
如何创建 MongoDB 数据库:要了解的 6 个关键方面
已发表: 2022-11-07根据您对软件的要求,您可能会优先考虑灵活性、可扩展性、性能或速度。 因此,开发人员和企业在为他们的需求选择数据库时经常会感到困惑。 如果您需要一个提供高灵活性和可扩展性的数据库,以及用于客户分析的数据聚合,那么 MongoDB 可能是您的最佳选择!
在本文中,我们将讨论 MongoDB 数据库的结构以及如何创建、监控和管理您的数据库! 让我们开始吧。
MongoDB 数据库的结构如何?
MongoDB 是一个无模式的 NoSQL 数据库。 这意味着您不必像为 SQL 数据库那样为表/数据库指定结构。
你知道 NoSQL 数据库实际上比关系数据库更快吗? 这是由于索引、分片和聚合管道等特性。 MongoDB 还以其快速的查询执行而闻名。 这就是为什么它受到谷歌、丰田和福布斯等公司的青睐。
下面,我们将探讨 MongoDB 的一些关键特性。
文件
MongoDB 有一个文档数据模型,将数据存储为 JSON 文档。 文档自然地映射到应用程序代码中的对象,使开发人员使用起来更加直接。
在关系数据库表中,您必须添加一列才能添加新字段。 JSON 文档中的字段并非如此。 JSON 文档中的字段可能因文档而异,因此不会将它们添加到数据库中的每条记录中。
文档可以存储像数组这样的结构,这些结构可以嵌套来表达层次关系。 此外,MongoDB 将文档转换为二进制 JSON (BSON) 类型。 这确保了更快的访问并增加了对各种数据类型(如字符串、整数、布尔数等)的支持!
副本集
当您在 MongoDB 中创建新数据库时,系统会自动创建至少 2 个数据副本。 这些副本被称为“副本集”,它们不断地在它们之间复制数据,从而确保提高数据的可用性。 它们还提供系统故障或计划维护期间的停机保护。
收藏品
集合是与一个数据库相关联的一组文档。 它们类似于关系数据库中的表。
然而,集合更加灵活。 一方面,它们不依赖于模式。 其次,文档不必是相同的数据类型!
要查看属于数据库的集合列表,请使用命令listCollections 。
聚合管道
您可以使用此框架来组合多个运算符和表达式。 它很灵活,因为它允许您处理、转换和分析任何结构的数据。
正因为如此,MongoDB 允许跨 150 个运算符和表达式的快速数据流和特性。 它也有几个阶段,比如联合阶段,它可以灵活地将来自多个集合的结果放在一起。
索引
您可以对 MongoDB 文档中的任何字段进行索引,以提高其效率并提高查询速度。 索引通过扫描索引以限制检查的文档来节省时间。 这不是比阅读集合中的每个文档要好得多吗?
您可以使用各种索引策略,包括多个字段的复合索引。 例如,假设您有多个文档,在不同的字段中包含员工的名字和姓氏。 如果您希望返回名字和姓氏,您可以创建一个包含“姓氏”和“名字”的索引。 这比在“姓氏”上有一个索引,在“名字”上有另一个索引要好得多。
您可以利用 Performance Advisor 等工具进一步了解哪些查询可以从索引中受益。
分片
分片将单个数据集分布在多个数据库中。 然后可以将该数据集存储在多台机器上,以增加系统的总存储容量。 这是因为它将较大的数据集拆分为较小的块并将它们存储在各种数据节点中。
MongoDB 在集合级别对数据进行分片,将集合中的文档分布在集群中的各个分片上。 这通过允许架构处理最大的应用程序来确保可扩展性。
如何创建 MongoDB 数据库
您需要先安装适合您的操作系统的正确 MongoDB 包。 转到“下载 MongoDB 社区服务器”页面。 从可用选项中,选择最新的“版本”、“打包”格式为 zip 文件,以及“平台”作为您的操作系统,然后单击“下载”,如下图所示:
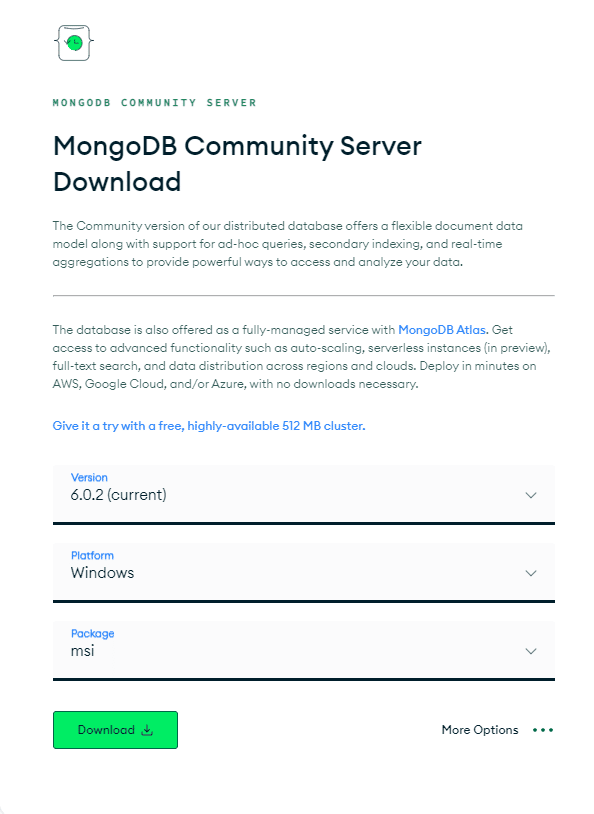
该过程非常简单,因此您很快就会在系统中安装 MongoDB!
