
误导性统计数据可能很危险(一些示例)
已发表: 2022-12-06人们依靠统计数据来获取重要信息。 在商业世界中,统计数据可用于跟踪趋势和最大限度地提高生产力。 但有时统计数据可能会以误导的方式呈现。 例如,2007 年英国广告标准局 (ADA) 收到了关于高露洁广告的投诉。
该广告著名地声称 80% 的牙医推荐使用高露洁牙膏。 ADA 收到的投诉称,这违反了英国的广告规则。 在调查此事后,ADA 发现该广告使用了误导性统计数据。
诚然,很多牙医都推荐高露洁牙膏。 但并非所有人都将高露洁列为第一推荐。 大多数牙医也推荐其他种类的牙膏,而高露洁通常会在稍后的某个时候出现。
这只是如何使用误导性统计数据的一个例子。 人们在生活的许多不同领域都会遇到误导性统计示例。 你可以在新闻、广告、政治甚至科学中找到例子。
这篇文章将帮助您学会识别误导性统计数据和其他误导性数据。 它将讨论这些数据如何误导人们。 您还将了解在做出关键决策时何时以及如何使用数据。
什么是误导性统计数据?
统计数据是收集数字数据、仔细分析然后进行解释的结果。 如果您正在处理大量数据,那么拥有统计数据尤其有用,但任何可以衡量的东西都可以成为统计数据。 统计数据通常可以揭示很多关于世界及其运作方式的信息。
然而,当该信息被滥用时,即使是偶然地,它也会变成误导性统计数据。 误导性统计数据为人们提供了欺骗他们而不是告知他们的虚假信息。
当人们断章取义统计数据时,它就失去了价值,并可能导致人们得出错误的结论。 “误导性统计”一词描述了任何错误地表示数据的统计方法。 不管是有意还是无意,它仍然会被视为误导性统计数据。
在收集统计数据时,需要牢记三个原则要点。 在这些时间点中的任何一个时间点都可能发生数据分析问题。
- 收集:在收集数据时
- 处理:分析数据及其含义时
- 演示:与他人分享您的发现时
样本量小
样本量调查是创建误导性统计数据的一个例子。 对样本量的受众进行的调查或研究通常会产生误导性的结果,以至于它们无法使用。
为了说明这一点,一项调查向 20 人询问了一个是或否的问题。 19 人对调查的回答是肯定的。 所以结果表明 95% 的人会回答“是”。 但这不是一个好的调查,因为信息有限。
该统计数据没有实际价值。 现在,如果您问 1,000 个人同样的问题,而 950 人回答“是”,那么这是一个更可靠的统计数据,表明 95% 的人会回答“是”。
要进行可靠的样本量研究,您需要考虑三件事:
- 一:你在问什么样的问题?
- 二:您要查找的统计数据的意义是什么?
- 第三:你会使用什么统计技术?
要获得可靠的结果,任何样本量定量分析都应至少包括 200 人。
加载的问题

从中立来源寻找数据很重要。 否则,信息是倾斜的。 加载问题使用有争议或不合理的假设来操纵响应。 这方面的一个例子是问一个以“你喜欢什么”开头的问题。 这个问题在收集积极反馈方面做得很好,但没有教给你任何有用的东西。 它没有为人们提供诚实的想法和意见的机会。
考虑以下两个问题的区别:
- 您是否支持意味着更高税收的税制改革?
- 您是否支持有利于社会再分配的税制改革?
