
ไฟล์ WordPress robots.txt… มันคืออะไรและทำงานอย่างไร
เผยแพร่แล้ว: 2020-11-25คุณเคยสงสัยหรือไม่ว่าไฟล์ robots.txt คืออะไรและทำอะไร? Robots.txt ใช้เพื่อสื่อสารกับโปรแกรมรวบรวมข้อมูลเว็บ (เรียกว่าบอท) ที่ใช้โดย Google และเครื่องมือค้นหาอื่นๆ มันบอกพวกเขาว่าส่วนใดของเว็บไซต์ของคุณที่จะจัดทำดัชนีและส่วนใดที่ไม่ควรมองข้าม ดังนั้นไฟล์ robots.txt จึงสามารถช่วยสร้าง (หรืออาจทำลาย!) ความพยายาม SEO ของคุณ หากคุณต้องการให้เว็บไซต์ของคุณมีอันดับที่ดี ความเข้าใจที่ดีเกี่ยวกับ robots.txt เป็นสิ่งสำคัญ!
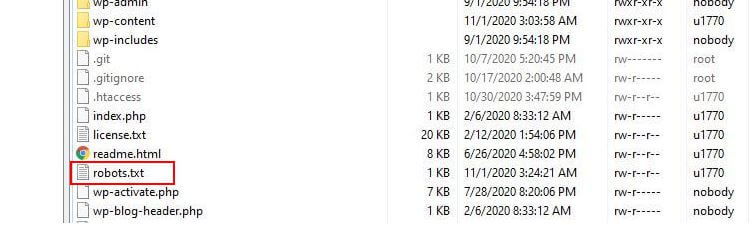
Robots.txt ตั้งอยู่ที่ไหน
โดยทั่วไป WordPress จะเรียกใช้ไฟล์ robots.txt ที่เรียกว่า 'เสมือน' ซึ่งหมายความว่าไม่สามารถเข้าถึงได้ผ่าน SFTP อย่างไรก็ตาม คุณสามารถดูเนื้อหาพื้นฐานได้โดยไปที่ yourdomain.com/robots.txt คุณอาจจะเห็นสิ่งนี้:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpบรรทัดแรกระบุว่ากฎจะใช้กับบอทใด ในตัวอย่างของเรา เครื่องหมายดอกจันหมายความว่ากฎนี้จะมีผลกับบ็อตทั้งหมด (เช่น บอทจาก Google, Bing เป็นต้น)
บรรทัดที่สองกำหนดกฎที่ป้องกันการเข้าถึงโดยบอทไปยังโฟลเดอร์ /wp-admin และบรรทัดที่สามระบุว่าบอทได้รับอนุญาตให้แยกวิเคราะห์ไฟล์ /wp-admin/admin-ajax.php
เพิ่มกฎของคุณเอง
สำหรับเว็บไซต์ WordPress ทั่วไป กฎเริ่มต้นที่ WordPress ใช้กับไฟล์ robots.txt อาจเพียงพอแล้ว อย่างไรก็ตาม หากคุณต้องการการควบคุมที่มากขึ้นและความสามารถในการเพิ่มกฎของคุณเองเพื่อให้คำแนะนำเฉพาะเจาะจงมากขึ้นแก่บอทของเครื่องมือค้นหาเกี่ยวกับวิธีการสร้างดัชนีเว็บไซต์ของคุณ คุณจะต้องสร้างไฟล์ robots.txt จริงและวางไว้ใต้รูท ไดเร็กทอรีของการติดตั้งของคุณ
มีเหตุผลหลายประการที่อาจต้องการกำหนดค่าไฟล์ robots.txt ใหม่ และกำหนดว่าบอทเหล่านั้นจะได้รับอนุญาตให้รวบรวมข้อมูลอย่างไร เหตุผลสำคัญประการหนึ่งคือการใช้เวลาที่บอทรวบรวมข้อมูลไซต์ของคุณ Google (และอื่น ๆ ) ไม่อนุญาตให้บ็อตใช้เวลาไม่จำกัดเวลากับทุกเว็บไซต์... ด้วยจำนวนหน้าหลายล้านหน้าที่พวกเขาต้องใช้แนวทางที่เหมาะสมยิ่งขึ้นกับสิ่งที่บอทจะรวบรวมข้อมูลและสิ่งที่พวกเขาจะละเลยเพื่อพยายามดึงข้อมูลที่เป็นประโยชน์มากที่สุด เกี่ยวกับเว็บไซต์

โฮสต์เว็บไซต์ของคุณด้วย Pressidium
รับประกันคืนเงิน 60 วัน
