
Robots.txt: คืออะไรและจะสร้างได้อย่างไร (คู่มือฉบับสมบูรณ์)
เผยแพร่แล้ว: 2023-05-05หากคุณเป็นเจ้าของเว็บไซต์หรือจัดการเนื้อหาของเว็บไซต์ คุณอาจเคยได้ยินคำว่า robots.txt เป็นไฟล์ที่แนะนำโรบ็อตเครื่องมือค้นหาเกี่ยวกับวิธีรวบรวมข้อมูลและจัดทำดัชนีหน้าเว็บไซต์ของคุณ แม้จะมีความสำคัญในการปรับแต่งเว็บไซต์ให้ติดอันดับบนเครื่องมือการค้นหา (SEO) แต่เจ้าของเว็บไซต์จำนวนมากกลับมองข้ามความสำคัญของไฟล์ robots.txt ที่ออกแบบมาอย่างดี
ในคำแนะนำฉบับสมบูรณ์นี้ เราจะสำรวจว่า robots.txt คืออะไร เหตุใดจึงมีความสำคัญต่อ SEO และวิธีสร้างไฟล์ robots.txt สำหรับเว็บไซต์ของคุณ
ไฟล์ Robots.txt คืออะไร?
ไฟล์ robots.txt คือไฟล์ที่บอกโรบ็อตของเครื่องมือค้นหา (หรือที่เรียกว่าโปรแกรมรวบรวมข้อมูลหรือสไปเดอร์) ว่าหน้าหรือส่วนใดของเว็บไซต์ควรได้รับการรวบรวมข้อมูลหรือไม่ ไฟล์นี้เป็นไฟล์ข้อความธรรมดาที่อยู่ในไดเรกทอรีรากของเว็บไซต์ และโดยทั่วไปจะมีรายการไดเรกทอรี ไฟล์ หรือ URL ที่ผู้ดูแลเว็บต้องการบล็อกไม่ให้สร้างดัชนีหรือรวบรวมข้อมูลของเครื่องมือค้นหา
นี่คือลักษณะของไฟล์ robots.txt:

เหตุใด Robots.txt จึงมีความสำคัญ
มีเหตุผลหลักสามประการที่ทำให้ robots.txt มีความสำคัญต่อเว็บไซต์ของคุณ:
1. เพิ่มงบประมาณการรวบรวมข้อมูลให้สูงสุด
"งบประมาณการรวบรวมข้อมูล" หมายถึงจำนวนหน้าเว็บที่ Google จะรวบรวมข้อมูลในไซต์ของคุณ ณ เวลาใดเวลาหนึ่ง จำนวนจะขึ้นอยู่กับขนาด ความสมบูรณ์ และปริมาณของลิงก์ย้อนกลับบนไซต์ของคุณ
งบประมาณการรวบรวมข้อมูลมีความสำคัญ เนื่องจากหากจำนวนหน้าเว็บในไซต์ของคุณเกินงบประมาณการรวบรวมข้อมูล คุณจะมีหน้าเว็บที่ไม่ได้รับการจัดทำดัชนี
นอกจากนี้ เพจที่ไม่ได้จัดทำดัชนีจะไม่ติดอันดับใดๆ
เมื่อใช้ robots.txt เพื่อบล็อกหน้าเว็บที่ไม่มีประโยชน์ Googlebot (โปรแกรมรวบรวมข้อมูลเว็บของ Google) อาจใช้งบประมาณในการรวบรวมข้อมูลของคุณมากขึ้นในหน้าเว็บที่สำคัญ
2. บล็อกหน้าที่ไม่ใช่สาธารณะ
คุณมีหลายหน้าในไซต์ของคุณที่คุณไม่ต้องการทำดัชนี
ตัวอย่างเช่น คุณอาจมีหน้าผลการค้นหาภายในหรือหน้าเข้าสู่ระบบ หน้าเหล่านี้จำเป็นต้องมีอยู่ อย่างไรก็ตาม คุณคงไม่อยากให้คนสุ่มเข้ามาหาพวกเขา
