
在創紀錄的時間內構建強大的 MongoDB 副本集(4 種方法)
已發表: 2023-03-11MongoDB 是一個 NoSQL 數據庫,它使用具有動態模式的類似 JSON 的文檔。 使用數據庫時,最好有一個應急計劃,以防其中一台數據庫服務器出現故障。 側邊欄,您可以通過為您的 WordPress 網站利用一個漂亮的管理工具來減少這種情況發生的可能性。
這就是擁有多個數據副本很有用的原因。 它還減少了讀取延遲。 同時,它可以提高數據庫的可擴展性和可用性。 這就是複制的用武之地。它被定義為跨多個數據庫同步數據的做法。
在本文中,我們將深入探討 MongoDB 複製的各個重要方面,例如其功能和機制等。
什麼是 MongoDB 中的複制?
在 MongoDB 中,副本集執行複制。 這是一組通過複製維護相同數據集的服務器。 您甚至可以將 MongoDB 複製用作負載平衡的一部分。 在這裡,您可以根據用例在所有實例之間分配寫入和讀取操作。
什麼是 MongoDB 副本集?
屬於給定副本集的每個 MongoDB 實例都是成員。 每個副本集都需要有一個主要成員和至少一個次要成員。
主要成員是與副本集進行交易的主要訪問點。 它也是唯一可以接受寫操作的成員。 複製首先複製主要的 oplog(操作日誌)。 接下來,它會在輔助節點各自的數據集上重複記錄的更改。 因此,每個副本集一次只能有一個主要成員。 各種primaries接收寫操作會造成數據衝突。
通常,應用程序只查詢主要成員的寫入和讀取操作。 您可以將設置設計為從一個或多個次要成員讀取。 異步數據傳輸可能導致輔助節點的讀取服務於舊數據。 因此,這樣的安排並不適合所有用例。
副本集特徵
自動故障轉移機制使 MongoDB 的副本集在競爭中脫穎而出。 在沒有主節點的情況下,輔助節點之間的自動選舉會選擇一個新的主節點。
MongoDB 副本集與 MongoDB 集群
MongoDB 副本集將跨副本集節點創建同一數據集的多個副本。 副本集的主要目的是:
- 提供內置備份解決方案
- 提高數據可用性
MongoDB 集群是完全不同的球類游戲。 它通過分片鍵將數據分佈在許多節點上。 這個過程會將數據分成許多塊,稱為分片。 接下來,它將每個分片複製到不同的節點。 集群旨在支持大型數據集和高吞吐量操作。 它通過水平擴展工作負載來實現。
用外行的話來說,這是副本集和集群之間的區別:
- 集群分配工作負載。 它還在許多服務器上存儲數據片段(分片)。
- 副本集完全複製數據集。
MongoDB 允許您通過創建分片集群來組合這些功能。 在這裡,您可以將每個分片複製到輔助服務器。 這允許分片提供高冗餘和數據可用性。
維護和設置副本集在技術上可能既費力又耗時。 並找到合適的託管服務? 那是另一個令人頭疼的問題。 有這麼多選擇,很容易浪費時間進行研究,而不是建立您的業務。
讓我向您簡要介紹一個工具,該工具可以完成所有這一切以及更多工作,以便您可以回過頭來用您的服務/產品來粉碎它。
Kinsta 的應用程序託管解決方案受到超過 55,000 名開發人員的信任,您只需 3 個簡單的步驟即可啟動並運行它。 如果這聽起來好得令人難以置信,那麼這裡有一些使用 Kinsta 的更多好處:
- 通過 Kinsta 的內部連接享受更好的性能:忘記與共享數據庫的鬥爭。 切換到具有沒有查詢計數或行計數限制的內部連接的專用數據庫。 Kinsta 更快、更安全,並且不會向您收取內部帶寬/流量費用。
- 為開發人員量身定制的功能集:在支持 Gmail、YouTube 和 Google 搜索的強大平台上擴展您的應用程序。 放心,你在這裡是最安全的。
- 通過您選擇的數據中心享受無與倫比的速度:選擇最適合您和您的客戶的區域。 Kinsta 的275 多個PoP 有超過 25 個數據中心可供選擇,可確保您網站的最高速度和全球影響力。
立即免費試用 Kinsta 的應用程序託管解決方案!
複製在 MongoDB 中是如何工作的?
