
WordPress robots.txt 文件……它是什么以及它的作用
已发表: 2020-11-25你有没有想过 robots.txt 文件是什么以及它的作用? Robots.txt 用于与 Google 和其他搜索引擎使用的网络爬虫(称为机器人)进行通信。 它告诉他们要索引您网站的哪些部分以及忽略哪些部分。 因此,robots.txt 文件可以帮助(或可能破坏!)您的 SEO 工作。 如果您希望您的网站排名良好,那么对 robots.txt 的良好理解至关重要!
Robots.txt 位于何处?
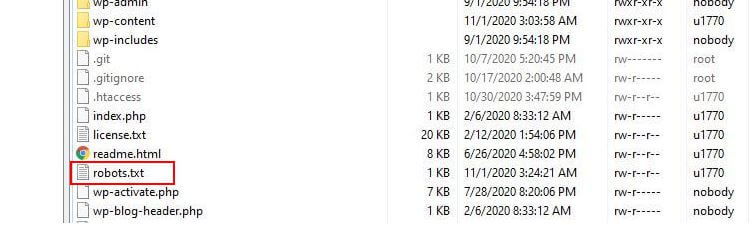
WordPress 通常运行一个所谓的“虚拟”robots.txt 文件,这意味着它不能通过 SFTP 访问。 但是,您可以访问 yourdomain.com/robots.txt 查看其基本内容。 你可能会看到这样的东西:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php第一行指定规则将应用于哪些机器人。 在我们的示例中,星号表示规则将应用于所有机器人(例如来自 Google、Bing 等的机器人)。
第二行定义了阻止机器人访问 /wp-admin 文件夹的规则,第三行声明允许机器人解析 /wp-admin/admin-ajax.php 文件。
添加您自己的规则
对于一个简单的 WordPress 网站,WordPress 应用于 robots.txt 文件的默认规则可能绰绰有余。 但是,如果您想要更多控制权并能够添加自己的规则,以便向搜索引擎机器人提供有关如何索引您的网站的更具体说明,那么您将需要创建自己的物理 robots.txt 文件并将其放在根目录下你的安装目录。
有几个原因可能需要重新配置您的 robots.txt 文件并定义这些机器人将被允许抓取的确切内容。 一个关键原因是与机器人抓取您的网站所花费的时间有关。 谷歌(和其他)不允许机器人在每个网站上花费无限的时间......对于数以万亿计的页面,他们必须采取更细致的方法来处理他们的机器人将抓取的内容以及他们将忽略的内容,以试图提取最有用的信息关于一个网站。

使用 Pressidium 托管您的网站
60 天退款保证
当您允许机器人抓取您网站上的所有页面时,部分抓取时间会花在不重要甚至不相关的页面上。 这使他们有更少的时间来处理您网站中更相关的区域。 通过禁止机器人访问您网站的某些部分,您可以增加机器人从您网站最相关部分提取信息的时间(希望最终被索引)。 由于抓取速度更快,Google 更有可能重新访问您的网站并保持他们对您网站的索引是最新的。 这意味着新的博客文章和其他新鲜内容可能会更快地被索引,这是个好消息。
编辑 Robots.txt 的示例
robots.txt 提供了足够的自定义空间。 因此,我们提供了一系列规则示例,可用于指示机器人如何索引您的网站。
允许或禁止机器人
首先,让我们看看如何限制特定的机器人。 为此,我们需要做的就是将星号 (*) 替换为我们要阻止的机器人用户代理的名称,例如“MSNBot”。 此处提供了已知用户代理的完整列表。
User-agent: MSNBot Disallow: /在第二行添加破折号将限制机器人对所有目录的访问。
为了只允许一个机器人抓取我们的网站,我们将使用两步过程。 首先,我们将这个机器人设置为例外,然后禁止所有这样的机器人:
User-agent: Google Disallow: User-agent: * Disallow: /为了允许访问所有内容的所有机器人,我们添加了这两行:
User-agent: * Disallow:只需创建一个 robots.txt 文件然后将其留空即可实现相同的效果。
阻止对特定文件的访问
想要阻止机器人索引您网站上的某些文件吗? 这很容易! 在下面的示例中,我们阻止了搜索引擎访问我们网站上的所有 .pdf 文件。
User-agent: * Disallow: /*.pdf$“$”符号用于定义 URL 的结尾。 由于这是区分大小写的,因此仍会抓取名为 my.PDF 的文件(注意大写字母)。
复杂的逻辑表达式
一些搜索引擎,如谷歌,了解更复杂的正则表达式的使用。 但需要注意的是,并非所有搜索引擎都能理解 robots.txt 中的逻辑表达式。
一个例子是使用 $ 符号。 在 robots.txt 文件中,此符号表示 URL 的结尾。 因此,在以下示例中,我们阻止了搜索机器人读取和索引以 .php 结尾的文件
Disallow: /*.php$这意味着 /index.php 不能被索引,但 /index.php?p=1 可以。 这仅在非常特定的情况下有用,需要谨慎使用,否则您可能会阻止机器人访问您无意访问的文件!