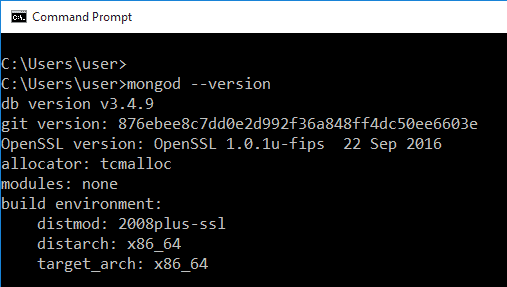
完成安装后,打开命令提示符并输入mongod -version进行验证。 如果您没有得到以下输出,而是看到一串错误,则可能需要重新安装它:
使用 MongoDB 外壳
在我们开始之前,请确保:
- 您的客户端具有传输层安全性,并且在您的 IP 许可名单上。
- 您在所需的 MongoDB 集群上有一个用户帐户和密码。
- 你已经在你的设备上安装了 MongoDB。
第 1 步:访问 MongoDB Shell
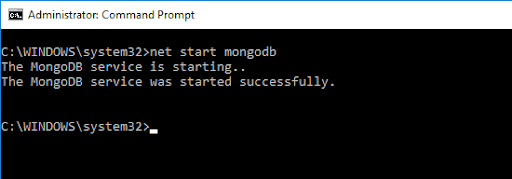
要访问 MongoDB shell,请输入以下命令:
net start MongoDB这应该给出以下输出:
前面的命令初始化了 MongoDB 服务器。 要运行它,我们必须在命令提示符下输入mongo 。
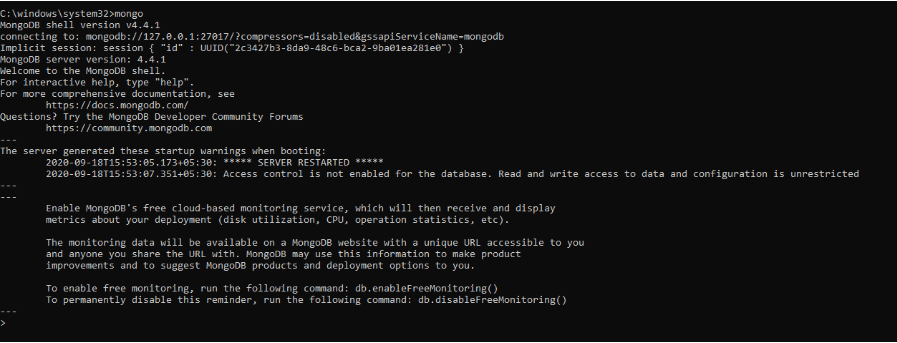
在 MongoDB shell 中,我们可以执行命令来创建数据库、插入数据、编辑数据、发出管理命令和删除数据。
第 2 步:创建您的数据库
与 SQL 不同,MongoDB 没有数据库创建命令。 相反,有一个名为use的关键字可以切换到指定的数据库。 如果数据库不存在,它将创建一个新数据库,否则,它将链接到现有数据库。
例如,要启动一个名为“company”的数据库,请输入:
use Company 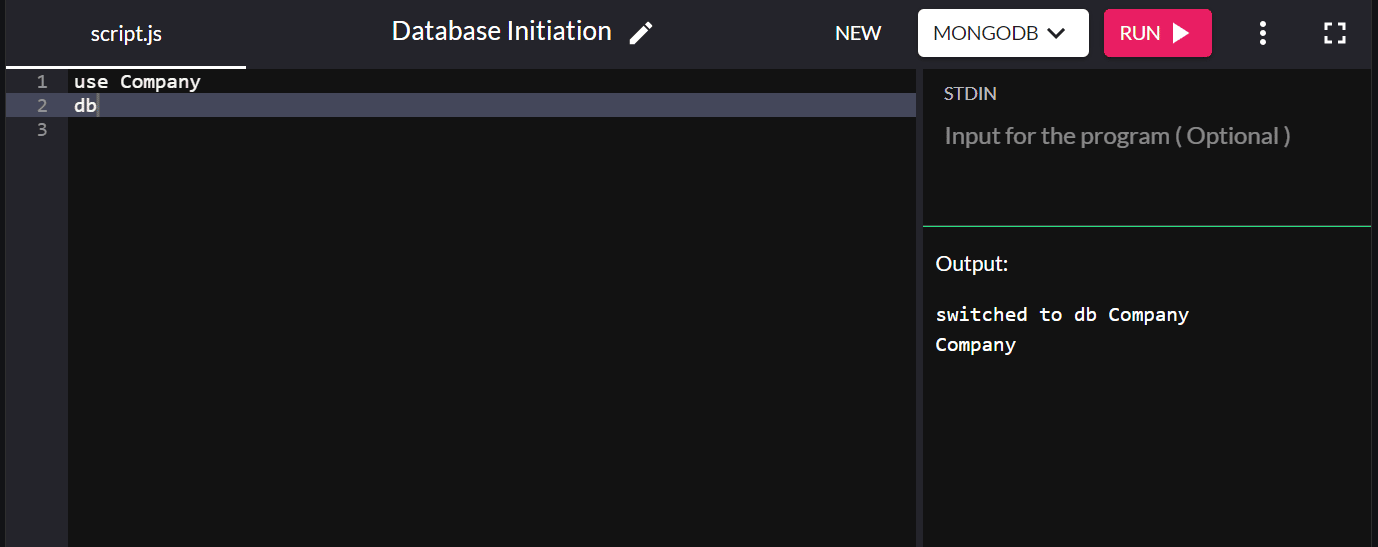
您可以输入db以确认您刚刚在系统中创建的数据库。 如果弹出您创建的新数据库,则您已成功连接到它。
如果要检查现有数据库,请输入show dbs ,它将返回系统中的所有数据库:
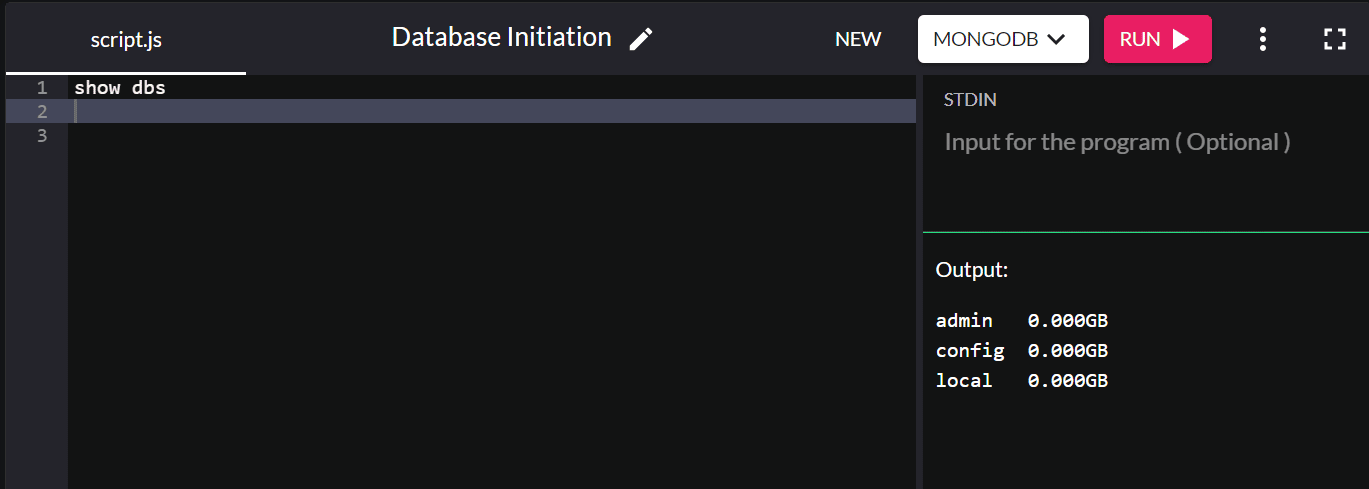
默认情况下,安装 MongoDB 会创建管理、配置和本地数据库。
您是否注意到我们创建的数据库没有显示? 这是因为我们还没有将值保存到数据库中! 我们将在数据库管理部分讨论插入。
使用 Atlas 用户界面
您还可以开始使用 MongoDB 的数据库服务 Atlas。 虽然您可能需要付费才能访问 Atlas 的某些功能,但大多数数据库功能都可通过免费层获得。 免费层的功能足以创建一个 MongoDB 数据库。
在我们开始之前,请确保:
- 您的 IP 在允许列表中。
- 您在要使用的 MongoDB 集群上有一个用户帐户和密码。
要使用 AtlasUI 创建 MongoDB 数据库,请打开浏览器窗口并登录 https://cloud.mongodb.com。 在您的集群页面中,单击Browse Collections 。 如果集群中没有数据库,您可以通过单击“添加我自己的数据”按钮来创建数据库。