ในกรณีนี้ คุณควรใช้ robots.txt เพื่อป้องกันไม่ให้โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาและบ็อตเข้าถึงหน้าบางหน้า
3. ป้องกันการจัดทำดัชนีทรัพยากร
บางครั้งคุณอาจต้องการให้ Google ไม่รวมทรัพยากรต่างๆ เช่น PDF, วิดีโอ และรูปภาพจากผลการค้นหา
คุณอาจต้องการเก็บทรัพยากรเหล่านั้นไว้เป็นส่วนตัว หรือต้องการให้ Google ให้ความสำคัญกับเนื้อหาที่สำคัญมากขึ้น
ในกรณีดังกล่าว การใช้ robots.txt เป็นวิธีที่ดีที่สุดในการป้องกันไม่ให้มีการจัดทำดัชนี
ไฟล์ Robots.txt ทำงานอย่างไร
ไฟล์ Robots.txt สั่งให้บอทเครื่องมือค้นหาหน้าหรือไดเร็กทอรีของเว็บไซต์ที่ควรหรือไม่ควรรวบรวมข้อมูลหรือจัดทำดัชนี
ขณะรวบรวมข้อมูล บอทของเครื่องมือค้นหาจะค้นหาและติดตามลิงก์ กระบวนการนี้นำพวกเขาจากไซต์ X ไปยังไซต์ Y ไปยังไซต์ Z กว่าพันล้านลิงก์และเว็บไซต์
เมื่อบอทเยี่ยมชมไซต์ สิ่งแรกที่บอทจะทำคือมองหาไฟล์ robots.txt
หากตรวจพบไฟล์จะอ่านไฟล์ก่อนที่จะทำสิ่งอื่นใด
ตัวอย่างเช่น สมมติว่าคุณต้องการอนุญาตให้บอททั้งหมดยกเว้น DuckDuckGo รวบรวมข้อมูลไซต์ของคุณ:
User-agent: DuckDuckBot Disallow: /
หมายเหตุ: ไฟล์ robots.txt สามารถให้คำแนะนำได้เท่านั้น มันไม่สามารถบังคับพวกเขาได้ มันคล้ายกับจรรยาบรรณ บอทที่ดี (เช่น บอทเครื่องมือค้นหา) จะปฏิบัติตามกฎ ในขณะที่บอทที่ไม่ดี (เช่น บอทสแปม) จะไม่สนใจพวกมัน
วิธีค้นหาไฟล์ Robots.txt
ไฟล์ robots.txt เช่นเดียวกับไฟล์อื่นๆ ในเว็บไซต์ของคุณ โฮสต์บนเซิร์ฟเวอร์ของคุณ
คุณสามารถเข้าถึงไฟล์ robots.txt ของเว็บไซต์ใดก็ได้โดยป้อน URL ที่สมบูรณ์ของหน้าแรก แล้วเพิ่ม /robots.txt ที่ท้าย เช่น https://pickupwp.com/robots.txt
อย่างไรก็ตาม หากเว็บไซต์ไม่มีไฟล์ robots.txt คุณจะได้รับข้อความแสดงข้อผิดพลาด "404 Not Found"
วิธีสร้างไฟล์ Robots.txt
ก่อนที่จะแสดงวิธีสร้างไฟล์ robots.txt เรามาดูไวยากรณ์ของ robots.txt กันก่อน
ไวยากรณ์ของไฟล์ robots.txt สามารถแบ่งออกเป็นองค์ประกอบต่อไปนี้:
- User-agent: ตัวเลือกนี้ระบุโรบ็อตหรือโปรแกรมรวบรวมข้อมูลที่เรกคอร์ดนำไปใช้ ตัวอย่างเช่น "User-agent: Googlebot" จะใช้เฉพาะกับโปรแกรมรวบรวมข้อมูลการค้นหาของ Google ในขณะที่ "User-agent: *" จะใช้กับโปรแกรมรวบรวมข้อมูลทั้งหมด