您还可以通过分别指定适用于它们的规则来为每个机器人设置不同的规则。 下面的示例代码将限制所有机器人对 wp-admin 文件夹的访问,同时阻止 Bing 搜索引擎对整个站点的访问。 您不一定想这样做,但它是一个有用的演示,说明 robots.txt 文件中的规则有多灵活。
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /XML 站点地图
XML 站点地图确实可以帮助搜索机器人了解您网站的布局。 但为了有用,机器人需要知道站点地图的位置。 “站点地图指令”用于明确告诉搜索引擎a)您网站的站点地图存在,以及b)他们可以在哪里找到它。
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:您还可以指定多个站点地图位置:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* Disallow机器人抓取延迟
另一个可以通过 robots.txt 文件实现的功能是告诉机器人“减慢”它们对您网站的抓取速度。 如果您发现您的服务器因高 bot 流量级别而过载,这可能是必要的。 为此,您需要指定要减慢速度的用户代理,然后添加延迟。
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10此示例中的引号 (10) 是您希望在抓取网站上的各个页面之间发生的延迟。 因此,在上面的示例中,我们要求 Bing Bot 在它爬取的每个页面之间暂停 10 秒钟,这样做给我们的服务器一点喘息的空间。
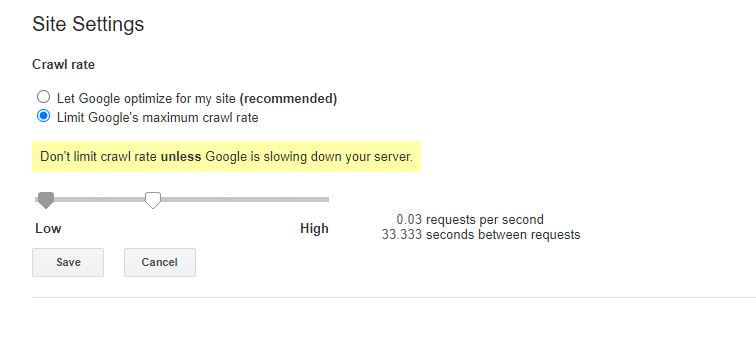
关于这个特定 robots.txt 规则的唯一一点坏消息是 Google 的机器人不尊重它。 但是,您可以在 Google Search Console 中指示他们的机器人放慢速度。
robots.txt 规则注意事项:
- 所有 robots.txt 规则都区分大小写。 认真打字!
- 确保在行首的命令之前没有空格。
- robots.txt 中所做的更改可能需要 24-36 小时才能被机器人注意到。
如何测试和提交您的 WordPress robots.txt 文件
当您创建了一个新的 robots.txt 文件时,值得检查其中没有错误。 您可以使用 Google Search Console 来执行此操作。
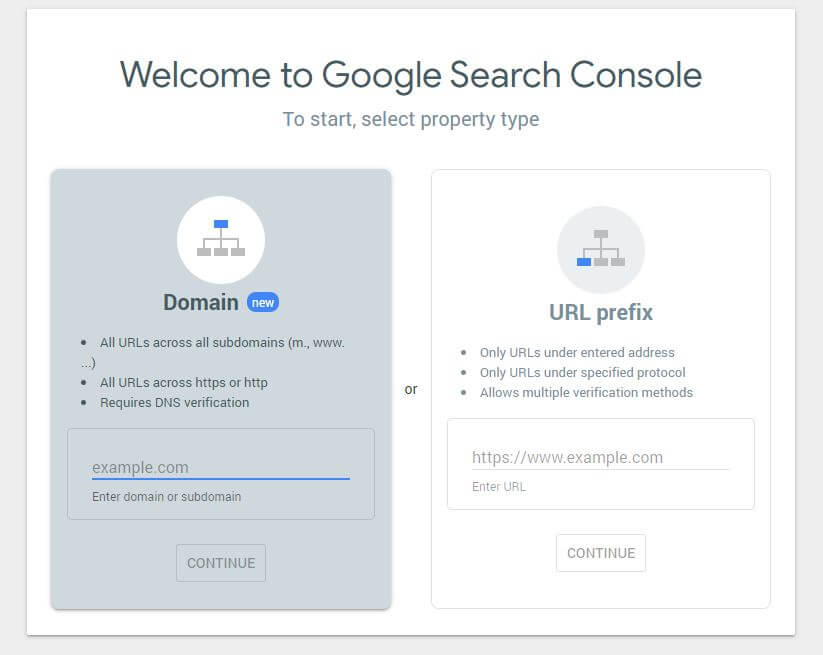
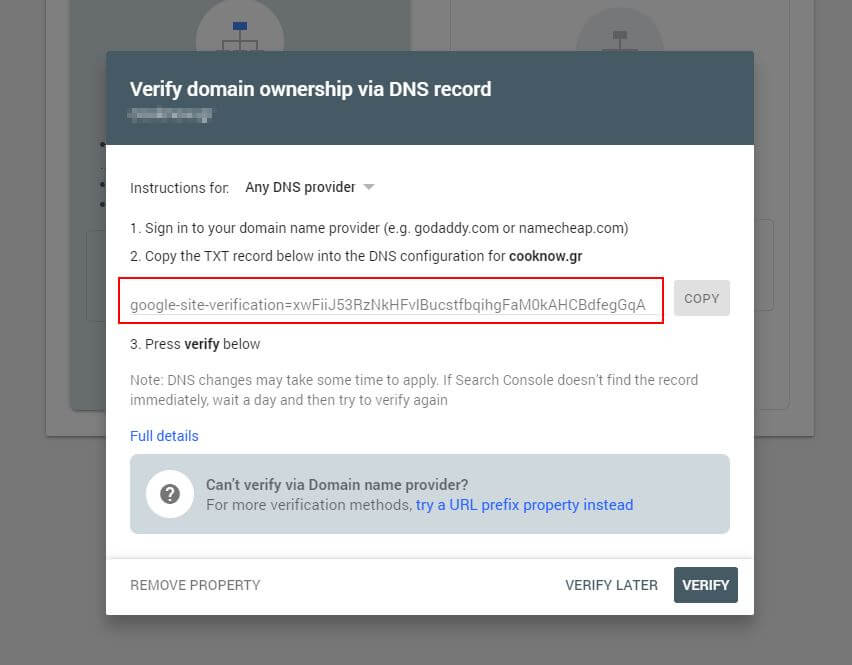
