
了解數據庫分片的入門
已發表: 2022-11-05創建網站是在 Internet 上設置您的存在的第一步。 為了長期繁榮,您還必須確保您的網站可以擴展以適應增長。 第一步是實現一個可以隨您擴展的數據庫。 否則,您可能會遇到查詢性能緩慢和數據庫中斷的風險。
這篇文章將討論如何使用數據庫分片來實現數據的高可擴展性和可用性。 我們還將討論分片的缺點以及您可以使用的不同分片架構。
什麼是數據庫分片?
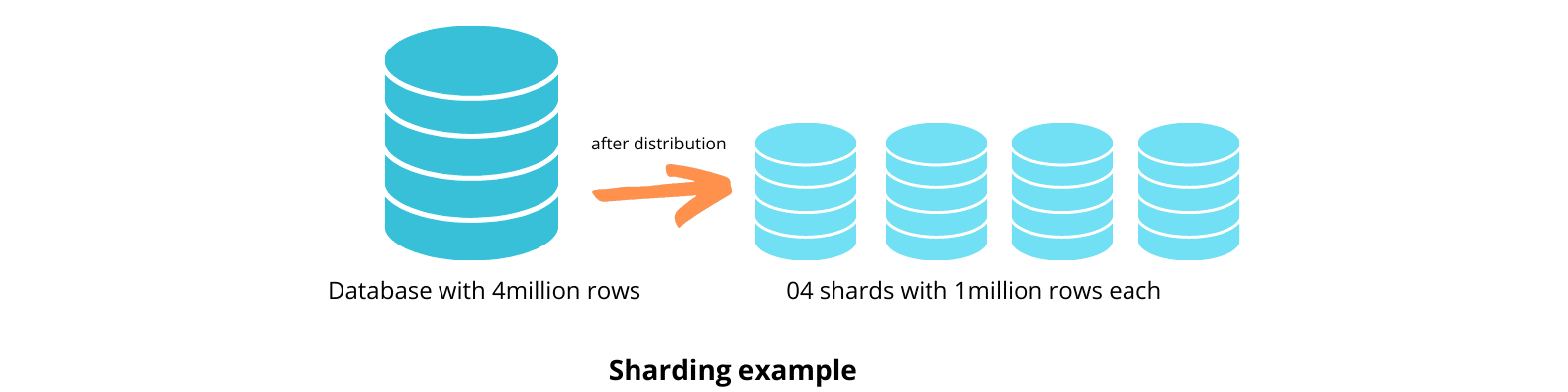
分片是一種優化技術,可將表分佈在其他數據庫服務器上。 這就像分區,兩者都涉及將數據分解為更小的子集。 不同之處在於分片將這些子集分發到不同的服務器,同時將它們分區存儲在一個數據庫中。 這些服務器使用相同的數據庫引擎和硬件類型來為所有分片實現相似的性能水平。
分片旨在實現無共享架構,消除處理瓶頸和單點故障。
您可以通過兩種方式實現分片——水平和垂直。 水平分片按行劃分錶,垂直分錶按列劃分錶。
在這方面,分片就像分區,將大表分成更小的表。
水平分片對於大多數查詢返回行子集的數據庫是有效的,例如一次返回數據(如姓名、地址、電子郵件等)的客戶數據庫。
垂直分片對於查詢返回單列的數據庫是有效的。 例如,如果客戶數據庫分別返回客戶的姓名或電子郵件,您可以將姓名和電子郵件分成不同的集群。
數據庫分片的好處
以下是數據庫分片的一些優點。
改進的水平縮放
您可以垂直或水平擴展數據庫。 垂直擴展是指向服務器添加更多中央處理器 (CPU) 和隨機存取存儲器 (RAM) 以提高性能。 對於中小型數據庫,垂直擴展是一個有用的解決方案。 但是,隨著數據的增長,垂直擴展變得不可行。 您只能為單個服務器添加這麼多的功能。
水平縮放更靈活。 它使您能夠通過向系統添加更多服務器來根據需要擴展數據庫。 這些服務器中的每一個都為不同的數據庫分片提供資源。 這分散了工作負載並提高了系統處理更多請求的能力。
更快的查詢響應時間
分片只有幾行和幾列。 因此,處理數據庫查詢所需的時間更少。 相比之下,非分片數據庫的查詢可能需要搜索數百甚至數千行。
提高停電情況下的可靠性
數據庫中斷的發生有多種原因,包括意外數據刪除、連接錯誤和網絡安全攻擊。 分片可以最大限度地減少中斷的影響。 由於每個分片都是自治的,因此只有受影響的分片會面臨停機。 例如,如果您有四個分片並且其中一個分片出現中斷,則只有 25% 的操作會受到影響。
分片的缺點
雖然分片提高了數據庫的可靠性和可用性,但實現起來很複雜。 使用錯誤的分片架構會降低性能並導致數據丟失。
請務必選擇一種允許在所有分片之間平衡數據分佈的分片技術。 如果沒有這種平衡,您可能會創建數據庫熱點,當一個分片存儲大部分數據而其他分片實際上是空的時,就會發生這種情況。 這會降低單個分片的寫入吞吐量。
為了解決這個問題,您可以進一步對不平衡的分片進行分區,但該過程具有挑戰性,並且可能會在您遷移數據時關閉您的數據庫。
想知道我們是如何將流量提高到 1000% 以上的嗎?