เมื่อคุณอนุญาตให้บอทรวบรวมข้อมูลทุกหน้าบนเว็บไซต์ของคุณ เวลาที่ใช้ในการรวบรวมข้อมูลส่วนหนึ่งจะถูกใช้ไปกับหน้าที่ไม่สำคัญหรือแม้แต่เกี่ยวข้อง ทำให้มีเวลาน้อยลงในการทำงานผ่านส่วนที่เกี่ยวข้องมากขึ้นในไซต์ของคุณ การไม่อนุญาตให้บอทเข้าถึงบางส่วนของเว็บไซต์ของคุณจะเพิ่มเวลาที่บอทจะดึงข้อมูลจากส่วนที่เกี่ยวข้องมากที่สุดของไซต์ของคุณ (ซึ่งหวังว่าจะได้รับการจัดทำดัชนี) เนื่องจากการรวบรวมข้อมูลทำได้เร็วกว่า Google จึงมีแนวโน้มที่จะกลับมาเยี่ยมชมเว็บไซต์ของคุณอีกครั้งและทำให้ดัชนีของเว็บไซต์เป็นปัจจุบันอยู่เสมอ ซึ่งหมายความว่าโพสต์บล็อกใหม่และเนื้อหาที่สดใหม่อื่นๆ มักจะได้รับการจัดทำดัชนีเร็วขึ้นซึ่งเป็นข่าวดี
ตัวอย่างการแก้ไข Robots.txt
robots.txt มีพื้นที่มากมายสำหรับการปรับแต่ง ด้วยเหตุนี้ เราจึงได้จัดเตรียมตัวอย่างกฎต่างๆ มากมายที่สามารถใช้เพื่อกำหนดวิธีที่บ็อตจัดทำดัชนีไซต์ของคุณ
อนุญาตหรือไม่อนุญาตให้บอท
อันดับแรก มาดูว่าเราจะสามารถจำกัดบอทเฉพาะได้อย่างไร ในการทำเช่นนี้ สิ่งที่เราต้องทำคือแทนที่เครื่องหมายดอกจัน (*) ด้วยชื่อของบอท user-agent ที่เราต้องการบล็อก เช่น 'MSNBot' รายการ User-agent ที่รู้จักอย่างครอบคลุมมีอยู่ที่นี่
User-agent: MSNBot Disallow: /การใส่เส้นประในบรรทัดที่สองจะจำกัดการเข้าถึงของบอทในไดเรกทอรีทั้งหมด
เพื่อให้มีบอทเพียงตัวเดียวในการรวบรวมข้อมูลเว็บไซต์ของเรา เราจะใช้กระบวนการ 2 ขั้นตอน อันดับแรก เราจะตั้งบอทตัวนี้เป็นข้อยกเว้น และจากนั้นไม่อนุญาตบอททั้งหมดในลักษณะนี้:
User-agent: Google Disallow: User-agent: * Disallow: /เพื่อให้สามารถเข้าถึงบอททั้งหมดในเนื้อหาทั้งหมดเราได้เพิ่มสองบรรทัดเหล่านี้:
User-agent: * Disallow:ผลลัพธ์เดียวกันนี้สามารถทำได้โดยการสร้างไฟล์ robots.txt แล้วปล่อยว่างไว้
การบล็อกการเข้าถึงไฟล์เฉพาะ
ต้องการหยุดบอทสร้างดัชนีไฟล์บางไฟล์บนเว็บไซต์ของคุณหรือไม่? ง่ายมาก! ในตัวอย่างด้านล่าง เราได้ป้องกันไม่ให้เครื่องมือค้นหาเข้าถึงไฟล์ .pdf ทั้งหมดบนเว็บไซต์ของเรา
User-agent: * Disallow: /*.pdf$สัญลักษณ์ “$” ใช้เพื่อกำหนดส่วนท้ายของ URL เนื่องจากต้องคำนึงถึงตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ ไฟล์ที่มีชื่อ my.PDF จะยังคงถูกรวบรวมข้อมูล (โปรดทราบ CAPS)
นิพจน์ตรรกะที่ซับซ้อน
เครื่องมือค้นหาบางตัว เช่น Google เข้าใจการใช้นิพจน์ทั่วไปที่ซับซ้อนกว่า อย่างไรก็ตาม สิ่งสำคัญที่ควรทราบคือ ไม่ใช่ทุกเครื่องมือค้นหาอาจเข้าใจนิพจน์เชิงตรรกะใน robots.txt ได้

ตัวอย่างหนึ่งคือการใช้สัญลักษณ์ $ ในไฟล์ robots.txt สัญลักษณ์นี้ระบุจุดสิ้นสุดของ URL ดังนั้น ในตัวอย่างต่อไปนี้ เราได้บล็อกบอทการค้นหาไม่ให้อ่านและสร้างดัชนีไฟล์ที่ลงท้ายด้วย .php