首先,您必须提交您的域(如果您还没有用于您的网站设置的 Search Console 帐户)。 Google 将为您提供一个 TXT 记录,需要将其添加到您的 DNS 中以验证您的域。
一旦此 DNS 更新传播(感觉不耐烦......尝试使用 Cloudflare 管理您的 DNS),您可以访问 robots.txt 测试器并检查是否有任何关于您的 robots.txt 文件内容的警告。
您可以做的另一件事来测试您现有的规则是否具有预期的效果是使用像 Ryte 这样的 robots.txt 测试工具。
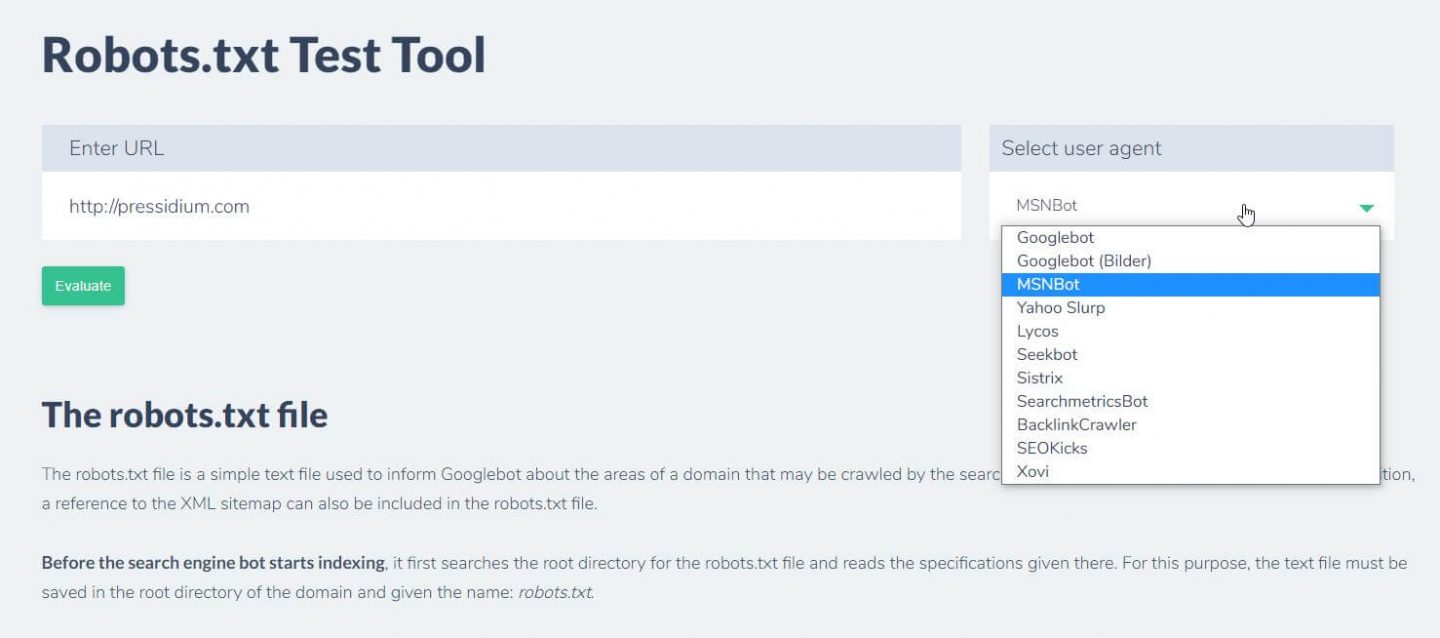
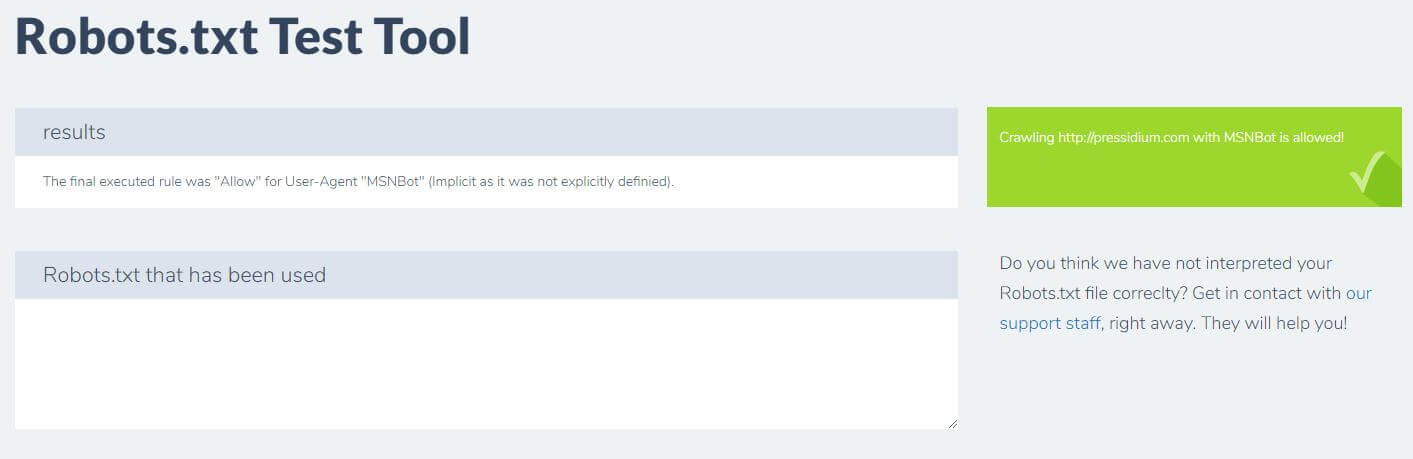
您只需输入您的域并从右侧面板中选择一个用户代理。 提交后,您将看到结果。
结论
了解如何使用 robots.txt 是开发人员工具包中的另一个有用工具。 如果您从本教程中获得的唯一内容是能够检查您的 robots.txt 文件是否没有阻止像 Google 这样的机器人(您不太可能想要这样做),那么这不是坏事! 同样,如您所见,robots.txt 为您的网站提供了一整套更细粒度的控制,这可能有一天会派上用场。