提示将要求您提供数据库和集合名称。 为它们命名后,单击Create ,您就完成了! 您现在可以输入新文档或使用驱动程序连接到数据库。
管理您的 MongoDB 数据库
在本节中,我们将介绍一些有效管理 MongoDB 数据库的好方法。 您可以通过使用 MongoDB Compass 或通过集合来完成此操作。
使用集合
虽然关系数据库拥有定义明确的表和指定的数据类型和列,但 NoSQL 拥有集合而不是表。 这些集合没有任何结构,并且文档可能会有所不同——您可以拥有不同的数据类型和字段,而不必匹配同一集合中另一个文档的格式。
为了演示,让我们创建一个名为“Employee”的集合并向其中添加一个文档:
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) 如果插入成功,则返回WriteResult({ "nInserted" : 1 }) :
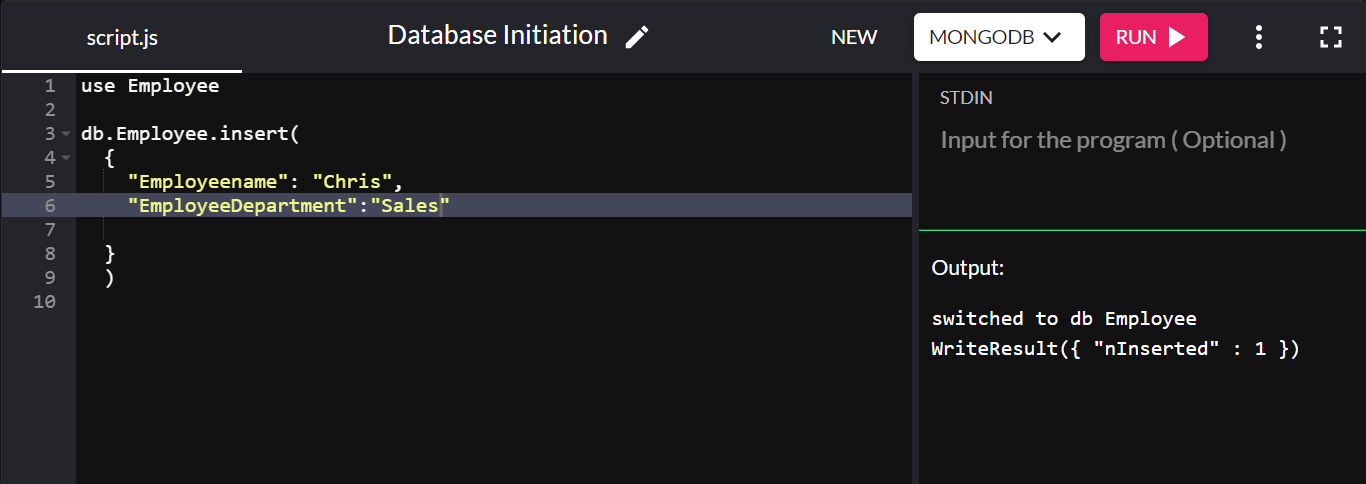
这里,“db”指的是当前连接的数据库。 “员工”是公司数据库中新创建的集合。
我们这里没有设置主键,因为 MongoDB 会自动创建一个名为“_id”的主键字段并为其设置默认值。
运行以下命令以查看 JSON 格式的集合:
db.Employee.find().forEach(printjson)输出:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }虽然“_id”值是自动分配的,但您可以更改默认主键的值。 这一次,我们将在“Employee”数据库中插入另一个文档,“_id”值为“1”:
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) 在运行命令db.Employee.find().forEach(printjson)我们得到以下输出:
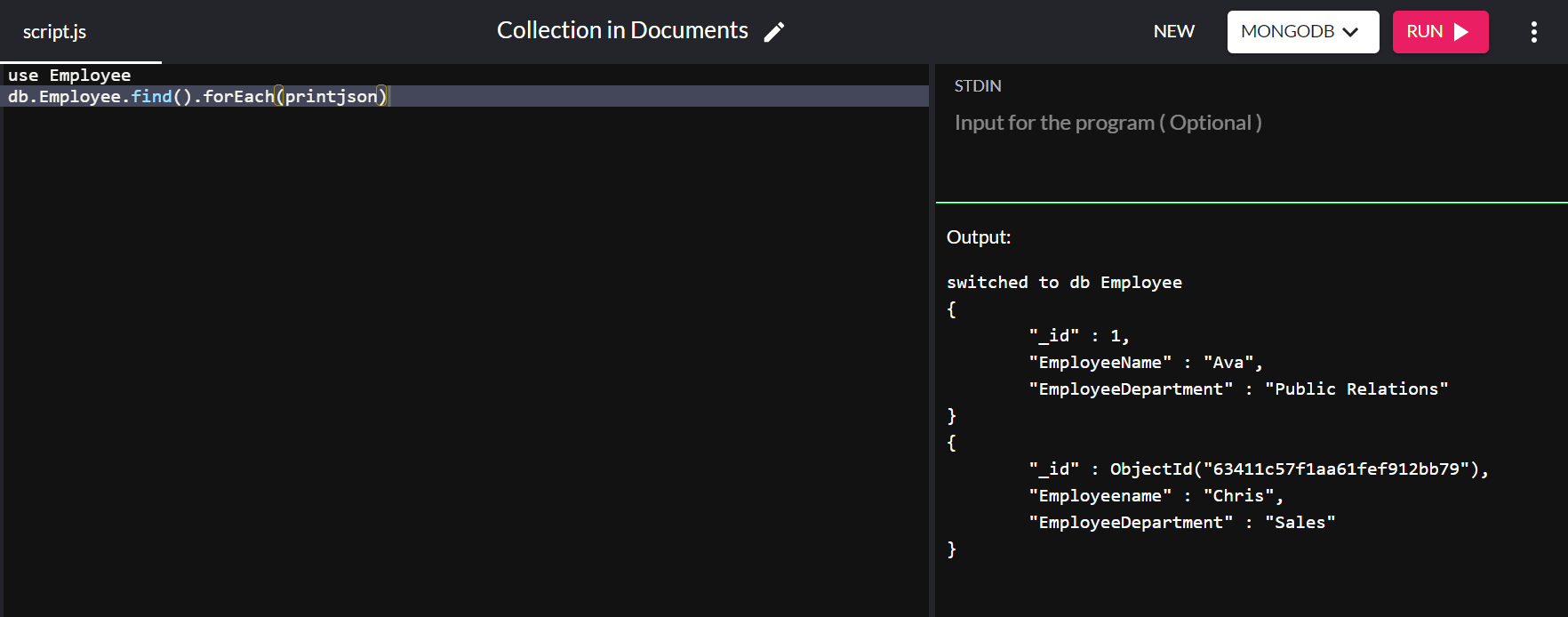
在上面的输出中,“Ava”的“_id”值设置为“1”,而不是自动分配一个值。
现在我们已经成功地将值添加到数据库中,我们可以使用以下命令检查它是否显示在我们系统中的现有数据库下:
show dbs 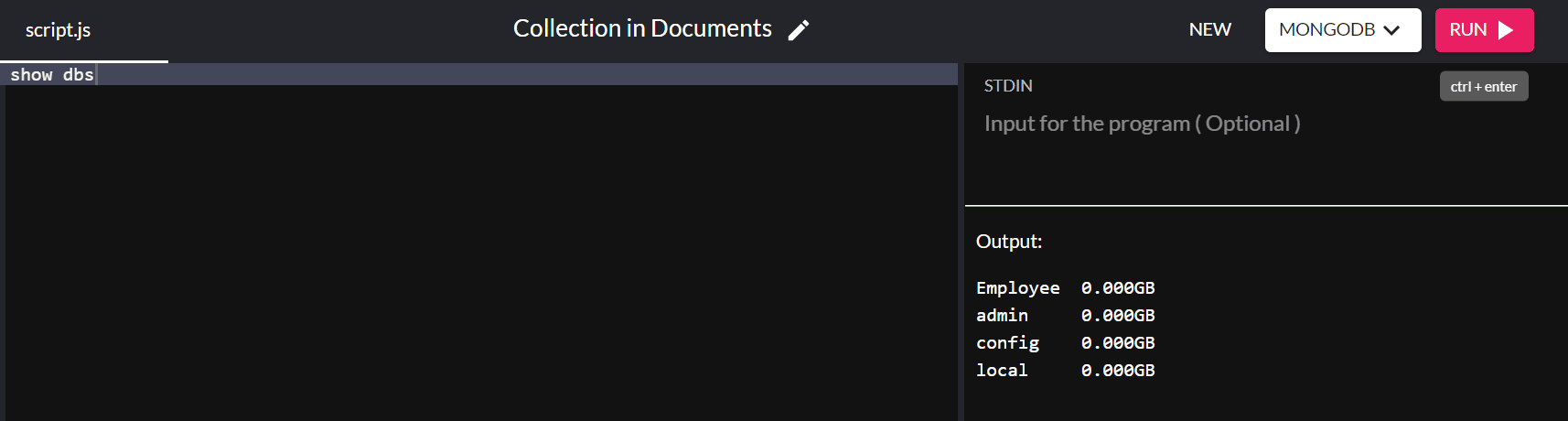
瞧! 您已成功在系统中创建数据库!
使用 MongoDB 指南针
虽然我们可以在 Mongo shell 中使用 MongoDB 服务器,但有时会很乏味。 您可能会在生产环境中遇到这种情况。
但是,有一个由 MongoDB 创建的指南针工具(适当地命名为 Compass)可以使它变得更容易。 它具有更好的 GUI 和附加功能,例如数据可视化、性能分析以及对数据、数据库和集合的 CRUD(创建、读取、更新、删除)访问。
您可以为您的操作系统下载 Compass IDE 并通过其简单的过程进行安装。