这个问题本质上与同一主题有关,但是每个问题的结果都会大不相同。 民意调查应以公正、无偏见的方式进行。 您希望获得人们的真实意见和人们想法的全貌。 为此,您的问题不应暗示答案,也不应激起情绪反应。
引用误导性的“平均值”
有些人使用“平均”一词来掩盖真相或撒谎以使信息看起来更好。
如果有人想让数字看起来比实际更大或更好,则此技术特别有用。 例如,一所想要吸引新生的大学可能会为其学校的毕业生提供“平均”年薪。 但真正拿高薪的学生,可能只是屈指可数。 但他们的薪水使所有学生的平均收入更高。 对于整个平均值来说,这看起来更好。
平均值对于隐藏不平等也很有用。 再举一个例子,假设一家公司每年向其 90 名员工支付 20,000 美元。 但他们的老板每年收到 20 万美元。 如果将老板的工资和员工的工资合并,公司每位成员的平均收入为 21,978 美元。
在纸面上,这看起来很棒。 但这个数字并不能说明全部情况,因为其中一名员工(老板)的收入远远高于其他员工。 所以这些类型的结果算作误导性统计数据。
累积与年度数据
累积数据随时间跟踪图表上的信息。 每次将数据输入图表时,图表都会上升。
年度数据显示特定年份的所有数据。
每年的跟踪信息提供了更真实的总体趋势图。
累积图的一个示例是 Worldometer COVID-19 图。 在 COVID-19 大流行期间,出现了许多累积图的例子。 它们通常反映特定地区 COVID 病例的累计数量。
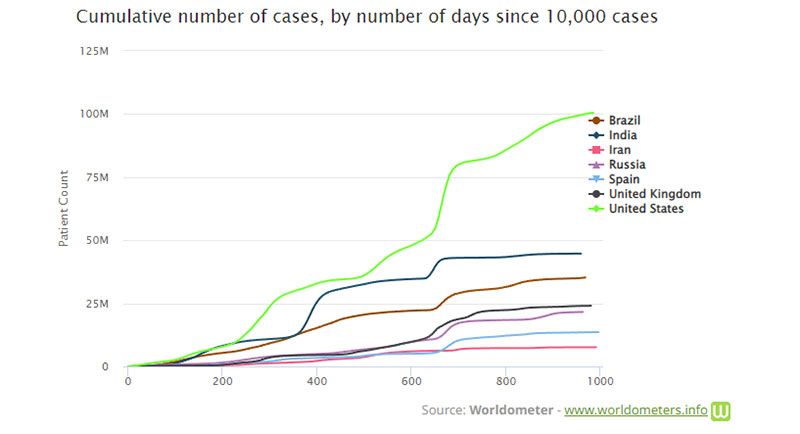
一些公司使用这样的图表来使销售额看起来比实际情况更大。 2013 年,苹果公司首席执行官蒂姆库克因使用仅显示 iPhone 累计销量的演示文稿而受到批评。 当时许多人认为他故意这样做是为了掩盖 iPhone 销量下降的事实。
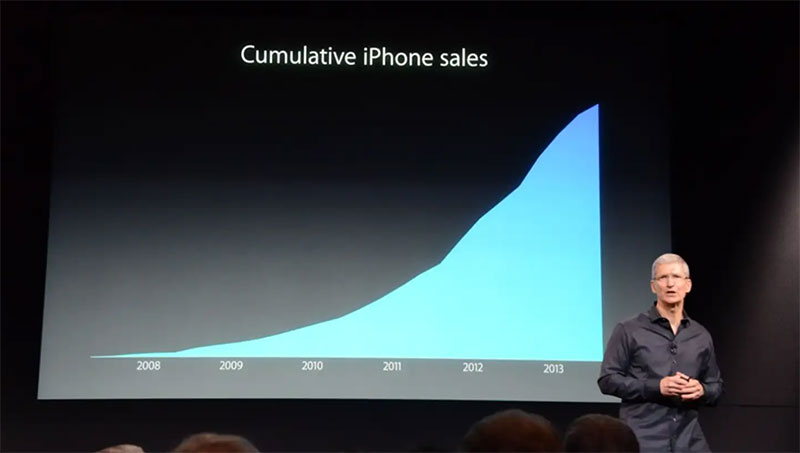
这并不是说所有累积数据都是错误的或错误的。 事实上,它可用于跟踪变化或增长以及各种总数。 但重要的是要注意数据的变化。 然后更深入地了解导致它们的原因,而不是依赖图表来告诉您一切。
过度概括和有偏差的样本
