
持久化存储:容器时代的长期记忆
已发表: 2023-04-17持久存储是指以非易失性方式保留数据,以便即使在设备或应用程序关闭或重新启动后数据仍然可用。 数据的存储和检索允许 Web 应用程序保存用户信息和状态并可靠地运行。
在单体应用程序中,存储访问很简单,因为服务器和存储在一起。 然而,地理分布式系统使访问变得更加复杂,因为存储系统必须对全球所有组件保持可用。
容器化使问题进一步复杂化,因为容器是轻量级的、无状态的和短暂的——不适合存储数据的特性。 因此,任何持久存储解决方案都必须能够与容器无缝协作,从而增加了另一层复杂性。
本文通过探索其类型、架构和用例来深入研究持久性存储。 它还提供了一个动手演示,说明了 Docker 中的卷存储和持久卷存储之间的区别。
持久存储的类型
非易失性存储有多种类型,包括传统的旋转磁盘(硬盘驱动器或 HDD)、固态驱动器 (SSD)、网络附加存储 (NAS) 和存储区域网络 (SAN)。
- HDD是机电数据存储设备,使用旋转的磁介质磁盘存储和检索数字数据。 磁盘使用可移动致动器臂上的磁头来读取和写入数据。
- SSD有时也称为半导体存储设备、固态设备或固态磁盘,使用集成电路组件持久存储数据,通常使用不包含移动部件的互连闪存设备。 它们的固定特性使它们比 HDD 更快、更可靠。
- 网络附加存储是一组 HDD、SSD 或两者,使用新技术文件系统 (NTFS) 或第四扩展文件系统 (EXT4) 等文件系统通过本地网络连接。
- SAN是联网的高速块级存储设备,如磁带库或磁盘阵列。 它们的连接在操作系统看来是本地存储,无法通过局域网 (LAN) 访问。
持久存储架构
持久存储有三种方法,每种方法都有独特的用例和局限性。
对象持久架构
对象持久架构方法使用对象关系映射 (ORM) 将数据作为对象存储在关系数据库或键值数据库中。 当数据没有定义的模式时,这种方法很有用,因为 ORM 会处理它的存储和检索。
块持久架构
块持久化架构使用块级存储设备,这在存储大文件时很有用。 这种方法在存储大量数据时很有用,因为您可以使用多个块来增加存储容量。
文件存储持久化架构
顾名思义,文件存储持久架构方法使用文件系统来存储数据。 一种方法涉及使用数据库服务器,它提供了一种集中存储数据的方式。 像 Kinsta 这样的云托管解决方案使用可以轻松连接到应用程序并提供持久性的数据库服务器。
Filestore 持久架构在需要频繁检索文件的应用程序以及需要管理它们的界面时很有用。
持久存储用例
本节讨论每种存储类型的一些用例。
对象持久存储
- 云存储:对象持久存储通常用于云存储解决方案中,用于存储和检索大量非结构化数据,例如图像、视频和文档。 云提供商使用对象存储为客户提供可扩展、高度可用且持久的存储服务。
- 大数据分析:对象持久存储用于大数据分析,以存储和管理通常用于数据分析、机器学习和 AI 的大型数据集。 对象存储允许快速高效地访问数据,使其成为大数据架构的关键组件。
- 内容分发网络:对象持久存储在内容分发网络 (CDN) 中用于在全球服务器网络中存储和分发内容,例如图像、视频和静态文件。 对象存储允许 CDN 向世界各地的用户提供高速内容,无论用户位于何处。
块持久存储
- 高性能计算 (HPC) :HPC 环境可快速高效地处理大量数据。 块持久存储允许 HPC 集群存储和检索大型数据集,例如科学模拟、天气建模和财务分析。 块存储通常是 HPC 的首选,因为它提供高性能、低延迟的数据访问,并允许并行输入/输出 (I/O) 操作,这可以显着缩短处理时间。
- 视频编辑:视频编辑应用程序需要对大型视频文件进行高性能和低延迟访问。 它们还必须适应每秒大量的 I/O 操作和低延迟,以实时渲染和编辑视频文件。 块存储提供了这些功能,使其成为视频编辑工作流的理想解决方案。