接下来,打开应用程序并通过粘贴连接字符串创建与服务器的连接。 如果找不到,可以单击分别填写连接字段。 如果您在安装 MongoDB 时没有更改端口号,只需单击连接按钮,就可以了! 否则,只需输入您设置的值并单击Connect 。
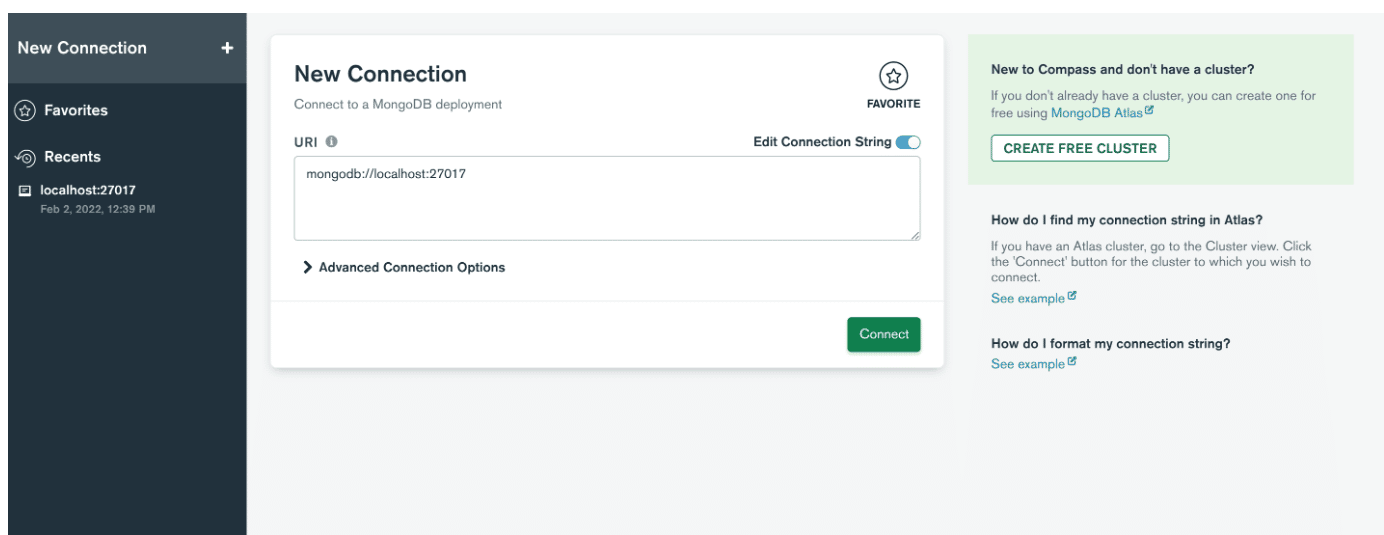
接下来,在 New Connection 窗口中提供主机名、端口和身份验证。
在 MongoDB Compass 中,您可以创建一个数据库并同时添加其第一个集合。 这是你如何做到的:
- 单击创建数据库以打开提示。
- 输入数据库的名称及其第一个集合。
- 单击创建数据库。
您可以通过单击数据库名称将更多文档插入数据库,然后单击集合名称以查看“文档”选项卡。 然后,您可以单击“添加数据”按钮将一个或多个文档插入您的集合中。
添加文档时,您可以一次输入一个文档,也可以将它们作为数组中的多个文档输入。 如果要添加多个文档,请确保将这些逗号分隔的文档括在方括号中。 例如:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }最后,单击插入将文档添加到您的集合中。 这是文档正文的样子:
{ "StudentID" : 1 "StudentName" : "JohnDoe" }这里,字段名称是“StudentID”和“StudentName”。 字段值分别为“1”和“JohnDoe”。
有用的命令
您可以通过角色管理和用户管理命令来管理这些集合。
用户管理命令
MongoDB 用户管理命令包含与用户相关的命令。 我们可以使用这些命令创建、更新和删除用户。
删除用户
此命令从指定数据库中删除单个用户。 下面是语法:
db.dropUser(username, writeConcern) 在这里, username是一个必填字段,其中包含有关用户的身份验证和访问信息的文档。 可选字段writeConcern包含创建操作的写入关注级别。 写入关注的级别可以由可选字段writeConcern确定。
在删除具有userAdminAnyDatabase角色的用户之前,请确保至少有一个其他用户具有用户管理权限。
在此示例中,我们将在测试数据库中删除用户“user26”:
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})输出:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); true创建用户
此命令为指定的数据库创建一个新用户,如下所示:
db.createUser(user, writeConcern) 在这里, user是一个必填字段,其中包含有关要创建的用户的身份验证和访问信息的文档。 可选字段writeConcern包含创建操作的写入关注级别。 写入关注的级别可以由可选字段writeConcern确定。