当某人认为对一个人适用的东西对其他所有人都适用时,就会出现过度概括。 通常,当某人对特定人群进行研究时,就会出现这种谬误。 然后他们假设结果将适用于另一组无关的人。
不具代表性的样本或有偏差的样本是不能准确代表一般人群的调查。
样本偏差的一个例子发生在 1936 年的美国总统选举期间。
The Literary Digest, a popular magazine at the time, carried out a survey to predict who would win the elections. 结果预测阿尔弗雷德兰登将以压倒性优势获胜。
该杂志以准确预测选举结果而闻名。 然而今年,他们完全错了。 富兰克林·罗斯福以几乎是对手两倍的票数获胜。
更多的研究表明,有两个变量开始发挥作用,导致结果出现偏差。
首先,调查中的大多数参与者都是在电话簿和自动注册列表中找到的人。 因此,该调查仅针对具有一定社会经济地位的人进行。
第二个因素是那些投票给兰登的人比那些选择投票给罗斯福的人更愿意回应调查。 所以结果反映了这种偏见。
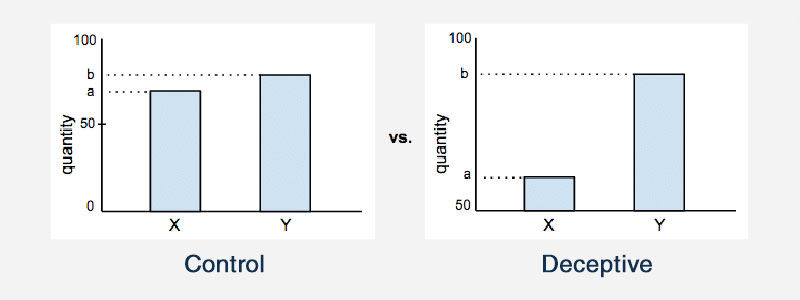
截断轴
截断图表上的轴是误导性统计数据的另一个例子。 在大多数统计图中,x 轴和 y 轴大概都从零开始。 但是截断轴意味着图形实际上以其他值开始轴。 这会影响图表的外观,并影响人们得出的结论。
这是一个说明这一点的例子:
这方面的另一个例子最近发生在 2021 年 9 月。在福克斯新闻的一次广播中,主播使用了一张图表显示自称是基督徒的美国人人数。 该图表显示,在过去 10 年中,认定为基督徒的美国人人数急剧下降。
在下图中,我们看到 2009 年 77% 的美国人被认定为基督徒。
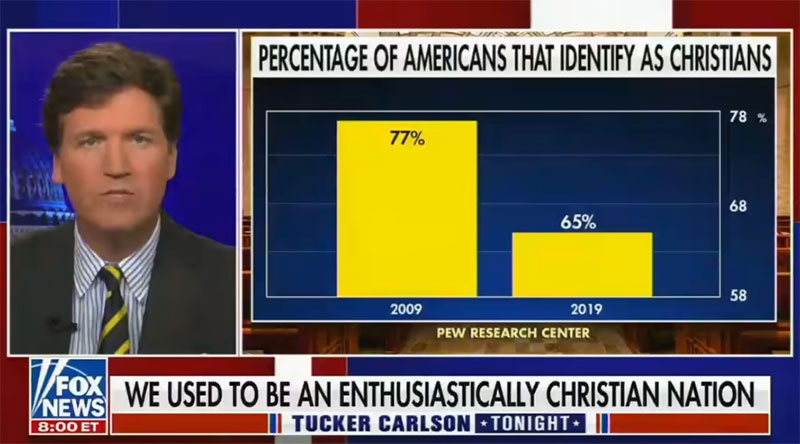
到 2019 年,这一数字下降到 65%。 实际上,这并不是一个巨大的下降。 但此图表上的轴从 58% 开始,到 78% 停止。 因此,从 2009 年到 2019 年 12% 的下降看起来比实际情况要剧烈得多。

因果关系
可以很容易地假设两个看似相连的数据点之间存在联系。 然而,据说相关性并不意味着因果关系。 为什么呢?