- ไม่อนุญาต: ระบุหน้าหรือไดเร็กทอรีที่โรบ็อตไม่ควรรวบรวมข้อมูล ตัวอย่างเช่น "ไม่อนุญาต: /private/" จะป้องกันไม่ให้โรบ็อตรวบรวมข้อมูลหน้าใดๆ ภายในไดเร็กทอรี "ส่วนตัว"
- อนุญาต: ระบุหน้าหรือไดเร็กทอรีที่โรบ็อตควรได้รับอนุญาตให้รวบรวมข้อมูล แม้ว่าไดเร็กทอรีหลักจะไม่ได้รับอนุญาตก็ตาม ตัวอย่างเช่น "อนุญาต: /public/" จะอนุญาตให้โรบ็อตรวบรวมข้อมูลหน้าใดๆ ภายในไดเรกทอรี "สาธารณะ" แม้ว่าไดเรกทอรีหลักจะไม่ได้รับอนุญาตก็ตาม
- ความล่าช้าในการรวบรวมข้อมูล: ค่านี้ระบุระยะเวลาเป็นวินาทีที่โรบ็อตควรรอก่อนที่จะรวบรวมข้อมูลเว็บไซต์ ตัวอย่างเช่น "การรวบรวมข้อมูลล่าช้า: 10" จะสั่งให้โรบ็อตรอเป็นเวลา 10 วินาทีก่อนที่จะรวบรวมข้อมูลเว็บไซต์
- แผนผังไซต์: สิ่งนี้ระบุตำแหน่งของแผนผังไซต์ของเว็บไซต์ ตัวอย่างเช่น “แผนผังไซต์: https://www.example.com/sitemap.xml” จะแจ้งให้โรบ็อตทราบถึงตำแหน่งของแผนผังไซต์ของเว็บไซต์
นี่คือตัวอย่างของไฟล์ robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
หมายเหตุ: สิ่งสำคัญคือต้องทราบว่าไฟล์ robots.txt คำนึงถึงตัวพิมพ์เล็กและใหญ่ ดังนั้นการใช้ตัวพิมพ์เล็กและตัวพิมพ์ที่ถูกต้องจึงเป็นสิ่งสำคัญเมื่อระบุ URL
ตัวอย่างเช่น /public/ ไม่เหมือนกับ /Public/
ในทางกลับกัน คำสั่งอย่างเช่น “อนุญาต” และ “ไม่อนุญาต” นั้นไม่คำนึงถึงตัวพิมพ์เล็กและใหญ่ ดังนั้นจึงขึ้นอยู่กับคุณว่าจะใช้ตัวพิมพ์ใหญ่เป็นตัวพิมพ์ใหญ่หรือไม่
หลังจากเรียนรู้เกี่ยวกับไวยากรณ์ของ robots.txt แล้ว คุณสามารถสร้างไฟล์ robots.txt โดยใช้เครื่องมือสร้าง robots.txt หรือสร้างขึ้นเอง
ต่อไปนี้เป็นวิธีสร้างไฟล์ robots.txt ในสี่ขั้นตอน:
1. สร้างไฟล์ใหม่และตั้งชื่อว่า Robots.txt
เพียงแค่เปิดเอกสาร .txt ด้วยโปรแกรมแก้ไขข้อความหรือเว็บเบราว์เซอร์
ต่อไป ให้ตั้งชื่อเอกสารว่า robots.txt ในการทำงาน ต้องตั้งชื่อว่า robots.txt
เมื่อเสร็จแล้ว คุณสามารถเริ่มพิมพ์คำสั่งได้เลย
2. เพิ่มคำสั่งให้กับไฟล์ Robots.txt
ไฟล์ robots.txt มีกลุ่มคำสั่งตั้งแต่หนึ่งกลุ่มขึ้นไป แต่ละกลุ่มมีคำสั่งหลายบรรทัด
แต่ละกลุ่มเริ่มต้นด้วย “User-agent” และประกอบด้วยข้อมูลต่อไปนี้:
- กลุ่มนำไปใช้กับใคร (ตัวแทนผู้ใช้)