如果用户已存在于数据库中, createUser将返回重复用户错误。
您可以在测试数据库中创建一个新用户,如下所示:
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );输出如下:
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }grantRolesToUser
您可以利用此命令向用户授予其他角色。 要使用它,您需要牢记以下语法:
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) 您可以在上述角色中同时指定用户定义和内置角色。 如果要指定存在于运行grantRolesToUser的同一数据库中的角色,您可以使用文档指定角色,如下所述:
{ role: "<role>", db: "<database>" }或者,您可以简单地使用角色名称指定角色。 例如:
"readWrite"如果要指定存在于不同数据库中的角色,则必须使用不同的文档指定角色。
要授予数据库角色,您需要对指定数据库执行grantRole操作。
这是一个示例,可以为您提供清晰的图片。 例如,产品数据库中的用户 productUser00 具有以下角色:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] grantRolesToUser操作为“productUser00”提供 stock 数据库的readWrite角色和 products 数据库的 read 角色:
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })products 数据库中的用户 productUser00 现在拥有以下角色:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]用户信息
您可以使用usersInfo命令返回有关一个或多个用户的信息。 这是语法:
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } 在访问方面,用户可以随时查看自己的信息。 要查看其他用户的信息,运行该命令的用户必须具有包括对其他用户数据库的viewUser操作的权限。
运行userInfo命令时,您可以根据指定的选项获取以下信息:
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } 现在您已经大致了解了使用usersInfo命令可以完成什么,接下来可能会出现的明显问题是,哪些命令可以方便地查看特定用户和多个用户?
这里有两个方便的例子来说明这一点:
要查看特定用户的特定权限和信息,而不是凭据,对于“office”数据库中定义的用户“Anthony”,请执行以下命令:
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )如果要查看当前数据库中的用户,只能按名称提及用户。 例如,如果您在主数据库中并且主数据库中存在名为“Timothy”的用户,则可以运行以下命令:
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) 接下来,如果您希望查看不同用户的信息,可以使用数组。 您可以包含可选字段showCredentials和showPrivileges ,也可以选择将它们排除在外。 这是命令的样子:
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })revokeRolesFromUser
您可以利用revokeRolesFromUser命令从存在角色的数据库上的用户中删除一个或多个角色。 revokeRolesFromUser命令具有以下语法:
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) 在上述语法中,您可以在roles字段中指定用户定义和内置角色。 与grantRolesToUser命令类似,您可以在文档中指定要撤销的角色或使用其名称。
要成功执行revokeRolesFromUser命令,您需要对指定数据库执行revokeRole操作。
这是一个将要点带回家的示例。 products 数据库中的productUser00实体具有以下角色:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] 以下revokeRolesFromUser命令将删除用户的两个角色: products中的“读取”角色和“资产”数据库中的assetsWriter角色:
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )产品数据库中的用户“productUser00”现在只剩下一个角色:
"roles" : [ { "role" : "readWrite", "db" : "stock" } ]角色管理命令
角色授予用户对资源的访问权限。 管理员可以使用几个内置角色来控制对 MongoDB 系统的访问。 如果角色不涵盖所需的权限,您甚至可以进一步在特定数据库中创建新角色。
丢弃角色
使用dropRole命令,您可以从运行该命令的数据库中删除用户定义的角色。 要执行此命令,请使用以下语法:
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) 要成功执行,您必须对指定数据库执行dropRole操作。 以下操作将从“产品”数据库中删除writeTags角色:
想知道我们是如何将流量提高到 1000% 以上的吗?