该图说明了为什么相关性与因果关系不同。
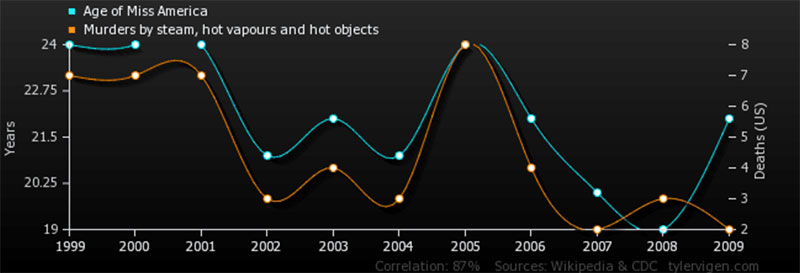
研究人员经常面临发现新的有用数据的巨大压力。 因此,仓促行事和过早下结论的诱惑总是存在的。 这就是为什么在每种情况下寻找实际因果关系都很重要。
使用百分比隐藏数字和计算
百分比可以隐藏确切的数字,并使结果看起来比实际情况更有信誉和更可靠。
例如,如果三分之二的人喜欢某种清洁产品,则可以说 66.667% 的人喜欢该产品。 这使数字看起来更正式,尤其是包含小数点后的数字。
以下是小数和百分比掩盖真相的其他几种方式:
- 隐藏原始数据和小样本量。 百分比掩盖了原始数字的绝对值。 这使得它们对于想要隐藏不讨人喜欢的数字或小样本量结果的人很有用。
- 使用不同的基地。 因为百分比不提供它们所基于的原始数字,所以很容易扭曲结果。 如果有人想让一个数字看起来更好,他们可以根据不同的基数计算该数字。
在《纽约时报》发布的一篇关于工会工人的报道中,就出现过一次这种情况。 工人们一年减薪 20%,次年,《泰晤士报》报道工会工人加薪 5%。 所以声称他们得到了减薪的四分之一。
然而,工人们根据他们目前的工资获得了 5% 的加薪,而不是减薪前的工资。 因此,尽管在纸面上看起来不错,但减薪 20% 和加薪 5% 是根据不同的基数计算得出的。 这两个数字根本没有可比性。
樱桃采摘/丢弃不利数据
术语“樱桃采摘”是基于只从树上采摘最好的果实的想法。 任何人看到这种果子一定会认为树上所有的果子都同样健康。 显然,情况不一定如此。
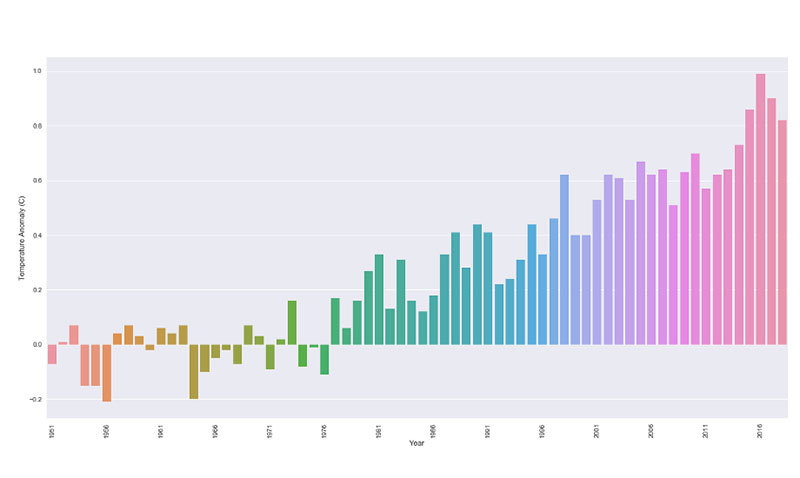
同样的原则也适用于气候变化。 许多图表将其数据框限制为仅显示 2000 年至 2013 年的气候变化。
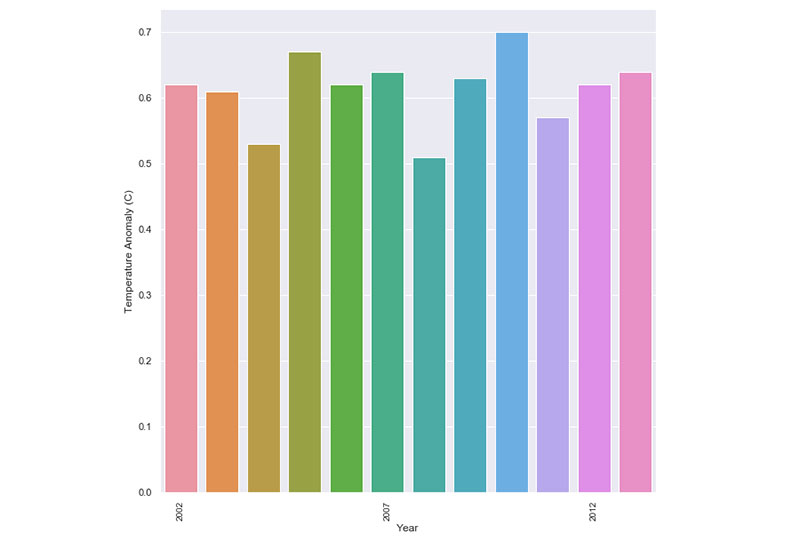
结果,温度变化和异常似乎是一致的,变化不大。 但是,当您退后一步并从大局着眼时,就会清楚变化和异常在哪里。