在 MongoDB 中,您將寫入器操作發送到主服務器(節點)。 主要分配跨輔助服務器的操作,複製數據。
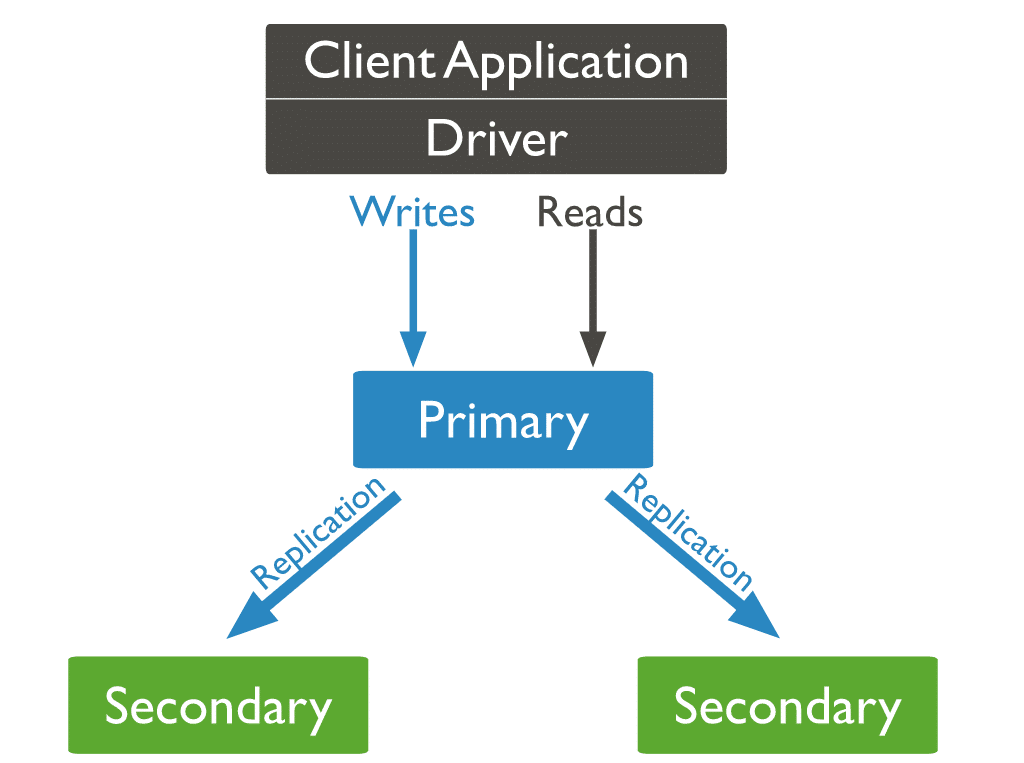
三種類型的 MongoDB 節點
在三種類型的 MongoDB 節點中,有兩種以前出現過:主節點和輔助節點。 在復製過程中派上用場的第三種 MongoDB 節點是仲裁器。 仲裁節點沒有數據集的副本,不能成為主節點。 話雖如此,仲裁者確實參與了初選的選舉。
我們之前提到過當主節點宕機時會發生什麼,但是如果從節點掛掉了怎麼辦? 在那種情況下,主節點變為輔助節點並且數據庫變得不可訪問。
會員選舉
選舉可以在以下情況下發生:
- 初始化副本集
- 失去與主節點的連接(可以通過心跳檢測到)
- 使用
rs.reconfig或stepDown方法維護副本集 - 將新節點添加到現有副本集
一個副本集最多可以擁有 50 個成員,但只有 7 個或更少的成員可以在任何選舉中投票。
集群選舉新主節點之前的平均時間不應超過 12 秒。 選舉算法將嘗試讓具有最高優先級的次要可用。 同時,優先級值為0的成員不能成為初選成員,不參與選舉。
寫關注
為了持久性,寫操作有一個框架來複製指定數量的節點中的數據。 您甚至可以通過此向客戶提供反饋。 這個框架也被稱為“寫關注”。 它具有數據承載成員,需要在操作成功返回之前確認寫入問題。 通常,副本集的值為 1 作為寫入關注點。 因此,只有主節點應該在返回寫入關注確認之前確認寫入。
您甚至可以增加確認寫入操作所需的成員數量。 您可以擁有的成員數量沒有上限。 但是,如果數字很高,則需要處理高延遲。 這是因為客戶端需要等待所有成員的確認。 此外,您可以設置“多數”的寫入關注。這將在收到確認後計算超過一半的成員。
閱讀偏好
對於讀取操作,您可以提及描述數據庫如何將查詢定向到副本集成員的讀取首選項。 通常,主節點接收讀取操作,但客戶端可以提及讀取偏好以將讀取操作發送到輔助節點。 以下是閱讀首選項的選項:
- primaryPreferred :通常,讀取操作來自主節點,但如果這不可用,則從輔助節點提取數據。
- primary :所有讀操作都來自主節點。
- secondary :所有讀操作都由從節點執行。
- nearest :在這裡,讀取請求被路由到最近的可達節點,可以通過運行
ping命令檢測到。 讀取操作的結果可以來自副本集的任何成員,無論它是主要的還是次要的。 - secondaryPreferred :這里大部分的讀操作都來自secondary節點,但是如果沒有secondary節點,則從primary節點取數據。
複製集數據同步
為了維護共享數據集的最新副本,副本集的次要成員從其他成員複製或同步數據。
MongoDB 利用兩種形式的數據同步。 初始同步以使用完整數據集填充新成員。 複製以執行對完整數據集的持續更改。
初始同步
初始同步時,從節點運行init sync命令將主節點的所有數據同步到另一個包含最新數據的從節點。 因此,輔助節點始終利用tailable cursor功能來查詢主節點的 local.oplog.rs 集合中的最新 oplog 條目,並在這些 oplog 條目中應用這些操作。
從 MongoDB 5.2 開始,初始同步可以是基於文件副本的或邏輯的。
邏輯同步
當您執行邏輯同步時,MongoDB:
- 在為每個集合複製文檔時開發所有集合索引。
- 複製除本地數據庫之外的所有數據庫。
mongod掃描所有源數據庫中的每個集合,並將所有數據插入到這些集合的副本中。 - 對數據集執行所有更改。 通過利用來自源的 oplog,