加入 20,000 多人的行列,他们会通过 WordPress 内幕技巧获得我们的每周时事通讯!

use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )创建角色
您可以利用createRole命令创建角色并指定其权限。 该角色将应用于您选择在其上运行命令的数据库。 如果角色已存在于数据库中, createRole命令将返回重复角色错误。
要执行此命令,请遵循给定的语法:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )角色的权限将应用于创建角色的数据库。 该角色可以从其数据库中的其他角色继承权限。 例如,在“admin”数据库上创建的角色可以包括适用于集群或所有数据库的权限。 它还可以从其他数据库中存在的角色继承特权。
要在数据库中创建角色,您需要具备两件事:
- 该数据库上的
grantRole操作以提及新角色的权限以及提及要继承的角色。 - 该数据库资源上的
createRole操作。
以下createRole命令将在用户数据库上创建clusterAdmin角色:
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })grantRolesToRole
使用grantRolesToRole命令,您可以将角色授予用户定义的角色。 grantRolesToRole命令将影响执行该命令的数据库上的角色。
此grantRolesToRole命令具有以下语法:
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) 访问权限类似于grantRolesToUser命令——您需要对数据库执行grantRole操作才能正确执行该命令。
在以下示例中,您可以使用grantRolesToUser命令更新“products”数据库中的productsReader角色以继承productsWriter角色的权限:
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revokePrivilegesFromRole
您可以使用revokePrivilegesFromRole从执行命令的数据库上的用户定义角色中删除指定的权限。 为了正确执行,您需要牢记以下语法:
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )要撤销权限,“资源文档”模式必须匹配该权限的“资源”字段。 “actions”字段可以是完全匹配的,也可以是子集。
例如,考虑 products 数据库中的角色manageRole具有以下权限,将“managers”数据库指定为资源:
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }您不能仅从管理器数据库中的一个集合中撤消“插入”或“删除”操作。 以下操作不会导致角色发生变化:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) 要从角色manageRole撤消“插入”和/或“删除”操作,您需要完全匹配资源文档。 例如,以下操作仅撤销现有权限的“删除”操作:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )以下操作将从管理器数据库中的“执行”角色中删除多个权限:
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )角色信息
rolesInfo命令将返回指定角色的特权和继承信息,包括内置角色和用户定义角色。 您还可以利用rolesInfo命令检索范围为数据库的所有角色。
为了正确执行,请遵循以下语法:
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )要从当前数据库返回角色的信息,您可以指定其名称,如下所示:
{ rolesInfo: "<rolename>" }要从另一个数据库返回某个角色的信息,您可以使用提及该角色和该数据库的文档来提及该角色:
{ rolesInfo: { role: "<rolename>", db: "<database>" } }例如,以下命令返回在管理器数据库中定义的角色执行者的角色继承信息:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) 下一条命令将返回角色继承信息:执行命令的数据库上的accountManager :
db.runCommand( { rolesInfo: "accountManager" } )以下命令将返回在管理器数据库中定义的角色“执行”的权限和角色继承:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )要提及多个角色,您可以使用数组。 您还可以将数组中的每个角色作为字符串或文档提及。
仅当角色存在于执行命令的数据库中时,才应使用字符串:
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }例如,以下命令将返回三个不同数据库中三个角色的信息:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )您可以获得特权和角色继承,如下所示:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )嵌入 MongoDB 文档以获得更好的性能
MongoDB 等文档数据库可让您根据需要定义架构。 要在 MongoDB 中创建最佳模式,您可以嵌套文档。 因此,您可以构建一个与您的用例匹配的数据模型,而不是将您的应用程序与数据模型匹配。
嵌入式文档让您可以存储一起访问的相关数据。 在为 MongoDB 设计模式时,建议您默认嵌入文档。 仅在值得时才使用数据库端或应用程序端的连接和引用。
确保工作负载可以根据需要经常检索文档。 同时,文档还应该包含它需要的所有数据。 这对于您的应用程序的卓越性能至关重要。
下面,您会发现一些嵌入文档的不同模式:
嵌入式文档模式
您可以使用它在使用它们的文档中嵌入甚至复杂的子结构。 在单个文档中嵌入连接的数据可以减少获取数据所需的读取操作次数。 通常,您应该构建您的架构,以便您的应用程序在单个读取操作中接收其所有必需的信息。 因此,这里要记住的规则是一起使用的内容应该一起存储。
嵌入式子集模式
嵌入式子集模式是一种混合情况。 您可以将它用于一长串相关项目的单独集合,您可以将其中一些项目放在手边以供展示。
这是一个列出电影评论的示例:
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }现在,想象一千条类似的评论,但您只打算在放映电影时显示最近的两条。 在这种情况下,将该子集存储为电影文档中的列表是有意义的:
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</code简而言之,如果您经常访问相关项目的子集,请确保将其嵌入。
独立访问
您可能希望将子文档存储在它们的集合中,以将它们与父集合分开。
例如,以一家公司的产品线为例。 如果公司销售一小部分产品,您可能希望将它们存储在公司文档中。 但是,如果您想跨公司重复使用它们或通过他们的库存单位 (SKU) 直接访问它们,您还希望将它们存储在他们的集合中。
如果您独立操作或访问实体,请创建一个集合以单独存储它以实现最佳实践。
无限列表
在他们的文档中存储相关信息的简短列表有一个缺点。 如果您的列表继续不受检查地增长,则不应将其放在单个文档中。 这是因为您将无法长时间支持它。
有两个原因。 首先,MongoDB 对单个文档的大小有限制。 其次,如果您以太多频率访问文档,您会看到不受控制的内存使用造成的负面结果。
简单来说,如果一个列表开始无限增长,就做一个集合单独存储。
扩展参考模式
扩展参考模式类似于子集模式。 它还优化了您定期访问以存储在文档中的信息。
在这里,当一个文档引用同一集合中存在的另一个文档时,它被利用而不是列表。 同时,它还存储其他文档中的一些字段以供随时访问。
例如:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
磁盘延迟
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
系统内存
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
交换使用
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
操作计数器
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
连接
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
高数量比率表明操作不理想。 这些操作扫描大量文档以返回较小的部分。
扫码下单
它描述了所选查询样本期间每秒的平均速率。 它返回无法使用索引执行排序操作的排序结果。
队列
队列可以描述等待锁的操作数,写或读。 高队列可能描述了不是最优模式设计的存在。 它还可能表明存在冲突的写入路径,从而推动数据库资源的激烈竞争。
MongoDB 复制指标
以下是复制监控的主要指标:
复制 Oplog 窗口
该指标列出了主节点的复制 oplog 中可用的大致小时数。 如果次要滞后超过此数量,则它无法跟上并需要完全重新同步。
复制滞后
复制延迟定义为辅助节点在写入操作中落后于主节点的大致秒数。 高复制延迟将指向在复制方面面临困难的辅助节点。 考虑到连接的读/写问题,它可能会影响您的操作延迟。
复制空间
该指标是指主复制的 oplog 窗口和辅助复制延迟之间的差异。 如果此值变为零,则可能会导致辅助设备进入恢复模式。
操作计数器-repl
Opcounters -repl 定义为所选采样周期内每秒执行的复制操作的平均速率。 使用 opcounters -graph/metric,您可以查看指定实例的操作速度和操作类型的细分。
Oplog GB/小时
这被定义为主节点每小时生成的 oplog 的平均速率。 大量意外的 oplog 可能表明写入工作负载严重不足或存在模式设计问题。
MongoDB 性能监控工具
MongoDB 在 Cloud Manager、Atlas 和 Ops Manager 中内置了用于性能跟踪的用户界面工具。 它还提供了一些独立的命令和工具来查看更多基于原始的数据。 我们将讨论一些您可以从具有访问权限和适当角色的主机运行的工具,以检查您的环境:
蒙戈托普
您可以利用此命令来跟踪 MongoDB 实例在每个集合中写入和读取数据所花费的时间。 使用以下语法:
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
该命令返回副本集状态。 它是从执行方法的成员的角度执行的。
mongostat
您可以使用mongostat命令快速了解 MongoDB 服务器实例的状态。 为了获得最佳输出,您可以使用它来查看特定事件的单个实例,因为它提供了实时视图。
利用此命令监控基本服务器统计信息,例如锁定队列、操作故障、MongoDB 内存统计信息和连接/网络:
mongostat <options> <connection-string> <polling interval in seconds>数据库统计
此命令返回特定数据库的存储统计信息,例如索引数量及其大小、集合数据总量与存储大小的关系,以及与集合相关的统计信息(集合和文档的数量)。
db.serverStatus()
您可以利用db.serverStatus()命令来概览数据库的状态。 它为您提供了代表当前实例度量计数器的文档。 定期执行此命令以整理有关实例的统计信息。
collStats
collStats命令收集类似于dbStats在收集级别提供的统计信息。 它的输出包括集合中的对象计数、集合消耗的磁盘空间量、集合的大小以及有关给定集合的索引的信息。
您可以使用所有这些命令来提供数据库服务器的实时报告和监控,从而让您监控数据库性能和错误,并协助做出明智的决策以优化数据库。
如何删除 MongoDB 数据库
要删除您在 MongoDB 中创建的数据库,您需要通过 use 关键字连接到它。
假设您创建了一个名为“Engineers”的数据库。 要连接到数据库,您将使用以下命令:
use Engineers 接下来,键入db.dropDatabase()以摆脱此数据库。 执行后,这是您可以预期的结果:
{ "dropped" : "Engineers", "ok" : 1 } 您可以运行showdbs命令来验证数据库是否仍然存在。
概括
要从 MongoDB 中榨取每一滴价值,您必须对基础知识有深刻的理解。 因此,了解 MongoDB 数据库至关重要。 这需要先熟悉创建数据库的方法。
在本文中,我们阐明了可用于在 MongoDB 中创建数据库的不同方法,然后详细描述了一些漂亮的 MongoDB 命令,以使您始终掌握数据库。 最后,我们通过讨论如何利用 MongoDB 中的嵌入式文档和性能监控工具来确保您的工作流以最高效率运行,从而结束了讨论。
您对这些 MongoDB 命令有何看法? 我们是否错过了您希望在这里看到的某个方面或方法? 让我们在评论中知道!