Disallow: /*.php$ซึ่งหมายความว่า /index.php ไม่สามารถสร้างดัชนีได้ แต่ /index.php?p=1 สามารถทำได้ สิ่งนี้มีประโยชน์เฉพาะในสถานการณ์ที่เฉพาะเจาะจงเท่านั้น และต้องใช้ด้วยความระมัดระวัง ไม่เช่นนั้นคุณอาจเสี่ยงต่อการบล็อกการเข้าถึงไฟล์ที่คุณไม่ได้ตั้งใจโดยบอท!
คุณยังสามารถตั้งกฎที่แตกต่างกันสำหรับแต่ละบอทโดยระบุกฎที่ใช้กับบอทแต่ละตัว โค้ดตัวอย่างด้านล่างจะจำกัดการเข้าถึงโฟลเดอร์ wp-admin สำหรับบอททั้งหมด ในขณะเดียวกันก็บล็อกการเข้าถึงไซต์ทั้งหมดสำหรับเครื่องมือค้นหา Bing คุณไม่จำเป็นต้องทำสิ่งนี้ แต่เป็นการสาธิตที่มีประโยชน์ว่ากฎในไฟล์ robots.txt มีความยืดหยุ่นเพียงใด
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /XML Sitemaps
แผนผังไซต์ XML ช่วยให้บอทการค้นหาเข้าใจเลย์เอาต์ของเว็บไซต์ของคุณได้อย่างแท้จริง แต่เพื่อให้มีประโยชน์ บอทจำเป็นต้องรู้ว่าแผนผังเว็บไซต์อยู่ที่ใด 'คำสั่งแผนผังเว็บไซต์' ใช้เพื่อบอกเครื่องมือค้นหาโดยเฉพาะว่า ก) แผนผังเว็บไซต์มีอยู่ในเว็บไซต์ของคุณ และ ข) พวกเขาสามารถค้นหาได้จากที่ใด
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:คุณยังสามารถระบุตำแหน่งของแผนผังเว็บไซต์ได้หลายตำแหน่ง:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* Disallowความล่าช้าในการรวบรวมข้อมูลของบอท
ฟังก์ชันอื่นที่สามารถทำได้ผ่านไฟล์ robots.txt คือการบอกให้บอท 'ชะลอ' การรวบรวมข้อมูลไซต์ของคุณ นี่อาจจำเป็นหากคุณพบว่าเซิร์ฟเวอร์ของคุณมีปริมาณการใช้บอทสูงมากเกินไป ในการดำเนินการนี้ คุณจะต้องระบุ user-agent ที่คุณต้องการทำให้ช้าลงแล้วเพิ่มการหน่วงเวลา
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10เครื่องหมายคำพูดตัวเลข (10) ในตัวอย่างนี้คือความล่าช้าที่คุณต้องการให้เกิดขึ้นระหว่างการรวบรวมข้อมูลแต่ละหน้าในไซต์ของคุณ ในตัวอย่างด้านบน เราได้ขอให้ Bing Bot หยุดชั่วคราวเป็นเวลาสิบวินาทีระหว่างแต่ละหน้าที่รวบรวมข้อมูล และทำให้เซิร์ฟเวอร์ของเรามีพื้นที่ว่างเล็กน้อย
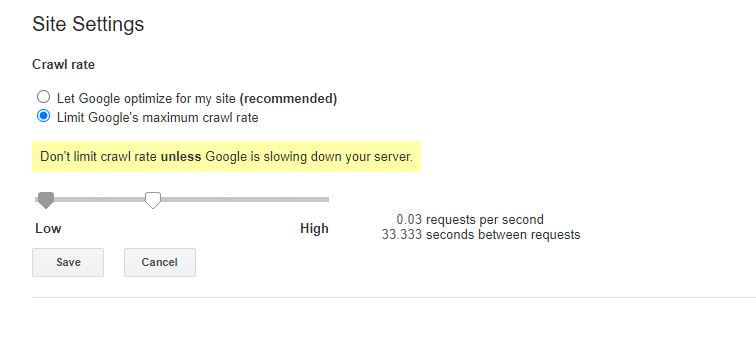
ข่าวร้ายเพียงเล็กน้อยเกี่ยวกับกฎของ robots.txt นี้คือบ็อตของ Google ไม่เคารพกฎดังกล่าว อย่างไรก็ตาม คุณสามารถสั่งให้บอททำงานช้าลงจากภายใน Google Search Console
หมายเหตุเกี่ยวกับกฎของ robots.txt:
- กฎของ robots.txt ทั้งหมดคำนึงถึงขนาดตัวพิมพ์ พิมพ์อย่างระมัดระวัง!
