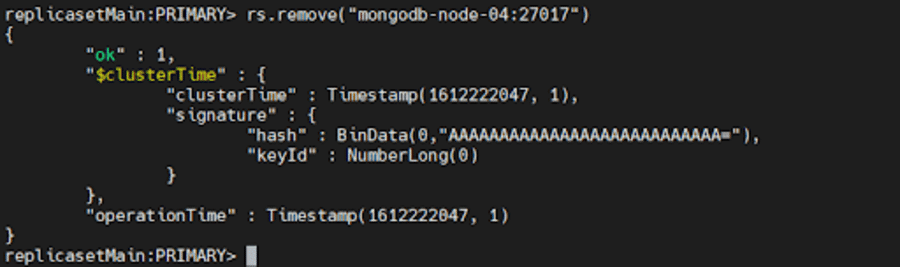
หากชุดจำลองจำเป็นต้องเลือกชุดหลักใหม่ MongoDB อาจยกเลิกการเชื่อมต่อเชลล์ในเวลาสั้นๆ ในสถานการณ์นี้ ระบบจะเชื่อมต่อใหม่อีกครั้งโดยอัตโนมัติ นอกจากนี้ อาจแสดงข้อผิดพลาด DBClientCursor::init call() ล้มเหลว แม้ว่าคำสั่งจะสำเร็จก็ตาม
วิธีที่ 2: การกำหนดค่าชุดแบบจำลอง MongoDB สำหรับการปรับใช้และการทดสอบ
โดยทั่วไป คุณสามารถตั้งค่าชุดแบบจำลองสำหรับการทดสอบโดยเปิดใช้งานหรือปิดใช้งาน RBAC ในวิธีนี้ เราจะตั้งค่าชุดจำลองโดยปิดใช้งานการควบคุมการเข้าถึงสำหรับการปรับใช้ในสภาพแวดล้อมการทดสอบ
ขั้นแรก สร้างไดเร็กทอรีสำหรับอินสแตนซ์ทั้งหมดที่เป็นส่วนหนึ่งของชุดเรพพลิกาโดยใช้คำสั่งต่อไปนี้:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2คำสั่งนี้จะสร้างไดเร็กทอรีสำหรับอินสแตนซ์ MongoDB สามรายการ replicaset0-0, replicaset0-1 และ replicaset0-2 ตอนนี้ เริ่มต้นอินสแตนซ์ MongoDB สำหรับแต่ละอินสแตนซ์โดยใช้ชุดคำสั่งต่อไปนี้:
สำหรับเซิร์ฟเวอร์ 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128สำหรับเซิร์ฟเวอร์ 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128สำหรับเซิร์ฟเวอร์ 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 พารามิเตอร์ –oplogSize ใช้เพื่อป้องกันไม่ให้เครื่องทำงานหนักเกินไปในระหว่างขั้นตอนการทดสอบ ช่วยลดจำนวนพื้นที่ดิสก์ที่แต่ละดิสก์ใช้
ตอนนี้ เชื่อมต่อกับหนึ่งในอินสแตนซ์โดยใช้ Mongo shell โดยเชื่อมต่อโดยใช้หมายเลขพอร์ตด้านล่าง
mongo --port 27017 เราสามารถใช้คำสั่ง rs.initiate() เพื่อเริ่มกระบวนการจำลองแบบ คุณจะต้องแทนที่พารามิเตอร์ hostname ด้วยชื่อระบบของคุณ
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }ตอนนี้คุณสามารถส่งไฟล์คอนฟิกูเรชันอ็อบเจ็กต์เป็นพารามิเตอร์สำหรับคำสั่ง initial และใช้ดังต่อไปนี้:
rs.initiate(rsconf)และคุณมีมัน! คุณสร้างชุดจำลอง MongoDB สำเร็จแล้วสำหรับวัตถุประสงค์ในการพัฒนาและทดสอบ
วิธีที่ 3: การแปลงอินสแตนซ์แบบสแตนด์อโลนเป็น MongoDB Replica Set
MongoDB อนุญาตให้ผู้ใช้แปลงอินสแตนซ์แบบสแตนด์อโลนเป็นชุดจำลอง ในขณะที่ส่วนใหญ่ใช้อินสแตนซ์แบบสแตนด์อโลนสำหรับขั้นตอนการทดสอบและการพัฒนา ชุดจำลองเป็นส่วนหนึ่งของสภาพแวดล้อมการใช้งานจริง
ในการเริ่มต้น เรามาปิดอินสแตนซ์ mongod โดยใช้คำสั่งต่อไปนี้:
db.adminCommand({"shutdown":"1"}) รีสตาร์ทอินสแตนซ์ของคุณโดยใช้พารามิเตอร์ –repelSet ในคำสั่งของคุณเพื่อระบุชุดเรพพลิกาที่คุณจะใช้:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>คุณต้องระบุชื่อเซิร์ฟเวอร์ของคุณพร้อมกับที่อยู่เฉพาะในคำสั่ง
เชื่อมต่อเชลล์กับอินสแตนซ์ MongoDB ของคุณแล้วใช้คำสั่ง initial เพื่อเริ่มกระบวนการจำลองและแปลงอินสแตนซ์เป็นชุดเรพลิกาได้สำเร็จ คุณสามารถดำเนินการพื้นฐานทั้งหมด เช่น การเพิ่มหรือลบอินสแตนซ์โดยใช้คำสั่งต่อไปนี้:
rs.add(“<host_name:port>”) rs.remove(“host-name”) นอกจากนี้ คุณสามารถตรวจสอบสถานะของชุดแบบจำลอง MongoDB โดยใช้คำสั่ง rs.status() และ rs.conf()
วิธีที่ 4: MongoDB Atlas — ทางเลือกที่ง่ายกว่า
การจำลองแบบและการชาร์ดดิ้งสามารถทำงานร่วมกันเพื่อสร้างสิ่งที่เรียกว่าคลัสเตอร์ที่ชาร์ด แม้ว่าการตั้งค่าและการกำหนดค่าอาจค่อนข้างใช้เวลานานแม้ว่าจะตรงไปตรงมา MongoDB Atlas เป็นทางเลือกที่ดีกว่าวิธีที่กล่าวถึงก่อนหน้านี้
มันทำให้ชุดเรพลิเคทของคุณเป็นไปโดยอัตโนมัติ ทำให้ง่ายต่อการใช้งาน สามารถปรับใช้ชุดจำลองแบบแบ่งส่วนได้ทั่วโลกด้วยการคลิกเพียงไม่กี่ครั้ง ทำให้สามารถกู้คืนจากภัยพิบัติ การจัดการที่ง่ายขึ้น data locality และการปรับใช้หลายภูมิภาค
ใน MongoDB Atlas เราจำเป็นต้องสร้างคลัสเตอร์ โดยอาจเป็นชุดจำลองหรือคลัสเตอร์ที่แยกส่วนก็ได้ สำหรับโปรเจ็กต์หนึ่งๆ จำนวนโหนดในคลัสเตอร์ในภูมิภาคอื่นๆ จะจำกัดไว้ที่ทั้งหมด 40 โหนด
ซึ่งไม่รวมคลัสเตอร์ฟรีหรือที่ใช้ร่วมกันและภูมิภาคคลาวด์ของ Google ที่สื่อสารระหว่างกัน จำนวนโหนดทั้งหมดระหว่างสองภูมิภาคต้องเป็นไปตามข้อจำกัดนี้ ตัวอย่างเช่น หากมีโครงการที่:
- ภูมิภาค A มี 15 โหนด
- ภูมิภาค B มี 25 โหนด
- ภูมิภาค C มี 10 โหนด
เราสามารถจัดสรรได้อีก 5 โหนดไปยังภูมิภาค C ดังนี้
- ภูมิภาค A+ ภูมิภาค B = 40; ตรงตามข้อจำกัด 40 ซึ่งเป็นจำนวนโหนดสูงสุดที่อนุญาต
- ภูมิภาค B+ ภูมิภาค C = 25+10+5 (โหนดเพิ่มเติมที่จัดสรรให้กับ C) = 40; ตรงตามข้อจำกัด 40 ซึ่งเป็นจำนวนโหนดสูงสุดที่อนุญาต
- ภูมิภาค A+ ภูมิภาค C =15+10+5 (โหนดเพิ่มเติมที่จัดสรรให้กับ C) = 30; ตรงตามข้อจำกัด 40 ซึ่งเป็นจำนวนโหนดสูงสุดที่อนุญาต
ถ้าเราจัดสรรอีก 10 โหนดให้กับภูมิภาค C ทำให้ภูมิภาค C มี 20 โหนด ดังนั้นภูมิภาค B + ภูมิภาค C = 45 โหนด ซึ่งจะเกินข้อจำกัดที่กำหนด ดังนั้นคุณจึงอาจไม่สามารถสร้างคลัสเตอร์หลายภูมิภาคได้
เมื่อคุณสร้างคลัสเตอร์ Atlas จะสร้างคอนเทนเนอร์เครือข่ายในโครงการสำหรับผู้ให้บริการระบบคลาวด์หากไม่เคยมีมาก่อน หากต้องการสร้างคลัสเตอร์ชุดแบบจำลองใน MongoDB Atlas ให้รันคำสั่งต่อไปนี้ใน Atlas CLI:
atlas clusters create [name] [options]ตรวจสอบให้แน่ใจว่าคุณได้ตั้งชื่อคลัสเตอร์ที่สื่อความหมาย เนื่องจากไม่สามารถเปลี่ยนแปลงได้หลังจากสร้างคลัสเตอร์แล้ว อาร์กิวเมนต์สามารถประกอบด้วยตัวอักษร ASCII ตัวเลข และยัติภังค์
มีหลายตัวเลือกสำหรับการสร้างคลัสเตอร์ใน MongoDB ตามความต้องการของคุณ ตัวอย่างเช่น หากคุณต้องการสำรองข้อมูลบนคลาวด์อย่างต่อเนื่องสำหรับคลัสเตอร์ ให้ตั้งค่า --backup เป็น true
การจัดการกับความล่าช้าในการจำลองแบบ
ความล่าช้าในการจำลองแบบอาจค่อนข้างไม่เหมาะสม เป็นการหน่วงเวลาระหว่างการดำเนินการกับการดำเนินการหลักและแอปพลิเคชันของการดำเนินการนั้นจาก oplog ไปยังการดำเนินการรอง หากธุรกิจของคุณเกี่ยวข้องกับชุดข้อมูลขนาดใหญ่ คาดว่าจะเกิดความล่าช้าภายในเกณฑ์ที่กำหนด อย่างไรก็ตาม บางครั้งปัจจัยภายนอกก็มีส่วนทำให้ความล่าช้าเพิ่มขึ้นเช่นกัน เพื่อรับประโยชน์จากการจำลองแบบล่าสุด ตรวจสอบให้แน่ใจว่า:
- คุณกำหนดเส้นทางการรับส่งข้อมูลเครือข่ายของคุณด้วยแบนด์วิธที่เสถียรและเพียงพอ เวลาแฝงของเครือข่ายมีบทบาทอย่างมากในการส่งผลต่อการจำลองแบบของคุณ และหากเครือข่ายไม่เพียงพอที่จะตอบสนองความต้องการของกระบวนการจำลองแบบ จะเกิดความล่าช้าในการจำลองข้อมูลตลอดทั้งชุดการจำลอง
- คุณมีปริมาณงานของดิสก์เพียงพอ หากระบบไฟล์และอุปกรณ์ดิสก์ในอุปกรณ์รองไม่สามารถล้างข้อมูลไปยังดิสก์ได้เร็วเท่ากับอุปกรณ์หลัก อุปกรณ์รองจะมีปัญหาในการดูแลรักษา ดังนั้น โหนดรองจึงประมวลผลเคียวรีการเขียนช้ากว่าโหนดหลัก นี่เป็นปัญหาทั่วไปในระบบหลายผู้เช่าส่วนใหญ่ รวมถึงอินสแตนซ์เสมือนจริงและการปรับใช้ขนาดใหญ่
- คุณร้องขอการรับทราบการเขียนข้อกังวลในการเขียนหลังจากช่วงเวลาหนึ่งเพื่อให้โอกาสสำหรับรองในการติดต่อกับหลัก โดยเฉพาะอย่างยิ่งเมื่อคุณต้องการดำเนินการโหลดจำนวนมากหรือการนำเข้าข้อมูลที่ต้องใช้การเขียนจำนวนมากไปยังหลัก หน่วยรองจะไม่สามารถอ่าน oplog ได้เร็วพอที่จะติดตามการเปลี่ยนแปลงได้ โดยเฉพาะอย่างยิ่งกับข้อกังวลในการเขียนที่ไม่รับทราบ
- คุณระบุงานพื้นหลังที่กำลังทำงานอยู่ งานบางอย่าง เช่น งาน cron การอัปเดตเซิร์ฟเวอร์ และการตรวจสอบความปลอดภัย อาจมีผลกระทบที่ไม่คาดคิดต่อเครือข่ายหรือการใช้งานดิสก์ ทำให้เกิดความล่าช้าในกระบวนการจำลองแบบ
หากคุณไม่แน่ใจว่ามี Replication Lag ในแอปพลิเคชันของคุณหรือไม่ อย่าเพิ่งกังวลไป – ส่วนถัดไปจะกล่าวถึงกลยุทธ์การแก้ปัญหา!