- 游戏:游戏应用程序还需要高性能和低延迟来访问游戏资产和玩家数据。 块存储可快速存储和检索大量数据,确保游戏环境能够及时加载并在游戏过程中保持响应。
文件存储持久存储
- 媒体和娱乐:视频编辑、动画和渲染应用程序通常使用持久存储。 这些应用程序需要对视频、音频和图像等大型媒体文件进行高性能和低延迟访问。 Filestore 提供了一个可以被多个客户端访问的共享文件系统,使其成为这些应用程序的理想存储解决方案。
- Web 内容管理: Web 内容管理系统 (CMS) 使用共享文件系统中的文件存储持久存储来存储和管理网站内容,例如文本、图像和多媒体文件。 Filestore 为网站内容提供了一个中心位置,使管理和更新变得更加容易。 它还使多个用户能够同时处理相同的内容,从而提高协作和生产力。
容器中的持久存储
容器轻巧、便携、安全且直接,提供了不同应用程序之间的融合。 他们必须有一种机制来在容器重新启动和删除之间保留数据。 容器与传统应用程序一样具有文件存储或文件系统,但每当您使用新更改重建它们时,您都会丢失所有非持久性数据。
这就是容器提供包含卷存储或安装存储卷的选项的原因。 容器将存储卷视为一个目录。 写入卷的任何数据都会进入主机文件系统。
容器的持久存储必须以这种方式工作,因为重新启动容器会创建一个新实例并丢弃旧实例。 如果容器没有数据的一致视图,则当容器重新启动时数据将消失。 存储卷在会话和容器重启之间保留数据,允许容器即使在移动或重启时也能保持其状态。
体积与持久体积
容器提供了两种存储持久数据的方式:使用卷和持久卷。 它们之间存在显着差异。 容器管理卷存储中的数据。 当您停止容器时,数据会保留并在您重新启动容器时可用。 但是,当您删除或删除容器时,数据会丢失,因为您还会删除基础卷存储。
持久卷存储或绑定挂载是一种将数据存储在容器文件系统之外的方法。 这样,即使您删除容器,数据也不会丢失。 它一直存在,直到被手动删除。
以下部分通过示例演示了这两种卷类型。
容器持久存储演示
我们创建了一个小型 Web 应用程序来演示 Docker 容器的持久存储。 您可以安装 Docker 并从此 GitHub 存储库获取代码。
该应用程序是一个基本表单,包含 2 个用于用户输入的字段:
- 标题
- 文档文本
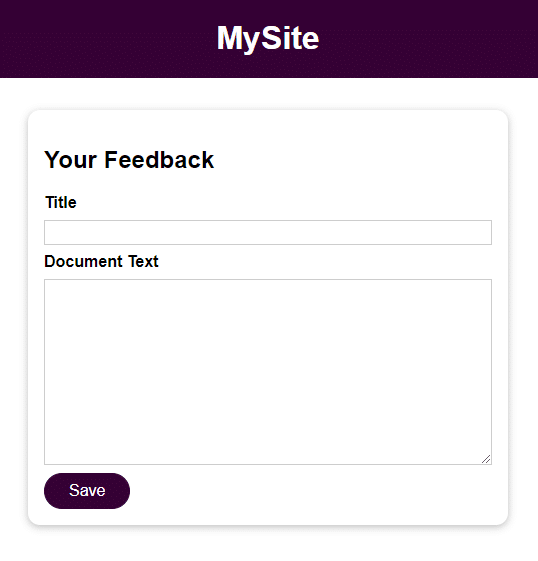
保存用户输入后,您可以通过使用标题字段中提供的名称打开反馈目录中的文件来访问它。 文档文本字段的输入是文件的内容。
如何使用卷存储
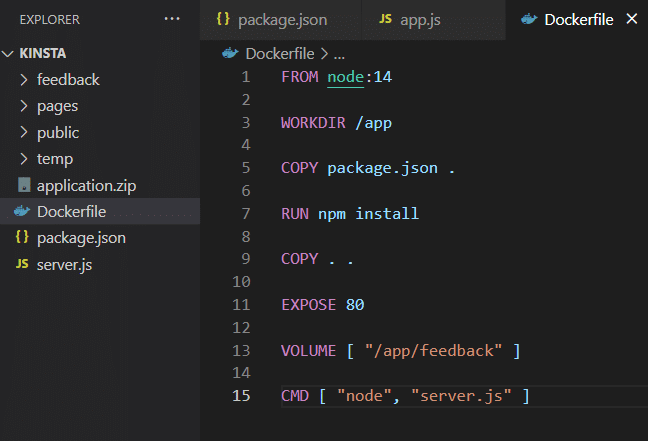
在您自己的机器上安装应用程序后,它可以使用Dockerfile中所示的卷存储。
现在,您构建映像并运行容器。 为此,请执行以下命令。

docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app feedback-node:volumes 
应用程序运行后,导航到 localhost:3000 以提交反馈。
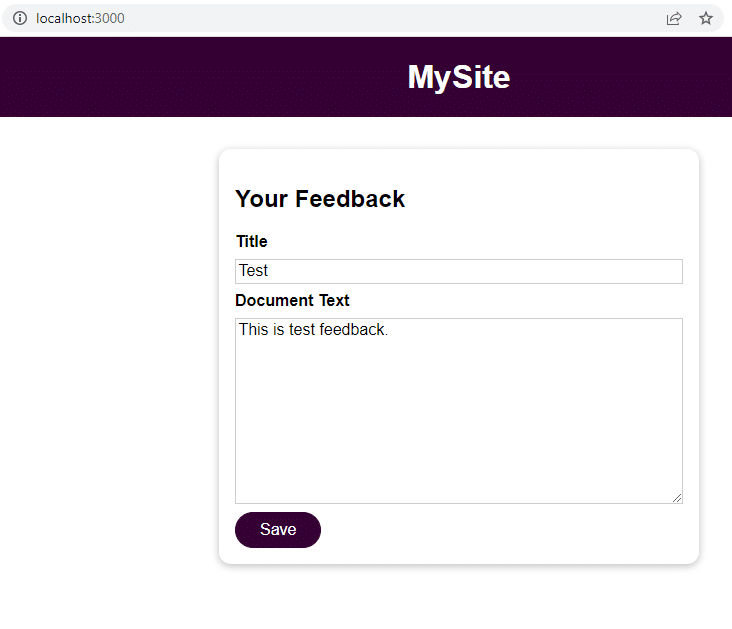
单击保存并导航到localhost:3000/feedback/test.txt以查看输入是否成功存储。
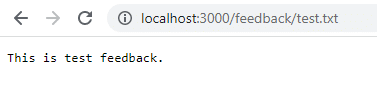
删除并重新启动容器以查看输入是否仍然存在。
docker stop feedback-app docker start feedback-app如果您现在访问相同的 URL,您会看到反馈仍然存在。 但是如果你删除容器并重新启动它会发生什么?
