
Robots.txt:它是什么以及如何创建它(完整指南)
已发表: 2023-05-05如果您拥有一个网站或管理其内容,您可能听说过 robots.txt。 它是一个文件,指示搜索引擎机器人如何抓取和索引您的网站页面。 尽管它在搜索引擎优化 (SEO) 中很重要,但许多网站所有者忽视了精心设计的 robots.txt 文件的重要性。
在本完整指南中,我们将探讨什么是 robots.txt、为什么它对 SEO 很重要,以及如何为您的网站创建 robots.txt 文件。
什么是 Robots.txt 文件?
robots.txt 是一个文件,它告诉搜索引擎机器人(也称为爬虫或蜘蛛)应该抓取或不抓取网站的哪些页面或部分。 它是位于网站根目录中的纯文本文件,通常包含网站管理员希望阻止搜索引擎索引或抓取的目录、文件或 URL 的列表。
这是 robots.txt 文件的样子:

为什么 Robots.txt 很重要?
robots.txt 对您的网站很重要的三个主要原因:
1.最大化抓取预算
“抓取预算”代表 Google 在任何给定时间将在您的网站上抓取的页面数量。 数量取决于您网站上反向链接的大小、健康状况和数量。
抓取预算很重要,因为如果您网站上的页面数量超过抓取预算,您将拥有未编入索引的页面。
此外,未编入索引的页面将不会获得任何排名。
通过使用 robots.txt 来阻止无用的页面,Googlebot(Google 的网络抓取工具)可能会将您的更多抓取预算花在重要的页面上。
2. 屏蔽非公开页面
您的网站上有许多您不想编入索引的页面。
例如,您可能有一个内部搜索结果页面或登录页面。 这些页面需要存在。 但是,您不希望随机的人落在他们身上。
在这种情况下,您将使用 robots.txt 来防止搜索引擎抓取工具和机器人访问某些页面。
3.防止资源索引
有时您会希望 Google 从搜索结果中排除 PDF、视频和图像等资源。
可能您希望将这些资源保密,或者您希望 Google 更专注于重要内容。
在这种情况下,使用 robots.txt 是防止它们被编入索引的最佳方法。
Robots.txt 文件如何工作?
Robots.txt 文件指示搜索引擎机器人应该或不应该抓取或索引网站的哪些页面或目录。
在爬行时,搜索引擎机器人会查找并跟踪链接。 这个过程通过数十亿个链接和网站引导他们从站点 X 到站点 Y 再到站点 Z。
当机器人访问站点时,它做的第一件事就是查找 robots.txt 文件。
如果它检测到一个,它将在执行任何其他操作之前读取该文件。
例如,假设您希望允许除 DuckDuckGo 之外的所有机器人抓取您的网站:
User-agent: DuckDuckBot Disallow: /
注意: robots.txt 文件只能给出指令; 它不能强加于人。 它类似于行为准则。 好的机器人(例如搜索引擎机器人)会遵守规则,而坏的机器人(例如垃圾邮件机器人)会忽略它们。
如何查找 Robots.txt 文件?
robots.txt 文件与您网站上的任何其他文件一样,托管在您的服务器上。
任何网站的robots.txt文件都可以通过输入完整的首页网址,然后在末尾加上/robots.txt来访问,比如https://pickupwp.com/robots.txt。
但是,如果该网站没有 robots.txt 文件,您将收到“404 Not Found”错误消息。
如何创建 Robots.txt 文件?