mongod升級其數據集以描述副本集的當前狀態。 - 在數據複製過程中提取新添加的 oplog 記錄。 確保目標成員在本地數據庫中有足夠的磁盤空間,以便在此數據複製階段期間暫時存儲這些 oplog 記錄。
初始同步完成後,成員從STARTUP2過渡到SECONDARY 。
基於文件副本的初始同步
馬上,您只能在使用 MongoDB Enterprise 時執行此操作。 此過程通過複製和移動文件系統上的文件來運行初始同步。 在某些情況下,此同步方法可能比邏輯初始同步更快。 請記住,如果您在沒有查詢謂詞的情況下運行 count() 方法,基於文件副本的初始同步可能會導致計數不准確。
但是,這種方法也有其局限性:
- 在基於文件副本的初始同步期間,您無法寫入正在同步的成員的本地數據庫。 您也不能對同步到的成員或同步自的成員運行備份。
- 在利用加密存儲引擎時,MongoDB 使用源密鑰來加密目標。
- 您一次只能從一個給定的成員運行初始同步。
複製
次要成員在初始同步後一致地複制數據。 次要成員將從源同步中復制操作日誌,並在異步過程中執行這些操作。
輔助節點能夠根據 ping 時間和其他成員複製狀態的變化,根據需要自動修改來自源的同步。
流複製
從 MongoDB 4.4 開始,來自源的同步將連續的 oplog 條目流發送到它們的同步輔助節點。 流式複制減少了高負載和高延遲網絡中的複制滯後。 它還可以:
- 降低由於主要故障轉移而丟失
w:1寫入操作的風險。 - 減少從輔助節點讀取的陳舊性。
- 使用
w:“majority”和w:>1減少寫操作的延遲。 簡而言之,任何需要等待複製的寫關注點。
多線程複製
MongoDB曾經通過多線程批量寫入操作來提高並發性。 MongoDB 按文檔 ID 對批次進行分組,同時使用不同的線程應用每組操作。
MongoDB 始終以其原始寫入順序對給定文檔執行寫入操作。 這在 MongoDB 4.0 中發生了變化。
從 MongoDB 4.0 開始,如果讀取發生在應用複制批處理的輔助節點上,則針對輔助節點並配置了“majority”或“local”讀取關注級別的讀取操作現在將從數據的 WiredTiger 快照中讀取。 從快照讀取保證了數據的一致視圖,並讓讀取與正在進行的複制同時發生而無需鎖定。
因此,需要這些讀取關注級別的輔助讀取不再需要等待應用複制批次,並且可以在接收到它們時進行處理。
如何創建 MongoDB 副本集
如前所述,MongoDB 通過副本集處理複製。 在接下來的幾節中,我們將重點介紹一些可用於為您的用例創建副本集的方法。
方法一:在 Ubuntu 上創建一個新的 MongoDB 副本集
在開始之前,您需要確保至少有三台運行 Ubuntu 20.04 的服務器,每台服務器上都安裝了 MongoDB。
要設置副本集,必須提供一個地址,該地址中的每個副本集成員都可以訪問該地址。 在這種情況下,我們在集合中保留三個成員。 雖然我們可以使用 IP 地址,但不建議這樣做,因為地址可能會意外更改。 更好的替代方法是在配置副本集時使用邏輯 DNS 主機名。
我們可以通過為每個複製成員配置子域來做到這一點。 雖然這對於生產環境來說可能是理想的,但本節將概述如何通過編輯每個服務器各自的主機文件來配置 DNS 解析。 該文件允許我們將可讀的主機名分配給數字 IP 地址。 因此,如果您的 IP 地址在任何情況下發生變化,您所要做的就是更新三台服務器上的主機文件,而不是從頭開始重新配置副本集!