- ไดเร็กทอรี (เพจ) หรือไฟล์ใดที่เอเจนต์สามารถเข้าถึง
- ไดเร็กทอรี (หน้า) หรือไฟล์ใดที่เอเจนต์ไม่สามารถเข้าถึงได้
- แผนผังไซต์ (ไม่บังคับ) เพื่อแจ้งให้เครื่องมือค้นหาทราบเกี่ยวกับไซต์และไฟล์ที่คุณเชื่อว่ามีความสำคัญ
บรรทัดที่ไม่ตรงกับคำสั่งใด ๆ เหล่านี้จะถูกละเว้นโดยโปรแกรมรวบรวมข้อมูล

ตัวอย่างเช่น คุณต้องการป้องกันไม่ให้ Google รวบรวมข้อมูลไดเรกทอรี /private/ ของคุณ
มันจะมีลักษณะดังนี้:
User-agent: Googlebot Disallow: /private/
หากคุณมีคำแนะนำเพิ่มเติมเช่นนี้สำหรับ Google คุณจะต้องใส่ไว้ในบรรทัดแยกต่างหากด้านล่างดังนี้:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
นอกจากนี้ หากคุณทำตามคำแนะนำเฉพาะของ Google เสร็จแล้ว และต้องการสร้างกลุ่มคำสั่งใหม่
ตัวอย่างเช่น หากคุณต้องการป้องกันไม่ให้เครื่องมือค้นหาทั้งหมดรวบรวมข้อมูลไดเรกทอรี /archive/ และ /support/ ของคุณ
มันจะมีลักษณะดังนี้:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
เมื่อเสร็จแล้ว คุณสามารถเพิ่มแผนผังไซต์ของคุณได้
ไฟล์ robots.txt ที่เสร็จสมบูรณ์ของคุณควรมีลักษณะดังนี้:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
ถัดไป บันทึกไฟล์ robots.txt ของคุณ โปรดจำไว้ว่าจะต้องตั้งชื่อว่า robots.txt
สำหรับกฎของ robots.txt ที่มีประโยชน์เพิ่มเติม โปรดดูคำแนะนำที่มีประโยชน์นี้จาก Google
3. อัปโหลดไฟล์ Robots.txt
หลังจากบันทึกไฟล์ robots.txt ลงในคอมพิวเตอร์แล้ว ให้อัปโหลดไปยังเว็บไซต์ของคุณและทำให้เครื่องมือค้นหารวบรวมข้อมูลได้
น่าเสียดายที่ไม่มีเครื่องมือใดที่สามารถช่วยในขั้นตอนนี้ได้
การอัปโหลดไฟล์ robots.txt ขึ้นอยู่กับโครงสร้างไฟล์และเว็บโฮสติ้งของเว็บไซต์คุณ
สำหรับคำแนะนำเกี่ยวกับวิธีอัปโหลดไฟล์ robots.txt ให้ค้นหาทางออนไลน์หรือติดต่อผู้ให้บริการโฮสติ้งของคุณ
4. ทดสอบ Robots.txt ของคุณ
หลังจากที่คุณอัปโหลดไฟล์ robots.txt แล้ว ต่อไป คุณสามารถตรวจสอบได้ว่ามีใครเห็นหรือไม่ และ Google สามารถอ่านได้หรือไม่
เพียงเปิดแท็บใหม่ในเบราว์เซอร์แล้วค้นหาไฟล์ robots.txt
ตัวอย่างเช่น https://pickupwp.com/robots.txt
หากคุณเห็นไฟล์ robots.txt แสดงว่าคุณพร้อมที่จะทดสอบมาร์กอัป (โค้ด HTML)
สำหรับสิ่งนี้ คุณสามารถใช้ตัวทดสอบ Google robots.txt