加入 20,000 多人的行列,他們會通過 WordPress 內幕技巧獲得我們的每週時事通訊!

分片的另一個缺點是涉及不同分片中多個表的 SQL 連接可能會變得太慢並降低性能。 但是,使用正確的架構,您可以避免這個問題。
分片架構
您可以使用三種架構實現分片:
- 基於密鑰的分片
- 基於範圍的分片
- 基於目錄的分片
您選擇的架構取決於您的用例。
基於密鑰的分片
在基於鍵或散列的分片架構中,數據庫應用程序使用分片鍵來定位分片。 散列函數對分片鍵值進行散列,輸出將數據映射到特定分片。 一個簡單的散列函數可以是鍵的模數和分片的數量。
散列函數可以採用多個分片鍵。 因此,基於鍵的分片適用於可能具有共享鍵的數據記錄。 以算法方式分佈數據可最大限度地減少創建數據庫熱點的可能性,其中一個分片包含比另一個分片更多的數據。
但是,由於分佈僅依賴於散列函數,因此不可能在邏輯上將數據分組在一起。 因此,需要來自多個分片的數據的數據庫操作可能效率低下,因為它們需要從每個分片讀取數據。
基於範圍的分片
基於範圍的分片涉及根據指定的值範圍對數據庫進行分片。
它使用分片鍵來確定將值分配給哪個分片。 數據庫應用程序在查找表中檢查與分片鍵對應的分片並存儲數據。 正因為如此,基於範圍的分片很容易設計和實現。
例如,您可以使用用戶數據庫中的用戶 ID 值作為分片鍵。 您可以將 ID 介於 0 到 2,000 之間的用戶存儲在一個分片上,將 2,000 到 4,000 之間的用戶存儲在另一個分片上,依此類推。
基於範圍的分片會導致數據庫熱點。 考慮一個用戶數據庫,其中大部分用戶 ID 位於 2,001 到 4,000 之間。 該過程將它們分配給單個分片,隨著時間的推移產生不平衡。 因此,基於範圍的分片最適合均勻分佈的數據。
基於目錄的分片
基於目錄的分片將邏輯相關的數據分組在同一個分片中。 它使用一個查找表,其中包含數據庫中每個實體的映射列表。 每個映射對應一個數據庫分片。
基於目錄的分片比基於範圍或基於鍵的分片更靈活,因為您可以動態地將數據添加到分片。 沒有可遵循的分片功能或範圍內的值。 這種靈活性提高了數據庫效率:您可以將相關數據存儲在一個分片中,這意味著執行常見查詢需要更少的時間。
例如,如果您使用基於目錄的分片並根據用戶的位置對用戶進行分組,從特定位置檢索用戶,您只需查詢單個分片。
使用 Kinsta 進行數據庫分片
大多數現代數據庫引擎都提供數據庫分片支持。 其中一個數據庫引擎是 MariaDB,它是 MySQL 的商業支持分支。 它是 IBM、GitHub 和 Wikimedia 等公司採用的高性能開源數據庫系統。 它也是 Kinsta 高性能服務器堆棧的一部分。
MariaDB 通過蜘蛛存儲引擎提供內置的分片功能。 蜘蛛存儲引擎是支持分區和擴展架構 (XA) 事務的集群形成引擎。 它允許您將來自不同實例的遠程表視為在同一個實例中。 在蜘蛛存儲引擎中創建表後,該表將鏈接到遠程 MariaDB 服務器中的另一個表。 建立連接後,存儲引擎將與屬於同一事務的所有表共享該鏈接。
概括
數據庫分片是一種擴展技術,它將表劃分為更小的子集,並將它們分佈到稱為分片的不同服務器上。 您可以通過多種方式實現分片,例如基於鍵的分片、基於範圍的分片和基於目錄的分片。
雖然分片提高了數據庫的可擴展性、可靠性和可用性,但實現起來非常複雜。 此外,一旦創建了分片,將數據庫恢復到未分片狀態並不容易。 因此,僅當您確定其他可伸縮性選項不起作用時才使用分片進行優化。
無論您的企業是非營利組織還是企業級企業,Kinsta 的專家解決方案都可以消除您對網站託管的擔憂,讓您專注於最重要的事情。