在展示如何创建 robots.txt 文件之前,让我们先看看 robots.txt 语法。
robots.txt 文件的语法可以分解为以下部分:
- 用户代理:这指定记录适用的机器人或爬虫。 例如,“User-agent: Googlebot”仅适用于 Google 的搜索爬虫,而“User-agent: *”适用于所有爬虫。
- Disallow:这指定机器人不应抓取的页面或目录。 例如,“Disallow: /private/”将阻止机器人抓取“private”目录中的任何页面。
- 允许:指定应允许机器人抓取的页面或目录,即使父目录是不允许的。 例如,“允许:/public/”将允许机器人抓取“public”目录中的任何页面,即使父目录是不允许的。
- 抓取延迟:指定机器人在抓取网站之前应等待的时间(以秒为单位)。 例如,“Crawl-delay: 10”会指示机器人在抓取网站之前等待 10 秒。
- 站点地图:这指定了网站站点地图的位置。 例如,“站点地图:https://www.example.com/sitemap.xml”会告知机器人网站站点地图的位置。
以下是 robots.txt 文件的示例:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
注意:请务必注意,robots.txt 文件区分大小写,因此在指定 URL 时使用正确的大小写非常重要。
例如,/public/ 与 /Public/ 不同。
另一方面,像“Allow”和“Disallow”这样的指令不区分大小写,因此是否大写取决于您。
了解 robots.txt 语法后,您可以使用 robots.txt 生成器工具创建 robots.txt 文件或自己创建一个。
以下是如何通过四个步骤创建 robots.txt 文件:
1.新建一个文件,命名为robots.txt
只需使用任何文本编辑器或 Web 浏览器打开 .txt 文档。
接下来,将文档命名为 robots.txt。 要工作,它必须命名为 robots.txt。
完成后,您现在可以开始输入指令。
2. 将指令添加到 Robots.txt 文件
robots.txt 文件包含一组或多组指令,每组指令包含多行指令。
每个组都以“用户代理”开头,并包含以下数据:
- 该组适用于谁(用户代理)
- 代理可以访问哪些目录(页面)或文件?
- 代理不能访问哪些目录(页面)或文件?
- 站点地图(可选),用于通知搜索引擎您认为重要的站点和文件。
不匹配任何这些指令的行将被爬虫忽略。
例如,您想阻止 Google 抓取您的 /private/ 目录。
它看起来像这样:
User-agent: Googlebot Disallow: /private/

如果您有针对 Google 的进一步说明,请将它们放在下面的单独一行中,如下所示:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
此外,如果您完成了 Google 的特定说明并想要创建一组新的指令。
例如,如果您想阻止所有搜索引擎抓取您的 /archive/ 和 /support/ 目录。
它看起来像这样:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
完成后,您可以添加站点地图。
您完成的 robots.txt 文件应如下所示:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
接下来,保存您的 robots.txt 文件。 请记住,它必须命名为 robots.txt。
有关更多有用的 robots.txt 规则,请查看来自 Google 的有用指南。
3.上传robots.txt文件
将 robots.txt 文件保存到您的计算机后,将其上传到您的网站,供搜索引擎抓取。
不幸的是,没有工具可以帮助完成此步骤。
robots.txt 文件的上传取决于您网站的文件结构和虚拟主机。
有关如何上传 robots.txt 文件的说明,请在线搜索或联系您的托管服务提供商。