这也发生在兽医学领域。 当兽医被要求展示一种新试验药物的结果时,他们往往会展示最好的结果。 特别是如果一家制药公司支持试验,他们只想看到最好的结果。
你的美数据值得上线
wpDataTables可以做到这一点。 它是用于创建响应式表格和图表的排名第一的 WordPress 插件,这是有充分理由的。
做这样的事情真的很容易:
- 您提供表格数据
- 配置和自定义它
- 在帖子或页面中发布
它不仅漂亮,而且实用。 您可以创建包含多达数百万行的大型表格,或者您可以使用高级过滤器和搜索,或者您可以疯狂地使其可编辑。
“是的,但我太喜欢 Excel 了,网站上没有类似的东西”。 是的,有。 您可以使用 Excel 或 Google 表格中的条件格式。
我是否告诉过您也可以用您的数据创建图表? 而这只是一小部分。 还有许多其他功能适合您。
数据钓鱼
数据钓鱼,也称为数据挖掘,是对大量数据的分析,目的是找到相关性。 然而,正如本文前面所讨论的,相关性并不意味着因果关系。 坚持认为这只会导致误导性统计数据。
每天都能看到行业领域数据钓鱼的例子。 一周后发布了有关数据挖掘的丑闻,一周后又被一份更离谱的报告驳斥。
这种数据分析的另一个问题是人们只选择支持他们观点的数据而忽略其余部分。 通过省略相互矛盾的信息,它们使结果看起来更有说服力。
混淆图形和图表标签
当 COVID-19 大流行开始时,比以往任何时候都更多的人转向病毒传播的数据可视化。 那些从来不需要处理统计数据可视化表示的人突然被甩出了统计数据的深渊。
此外,组织经常试图快速获取人员信息。 有时这意味着牺牲准确的统计数据。 这导致误导性统计数据和对数据的误解激增。
在 COVID-19 开始传播大约五个月后,美国佐治亚州公共卫生部发布了这张图表:
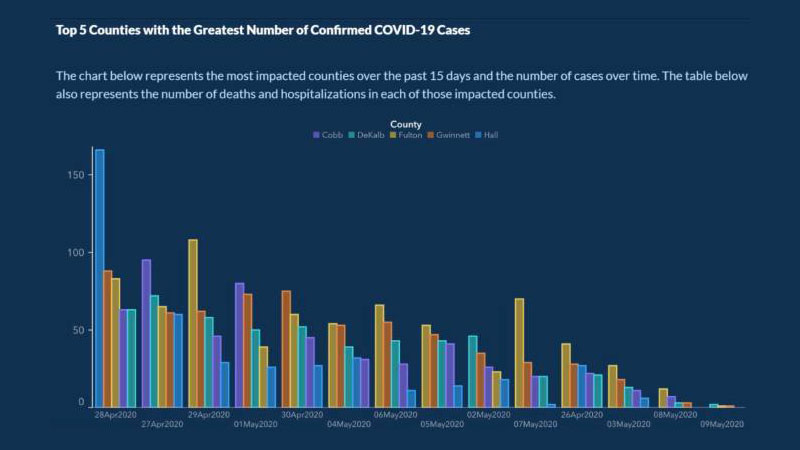
该图表的目的是显示过去 15 天内 COVID 病例最多的 5 个国家,以及一段时间内的病例数。