- ตรวจสอบให้แน่ใจว่าไม่มีช่องว่างก่อนคำสั่งที่ต้นบรรทัด
- การเปลี่ยนแปลงที่ทำใน robots.txt อาจใช้เวลา 24-36 ชั่วโมงจึงจะบันทึกโดยบ็อต
วิธีทดสอบและส่งไฟล์ robots.txt WordPress ของคุณ
เมื่อคุณสร้างไฟล์ robots.txt ใหม่ ควรตรวจสอบว่าไม่มีข้อผิดพลาดในไฟล์ คุณสามารถทำได้โดยใช้ Google Search Console
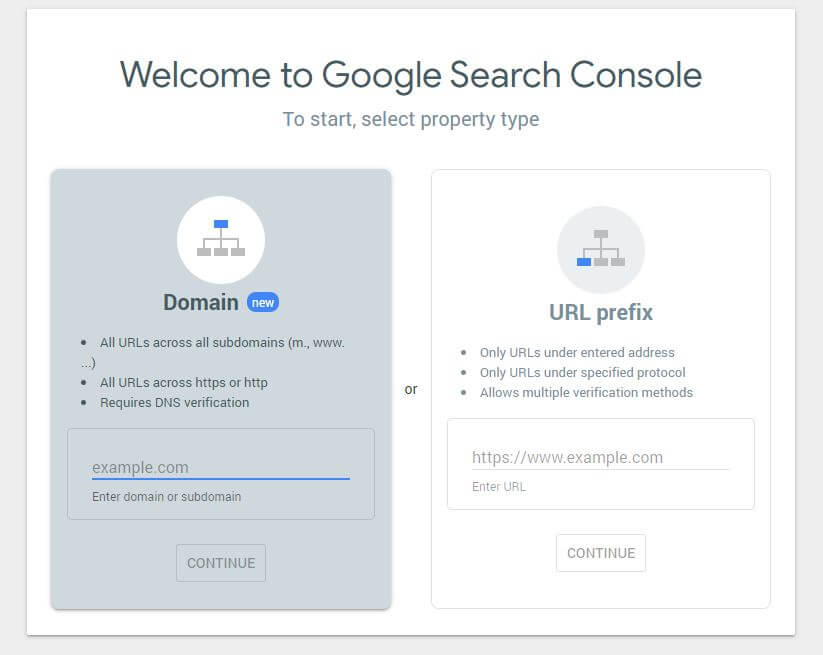
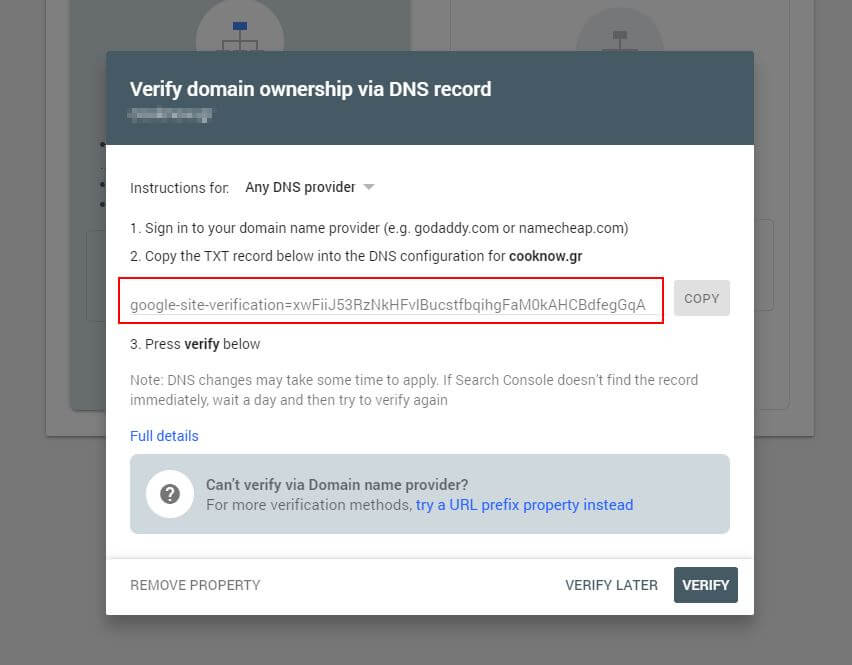
ขั้นแรก คุณจะต้องส่งโดเมนของคุณ (หากคุณยังไม่มีบัญชี Search Console สำหรับการตั้งค่าเว็บไซต์ของคุณ) Google จะให้ระเบียน TXT แก่คุณ ซึ่งจำเป็นต้องเพิ่มใน DNS เพื่อยืนยันโดเมนของคุณ