4. 测试你的 Robots.txt
上传 robots.txt 文件后,接下来您可以检查是否有人可以看到它以及 Google 是否可以阅读它。
只需在浏览器中打开一个新选项卡并搜索您的 robots.txt 文件。
例如,https://pickupwp.com/robots.txt。
如果您看到 robots.txt 文件,则您已准备好测试标记(HTML 代码)。
为此,您可以使用 Google robots.txt 测试器。
注意:您已设置 Search Console 帐户以使用 robots.txt 测试器测试您的 robots.txt 文件。
robots.txt 测试器会发现任何语法警告或逻辑错误并突出显示它们。
另外,它还在编辑器下方显示警告和错误。
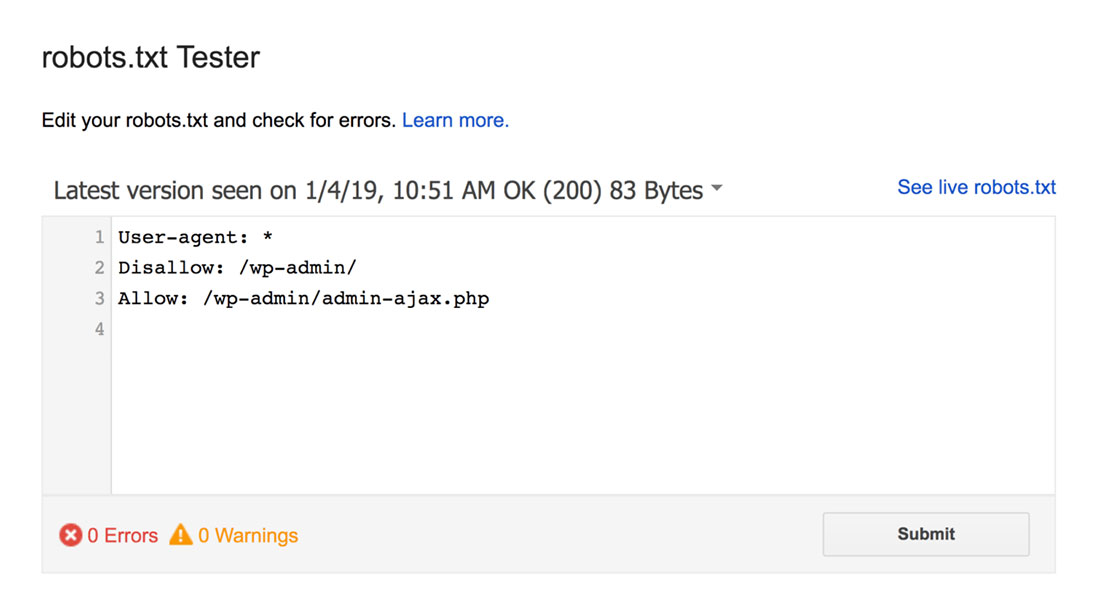
您可以在页面上编辑错误或警告,并根据需要经常重新测试。
请记住,在页面上所做的更改不会保存到您的网站。
要进行任何更改,请将其复制并粘贴到您网站的 robots.txt 文件中。
Robots.txt 最佳实践
在创建 robots.txt 文件时请牢记这些最佳做法,以避免一些常见错误。
1. 为每个指令使用新行
为防止搜索引擎抓取工具混淆,请将每个指令添加到 robots.txt 文件中的新行。 这适用于 Allow 和 Disallow 规则。
例如,如果您不希望网络爬虫爬取您的博客或联系页面,请添加以下规则:
Disallow: /blog/ Disallow: /contact/
2.每个用户代理只使用一次
如果您反复使用相同的用户代理,机器人不会有任何问题。
但是,只使用一次可以使事情井井有条并减少人为错误的机会。
3.使用通配符简化指令
如果您要阻止大量页面,为每个页面添加一条规则可能会很耗时。 幸运的是,您可以使用通配符来简化指令。
通配符是可以代表一个或多个字符的字符。 最常用的通配符是星号 (*)。
例如,如果您想阻止所有以 .jpg 结尾的文件,您可以添加以下规则:
Disallow: /*.jpg
4.使用“$”指定URL的结尾
美元符号 ($) 是另一个可用于标识 URL 结尾的通配符。 如果您想限制特定页面而不是其后的页面,这将很有用。
假设您想屏蔽联系页面而不是联系成功页面,您可以添加以下规则:
Disallow: /contact$
5. 使用井号 (#) 添加评论
爬虫会忽略以井号 (#) 开头的所有内容。
因此,开发人员经常使用哈希向 robots.txt 文件添加注释。 它使文档井井有条且可读。
例如,如果你想阻止所有以 .jpg 结尾的文件,你可以添加以下注释:
# Block all files that end in .jpg Disallow: /*.jpg
这有助于任何人了解该规则的用途及其存在的原因。
6. 为每个子域使用单独的 Robots.txt 文件
如果您的网站有多个子域,建议为每个子域创建一个单独的 robots.txt 文件。 这样可以使事情井井有条,并帮助搜索引擎爬虫更轻松地掌握您的规则。
包起来!
robots.txt 文件是一个有用的 SEO 工具,因为它指示搜索引擎机器人将哪些内容编入索引,哪些不编入索引。
但是,谨慎使用它很重要。 由于配置错误会导致您的网站完全取消索引(例如,使用 Disallow: /)。
通常,好的方法是允许搜索引擎尽可能多地扫描您的站点,同时保留敏感信息并避免重复内容。 例如,您可以使用 Disallow 指令来阻止特定页面或目录,或者使用 Allow 指令来覆盖特定页面的 Disallow 规则。
还值得一提的是,并非所有机器人都遵循 robots.txt 文件中提供的规则,因此它不是控制索引内容的完美方法。 但它仍然是您的 SEO 策略中的一个有价值的工具。
我们希望本指南能帮助您了解什么是 robots.txt 文件以及如何创建它。
有关更多信息,您可以查看这些其他有用的资源:
- 给新博主的 15 个可行的博客技巧
- 释放长尾关键词的力量(新手指南)
最后,在 Twitter 上关注我们,定期更新新文章。