หมายเหตุ: คุณได้ตั้งค่าบัญชี Search Console เพื่อทดสอบไฟล์ robots.txt โดยใช้โปรแกรมทดสอบ robots.txt
เครื่องมือทดสอบ robots.txt จะค้นหาคำเตือนเกี่ยวกับไวยากรณ์หรือข้อผิดพลาดทางลอจิกและไฮไลต์
นอกจากนี้ยังแสดงคำเตือนและข้อผิดพลาดด้านล่างตัวแก้ไข
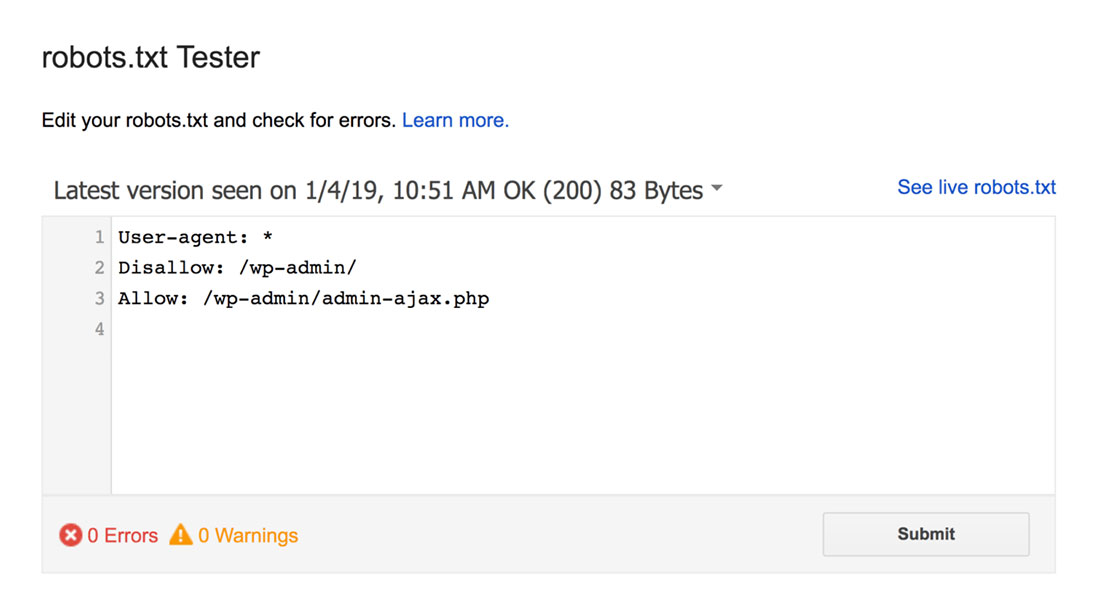
คุณสามารถแก้ไขข้อผิดพลาดหรือคำเตือนบนเพจและทดสอบซ้ำได้บ่อยเท่าที่จำเป็น
โปรดทราบว่าการเปลี่ยนแปลงที่เกิดขึ้นบนหน้าจะไม่ถูกบันทึกลงในไซต์ของคุณ
หากต้องการทำการเปลี่ยนแปลงใดๆ ให้คัดลอกและวางสิ่งนี้ลงในไฟล์ robots.txt ของไซต์ของคุณ
แนวทางปฏิบัติที่ดีที่สุดของ Robots.txt
คำนึงถึงแนวทางปฏิบัติที่ดีที่สุดเหล่านี้ในขณะที่สร้างไฟล์ robots.txt เพื่อหลีกเลี่ยงข้อผิดพลาดทั่วไป
1. ใช้บรรทัดใหม่สำหรับแต่ละคำสั่ง
เพื่อป้องกันความสับสนสำหรับโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหา ให้เพิ่มแต่ละคำสั่งไปยังบรรทัดใหม่ในไฟล์ robots.txt ของคุณ สิ่งนี้ใช้กับทั้งกฎอนุญาตและไม่อนุญาตให้ใช้
ตัวอย่างเช่น หากคุณไม่ต้องการให้โปรแกรมรวบรวมข้อมูลเว็บรวบรวมข้อมูลบล็อกหรือหน้าติดต่อของคุณ ให้เพิ่มกฎต่อไปนี้:
Disallow: /blog/ Disallow: /contact/
2. ใช้ User Agent แต่ละคนเพียงครั้งเดียว
บอทจะไม่มีปัญหาหากคุณใช้ตัวแทนผู้ใช้เดิมซ้ำแล้วซ้ำอีก
อย่างไรก็ตาม การใช้เพียงครั้งเดียวจะช่วยจัดระเบียบสิ่งต่างๆ และลดโอกาสที่จะเกิดข้อผิดพลาดจากมนุษย์
3. ใช้สัญลักษณ์แทนเพื่อทำให้คำแนะนำง่ายขึ้น
หากคุณมีเพจจำนวนมากที่ต้องบล็อก การเพิ่มกฎสำหรับแต่ละเพจอาจใช้เวลานาน โชคดีที่คุณอาจใช้สัญลักษณ์แทนเพื่อทำให้คำสั่งของคุณง่ายขึ้น
อักขระตัวแทนคืออักขระที่สามารถแทนอักขระหนึ่งตัวหรือมากกว่า สัญลักษณ์แทนที่ใช้บ่อยที่สุดคือเครื่องหมายดอกจัน (*)
ตัวอย่างเช่น หากคุณต้องการบล็อกไฟล์ทั้งหมดที่ลงท้ายด้วย .jpg คุณต้องเพิ่มกฎต่อไปนี้:
Disallow: /*.jpg
4. ใช้ “$” เพื่อระบุจุดสิ้นสุดของ URL
เครื่องหมายดอลลาร์ ($) เป็นสัญลักษณ์ตัวแทนอื่นที่อาจใช้เพื่อระบุจุดสิ้นสุดของ URL สิ่งนี้มีประโยชน์หากคุณต้องการจำกัดหน้าใดหน้าหนึ่ง แต่ไม่ต้องการจำกัดหน้าถัดไป
สมมติว่าคุณต้องการบล็อกหน้าติดต่อแต่ไม่ต้องการบล็อกหน้าติดต่อสำเร็จ คุณต้องเพิ่มกฎต่อไปนี้:
Disallow: /contact$
5. ใช้แฮช (#) เพื่อเพิ่มความคิดเห็น
ทุกสิ่งที่ขึ้นต้นด้วยแฮช (#) จะถูกละเว้นโดยโปรแกรมรวบรวมข้อมูล
ด้วยเหตุนี้ นักพัฒนามักใช้แฮชเพื่อเพิ่มความคิดเห็นในไฟล์ robots.txt ทำให้เอกสารเป็นระเบียบและน่าอ่าน
ตัวอย่างเช่น หากคุณต้องการป้องกันไม่ให้ไฟล์ทั้งหมดที่ลงท้ายด้วย .jpg คุณอาจเพิ่มความคิดเห็นต่อไปนี้:
# Block all files that end in .jpg Disallow: /*.jpg
สิ่งนี้ช่วยให้ทุกคนเข้าใจว่ากฎมีไว้เพื่ออะไรและทำไมจึงมี
6. ใช้ไฟล์ Robots.txt แยกกันสำหรับแต่ละโดเมนย่อย
หากคุณมีเว็บไซต์ที่มีโดเมนย่อยหลายโดเมน ขอแนะนำให้สร้างไฟล์ robots.txt แต่ละไฟล์สำหรับแต่ละโดเมน สิ่งนี้ช่วยจัดระเบียบสิ่งต่าง ๆ และช่วยให้โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาเข้าใจกฎของคุณได้ง่ายขึ้น
ห่อ!
ไฟล์ robots.txt เป็นเครื่องมือ SEO ที่มีประโยชน์ เนื่องจากมันสั่งให้บอทของเครื่องมือค้นหารู้ว่าสิ่งใดควรทำดัชนีและสิ่งใดไม่ควรทำดัชนี
อย่างไรก็ตาม สิ่งสำคัญคือต้องใช้ด้วยความระมัดระวัง เนื่องจากการกำหนดค่าผิดอาจส่งผลให้เว็บไซต์ของคุณไม่มีการจัดทำดัชนีโดยสมบูรณ์ (เช่น การใช้ Disallow: /)
โดยทั่วไป วิธีที่ดีคือการอนุญาตให้เครื่องมือค้นหาสแกนไซต์ของคุณมากที่สุดเท่าที่จะเป็นไปได้ ในขณะที่เก็บข้อมูลที่ละเอียดอ่อนและหลีกเลี่ยงเนื้อหาที่ซ้ำกัน ตัวอย่างเช่น คุณอาจใช้คำสั่ง Disallow เพื่อป้องกันไม่ให้หน้าหรือไดเร็กทอรีที่ระบุ หรือคำสั่ง Allow เพื่อแทนที่กฎ Disallow สำหรับหน้าใดหน้าหนึ่ง
นอกจากนี้ยังควรกล่าวถึงด้วยว่าไม่ใช่บอททุกตัวที่ปฏิบัติตามกฎที่ให้ไว้ในไฟล์ robots.txt ดังนั้นจึงไม่ใช่วิธีที่สมบูรณ์แบบสำหรับการควบคุมสิ่งที่ได้รับการจัดทำดัชนี แต่ก็ยังเป็นเครื่องมือที่มีค่าในกลยุทธ์ SEO ของคุณ
เราหวังว่าคำแนะนำนี้จะช่วยให้คุณเรียนรู้ว่าไฟล์ robots.txt คืออะไรและจะสร้างไฟล์ได้อย่างไร
สำหรับข้อมูลเพิ่มเติม คุณสามารถดูแหล่งข้อมูลที่เป็นประโยชน์อื่นๆ เหล่านี้:
- 15 เคล็ดลับการเขียนบล็อกที่นำไปใช้ได้จริงสำหรับบล็อกเกอร์มือใหม่
- ปลดล็อกพลังของคำหลักหางยาว (คู่มือเริ่มต้น)
สุดท้าย ติดตามเราบน Twitter สำหรับการอัปเดตบทความใหม่เป็นประจำ