เมื่อการอัปเดต DNS นี้เผยแพร่แล้ว (รู้สึกหมดความอดทน... ลองใช้ Cloudflare เพื่อจัดการ DNS ของคุณ) คุณสามารถไปที่ตัวทดสอบ robots.txt และตรวจสอบว่ามีคำเตือนเกี่ยวกับเนื้อหาของไฟล์ robots.txt ของคุณหรือไม่
อีกสิ่งหนึ่งที่คุณสามารถทำได้เพื่อทดสอบกฎที่คุณมีกำลังมีผลตามที่ต้องการคือการใช้เครื่องมือทดสอบ robots.txt เช่น Ryte
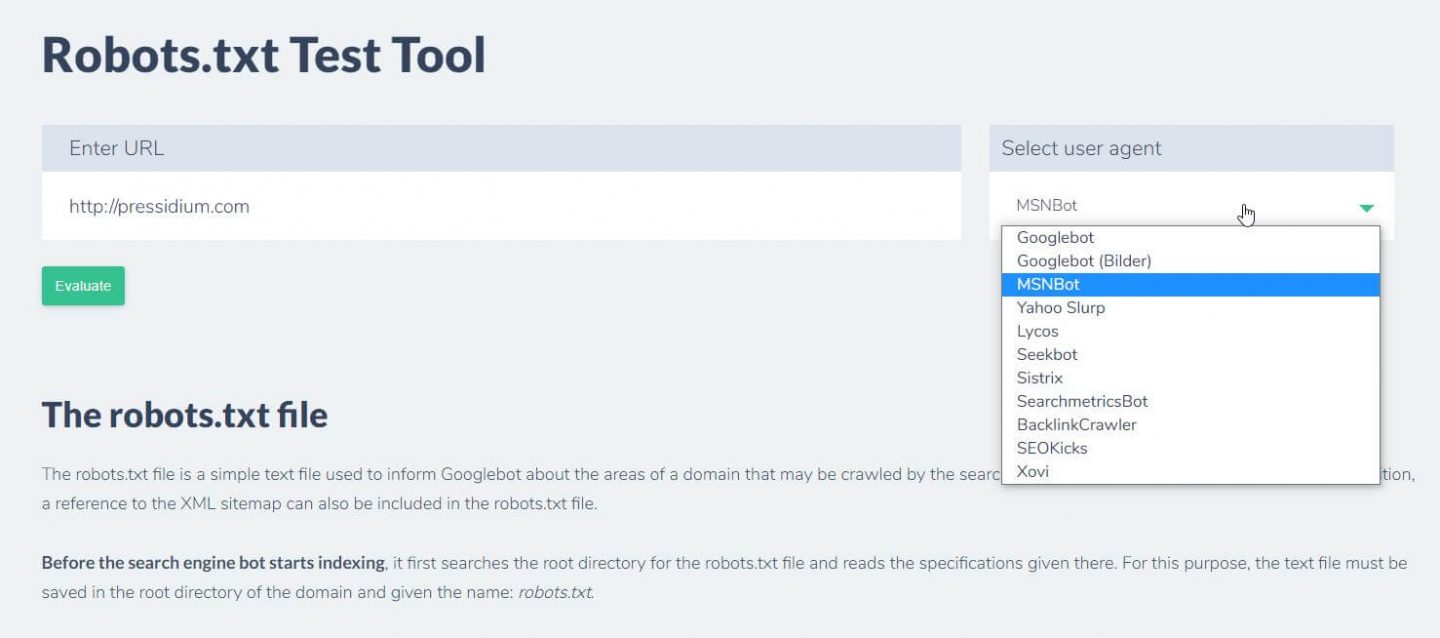
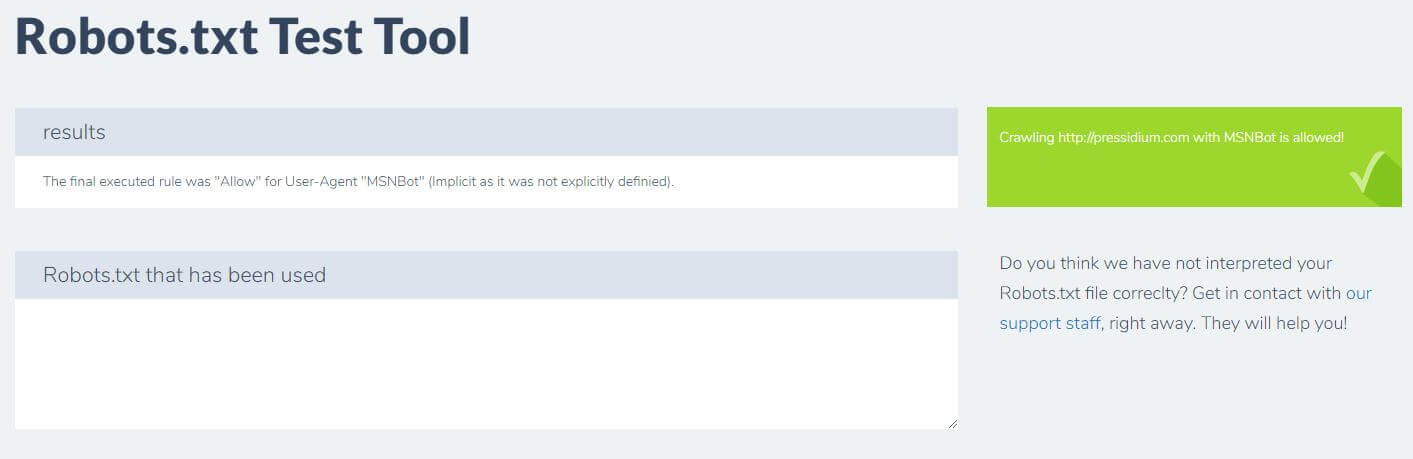
คุณเพียงแค่ป้อนโดเมนของคุณและเลือกตัวแทนผู้ใช้จากแผงด้านขวา หลังจากส่งข้อมูลนี้ คุณจะเห็นผลลัพธ์ของคุณ
บทสรุป
การรู้วิธีใช้ robots.txt เป็นอีกหนึ่งเครื่องมือที่มีประโยชน์ในชุดเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ของคุณ หากสิ่งเดียวที่คุณนำออกไปจากบทช่วยสอนนี้คือความสามารถในการตรวจสอบว่าไฟล์ robots.txt ของคุณไม่ได้บล็อกบ็อตอย่าง Google (ซึ่งคุณไม่น่าจะทำได้มากนัก) ก็ไม่เลว! เช่นเดียวกัน อย่างที่คุณเห็น robots.txt เสนอโฮสต์ทั้งหมดของการควบคุมที่ละเอียดยิ่งขึ้นบนเว็บไซต์ของคุณ ซึ่งอาจมีประโยชน์ในสักวันหนึ่ง