这张图表有一些错误,很容易引起误解。 例如,x 轴没有标签来解释它代表案例随时间的进展。
更糟糕的是,图表上的日期不是按时间顺序排列的。 4 月和 5 月的日期散布在整个图表中,以表明病例数似乎在稳步下降。 每个国家也以某种方式列出,使案件看起来正在下降。
后来,他们重新发布了具有更好组织的日期和县的图表:
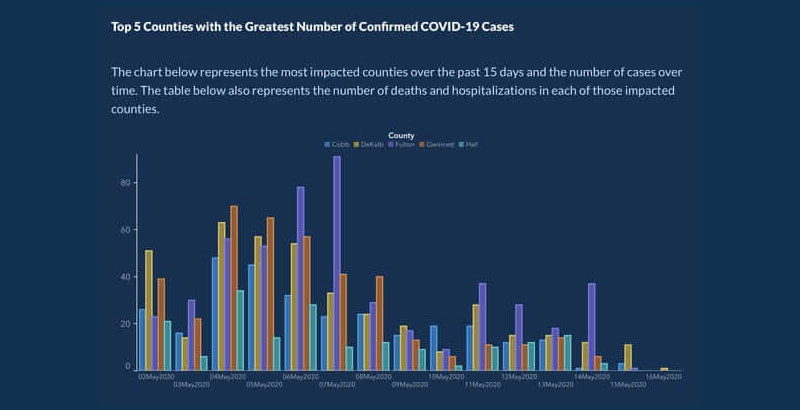
数字不准确
误导性统计数据的另一个例子是不准确的数字。 请注意旧 Reebok 活动中的此声明。
该广告声称,与其他运动鞋相比,这双鞋可以使人的腿筋和小腿更加坚硬 11% ,并且可以使人的臀部更加结实28% 。 人们所要做的就是穿着运动鞋走路。
这些数字表明 Reebok 对这款鞋的优点进行了广泛研究。
事实上,这些数字完全是编造的。 该品牌因使用此类误导性统计数据而受到处罚。 他们还必须更改声明并删除假号码。
如何避免和识别统计数据的滥用
统计数据有可能非常有用。 但误导性统计数据也有可能迷惑和欺骗人们。 统计数据赋予陈述以权威,并说服人们相信某个论点。
可靠、真实的统计数据有助于为人们提供洞察力并帮助他们做出决策。 但误导性统计数据是危险的。 他们不是帮助人们避免陷阱和坑洞,而是引导人们进入他们想要避免的境地。
但有可能识别出误导性的统计数据和数据。 当您遇到统计数据时,停下来问以下问题:
- 这些数据从何而来?
- 源头是否受控? 或者它是一个样本量的实验?
- 还有哪些其他因素可以影响这一结果?
- 这些信息是在试图告诉我,还是在引导我得出一个预先确定的结论?
无论您是在收集数据还是在查看他人的研究结果,请确保数据准确无误。 这样您就不会助长误导性统计数据的传播。
如果您喜欢阅读这篇关于误导统计的文章,您还应该阅读以下内容:
- 您将在网上找到的最令人印象深刻的交互式数据可视化
- 您可以找到的最好的 WordPress 数据可视化工具
- 最适合您的数据可视化工具和平台