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app feedback-node:volumes重新启动后,如果您返回到该 URL,它不再存在,因为在您删除容器时数据丢失了。 卷数据仅在停止容器时保留,而不是在删除容器时保留。
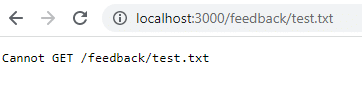
为了缓解这个问题并在您删除容器时保留数据,您必须使用持久卷存储或命名存储。 首先,您应该清理容器和图像。
docker stop feedback-app docker rm feedback-app docker rmi feedback-node:volumes如何使用持久卷存储
在对此进行测试之前,您必须从 Dockerfile 中删除 VOLUME 属性并重建映像。
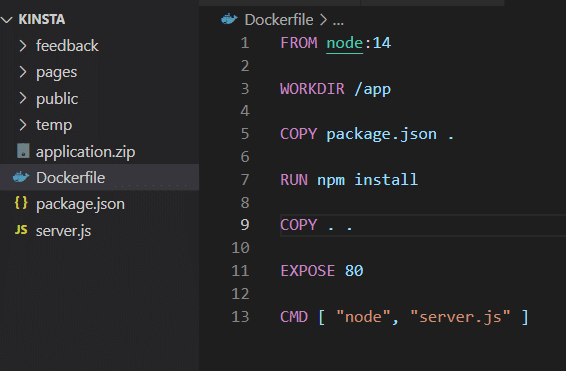
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumes 如您所见,在第二个命令中,您使用-v标志定义容器外部的持久卷,即使您移除容器,该卷仍然存在。
与上一步一样,尝试添加反馈并在停止、删除和重新启动容器后访问它。
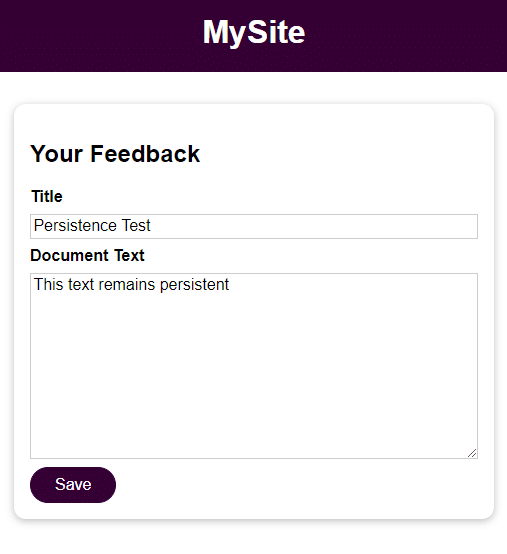
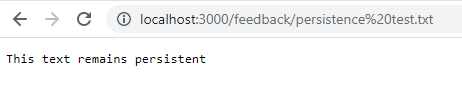
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumes如您所见,即使在停止并删除容器后,数据仍可访问并保留。
概括
持久存储对于容器化应用程序至关重要,因为它允许在容器生命周期之外持久保存数据。 容器化应用程序的两种主要持久存储类型是卷和绑定挂载,每种都有其优点和用例。
卷存储在容器的文件系统中,而绑定挂载可直接在主机上访问。
持久存储使数据能够在容器之间共享,从而可以构建复杂的多层应用程序。 持久化存储对于确保容器化应用程序的稳定性和连续性至关重要,它提供了一种可靠且灵活的方式来存储关键数据。
如果您使用 Docker 来开发 Web 应用程序,您会发现使用 Kinsta 的应用程序托管服务配置 Dockerfile 部署非常简单。