การแก้ไขปัญหา MongoDB Replica Sets
คุณตั้งค่าชุดแบบจำลองสำเร็จแล้ว แต่คุณสังเกตเห็นว่าข้อมูลของคุณไม่สอดคล้องกันในเซิร์ฟเวอร์ต่างๆ นี่เป็นเรื่องที่น่าตกใจอย่างยิ่งสำหรับธุรกิจขนาดใหญ่ อย่างไรก็ตาม ด้วยวิธีการแก้ไขปัญหาอย่างรวดเร็ว คุณอาจพบสาเหตุหรือแม้แต่แก้ไขปัญหาได้! ด้านล่างเป็นกลยุทธ์ทั่วไปสำหรับการแก้ไขปัญหาการปรับใช้ชุดแบบจำลองที่อาจมีประโยชน์:
ตรวจสอบสถานะแบบจำลอง
เราสามารถตรวจสอบสถานะปัจจุบันของชุดแบบจำลองและสถานะของสมาชิกแต่ละตัวได้โดยการรันคำสั่งต่อไปนี้ในเซสชัน mongosh ที่เชื่อมต่อกับชุดหลักของชุดแบบจำลอง
rs.status()ตรวจสอบ Replication Lag
ดังที่ได้กล่าวไว้ก่อนหน้านี้ ความล่าช้าของการจำลองอาจเป็นปัญหาร้ายแรงเนื่องจากทำให้สมาชิกที่ "ล้าหลัง" ไม่มีสิทธิ์กลายเป็นหลักได้อย่างรวดเร็ว และเพิ่มความเป็นไปได้ที่การดำเนินการอ่านแบบกระจายจะไม่สอดคล้องกัน เราสามารถตรวจสอบความยาวปัจจุบันของบันทึกการจำลองได้โดยใช้คำสั่งต่อไปนี้:
rs.printSecondaryReplicationInfo() ซึ่งจะส่งคืนค่า syncedTo ซึ่งเป็นเวลาที่รายการ oplog ล่าสุดเขียนไปยังรายการรองสำหรับสมาชิกแต่ละคน ต่อไปนี้คือตัวอย่างที่แสดงให้เห็นสิ่งเดียวกัน:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary สมาชิกที่ล่าช้าอาจแสดงเป็น 0 วินาทีหลังสมาชิกหลักเมื่อระยะเวลาที่ไม่มีการใช้งานในสมาชิกหลักมากกว่าค่า members[n].secondaryDelaySecs
ทดสอบการเชื่อมต่อระหว่างสมาชิกทั้งหมด
สมาชิกแต่ละตัวของชุดเรพลิกาต้องสามารถเชื่อมต่อกับสมาชิกอื่นๆ ได้ทุกตัว ตรวจสอบให้แน่ใจเสมอว่าได้ตรวจสอบการเชื่อมต่อทั้งสองทิศทางแล้ว ส่วนใหญ่แล้ว การกำหนดค่าไฟร์วอลล์หรือโทโพโลยีเครือข่ายจะป้องกันการเชื่อมต่อปกติและที่จำเป็น ซึ่งสามารถบล็อกการจำลองแบบได้
ตัวอย่างเช่น สมมติว่าอินสแตนซ์ mongod เชื่อมโยงกับ localhost และชื่อโฮสต์ 'ExampleHostname' ซึ่งเชื่อมโยงกับที่อยู่ IP 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnameในการเชื่อมต่อกับอินสแตนซ์นี้ ไคลเอนต์ระยะไกลต้องระบุชื่อโฮสต์หรือที่อยู่ IP:
mongosh --host ExampleHostname mongosh --host 198.41.110.1หากชุดเรพพลิกาประกอบด้วยสมาชิกสามตัว ได้แก่ m1, m2 และ m3 โดยใช้พอร์ตดีฟอลต์ 27017 คุณควรทดสอบการเชื่อมต่อดังต่อไปนี้:
บน m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017บน m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017บน m3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 หากการเชื่อมต่อในทิศทางใดก็ตามล้มเหลว คุณจะต้องตรวจสอบการกำหนดค่าไฟร์วอลล์และกำหนดค่าใหม่เพื่ออนุญาตการเชื่อมต่อ
มั่นใจได้ถึงการสื่อสารที่ปลอดภัยด้วยการตรวจสอบความถูกต้องของไฟล์คีย์
ตามค่าเริ่มต้น การพิสูจน์ตัวตนไฟล์คีย์ใน MongoDB อาศัยกลไกการพิสูจน์ตัวตนการตอบสนองความท้าทายแบบเค็ม (SCRAM) ในการทำเช่นนี้ MongoDB ต้องอ่านและตรวจสอบความถูกต้องของข้อมูลประจำตัวที่ผู้ใช้ให้มา ซึ่งรวมถึงชื่อผู้ใช้ รหัสผ่าน และฐานข้อมูลการตรวจสอบสิทธิ์ที่อินสแตนซ์ MongoDB ทราบ นี่เป็นกลไกที่ใช้ในการรับรองความถูกต้องของผู้ใช้ที่ให้รหัสผ่านเมื่อเชื่อมต่อกับฐานข้อมูล
เมื่อคุณเปิดใช้งานการพิสูจน์ตัวตนใน MongoDB การควบคุมการเข้าถึงตามบทบาท (RBAC) จะถูกเปิดใช้งานโดยอัตโนมัติสำหรับชุดเรพพลิกา และผู้ใช้จะได้รับบทบาทตั้งแต่หนึ่งบทบาทขึ้นไปที่กำหนดการเข้าถึงทรัพยากรฐานข้อมูล เมื่อเปิดใช้งาน RBAC หมายความว่าเฉพาะผู้ใช้ Mongo ที่ผ่านการรับรองความถูกต้องและมีสิทธิ์ที่เหมาะสมเท่านั้นที่จะสามารถเข้าถึงทรัพยากรบนระบบได้
ไฟล์คีย์ทำหน้าที่เหมือนรหัสผ่านที่ใช้ร่วมกันสำหรับสมาชิกแต่ละคนในคลัสเตอร์ สิ่งนี้ทำให้แต่ละอินสแตนซ์ของ mongod ในชุดเรพลิกาสามารถใช้เนื้อหาของไฟล์คีย์เป็นรหัสผ่านที่ใช้ร่วมกันสำหรับการรับรองความถูกต้องของสมาชิกรายอื่นในการปรับใช้
เฉพาะอินสแตนซ์ mongod ที่มีคีย์ไฟล์ที่ถูกต้องเท่านั้นที่สามารถเข้าร่วมชุดจำลองได้ ความยาวของคีย์ต้องอยู่ระหว่าง 6 ถึง 1,024 อักขระ และอาจมีได้เฉพาะอักขระในชุดฐาน 64 โปรดทราบว่า MongoDB จะตัดอักขระช่องว่างเมื่ออ่านคีย์
คุณสามารถ สร้างไฟล์คีย์ โดยใช้วิธีการต่างๆ ในบทช่วยสอนนี้ เราใช้ openssl เพื่อสร้างสตริงอักขระสุ่ม 1024 ตัวที่ซับซ้อนเพื่อใช้เป็นรหัสผ่านที่ใช้ร่วมกัน จากนั้นใช้ chmod เพื่อเปลี่ยนสิทธิ์ของไฟล์เพื่อให้สิทธิ์การอ่านสำหรับเจ้าของไฟล์เท่านั้น Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. ตัวอย่างเช่น:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
และ voila! You have successfully enabled keyfile authentication!
สรุป
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? แจ้งให้เราทราบในส่วนความคิดเห็นด้านล่าง!