大多數情況下, hosts存儲在/etc/目錄中。 對三個服務器中的每一個重複以下命令:
sudo nano /etc/hosts在上面的命令中,我們使用 nano 作為我們的文本編輯器,但是,您可以使用您喜歡的任何文本編輯器。 在配置本地主機的前幾行之後,為副本集的每個成員添加一個條目。 這些條目採用 IP 地址後跟您選擇的人類可讀名稱的形式。 雖然您可以隨心所欲地命名它們,但一定要具有描述性,這樣您才能區分每個成員。 對於本教程,我們將使用以下主機名:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
使用這些主機名,您的 /etc/hosts 文件將類似於以下突出顯示的行:

保存並關閉文件。
為副本集配置好DNS解析後,我們需要更新防火牆規則,讓它們可以互相通信。 在 mongo0 上運行以下ufw命令以提供 mongo1 對 mongo0 上端口 27017 的訪問:
sudo ufw allow from mongo1_server_ip to any port 27017 代替mongo1_server_ip參數,輸入您的 mongo1 服務器的實際 IP 地址。 此外,如果您已將此服務器上的 Mongo 實例更新為使用非默認端口,請務必更改 27017 以反映您的 MongoDB 實例正在使用的端口。
現在添加另一個防火牆規則以授予 mongo2 對同一端口的訪問權限:
sudo ufw allow from mongo2_server_ip to any port 27017 代替mongo2_server_ip參數,輸入您的 mongo2 服務器的實際 IP 地址。 然後,更新其他兩台服務器的防火牆規則。 在 mongo1 服務器上運行以下命令,確保更改 IP 地址代替 server_ip 參數以分別反映 mongo0 和 mongo2 的 IP 地址:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017最後,在 mongo2 上運行這兩個命令。 同樣,請確保為每台服務器輸入正確的 IP 地址:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017下一步是更新每個 MongoDB 實例的配置文件以允許外部連接。 為此,您需要修改每個服務器中的配置文件以反映 IP 地址並指示副本集。 雖然您可以使用任何首選的文本編輯器,但我們再次使用 nano 文本編輯器。 讓我們在每個 mongod.conf 文件中進行以下修改。
在 mongo0 上:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"在 mongo1 上:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"在 mongo2 上:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongod這樣,您就為每個服務器的 MongoDB 實例啟用了複製。
您現在可以使用rs.initiate()方法初始化副本集。 該方法只需要在副本集中的單個 MongoDB 實例上執行。 確保副本集名稱和成員與您之前在每個配置文件中所做的配置相匹配。
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })如果該方法在輸出中返回“ok”: 1,則表示副本集已正確啟動。 下面是輸出應該是什麼樣子的示例:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }關閉 MongoDB 服務器
您可以使用db.shutdownServer()方法關閉 MongoDB 服務器。 下面是相同的語法。 force和timeoutsecs都是可選參數。
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) 如果 mongod 副本集成員運行某些操作作為索引構建,則此方法可能會失敗。 要中斷操作並強制關閉成員,您可以輸入布爾參數force為 true。
使用 –replSet 重啟 MongoDB
要重置配置,請確保副本集中的每個節點都已停止。 然後刪除每個節點的本地數據庫。 使用–replSet標誌再次啟動它,並僅在副本集的一個 mongod 實例上運行rs.initiate() 。
mongod --replSet "rs0" rs.initiate()可以帶一個可選的副本集配置文件,即:
-
Replication.replSetName或—replSet選項用於在_id字段中指定副本集名稱。 - 成員數組,其中包含每個副本集成員的一個文檔。
rs.initiate()方法觸發選舉並選出其中一個成員作為主要成員。
將成員添加到副本集
要將成員添加到集合中,請在各種機器上啟動 mongod 實例。 接下來,啟動一個 mongo 客戶端並使用rs.add()命令。
rs.add()命令具有以下基本語法:
rs.add(HOST_NAME:PORT)例如,
假設 mongo1 是您的 mongod 實例,它正在偵聽端口 27017。使用 Mongo 客戶端命令rs.add()將此實例添加到副本集。
rs.add("mongo1:27017") 只有連接到主節點後,才能將 mongod 實例添加到副本集。 要驗證您是否已連接到主服務器,請使用命令db.isMaster() 。
刪除用戶
要刪除成員,我們可以使用rs.remove()
為此,首先,使用我們上面討論的db.shutdownServer()方法關閉您希望刪除的 mongod 實例。
接下來,連接到副本集的當前主節點。 要確定當前主節點,請在連接到副本集的任何成員時使用db.hello() 。 確定主節點後,運行以下任一命令:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 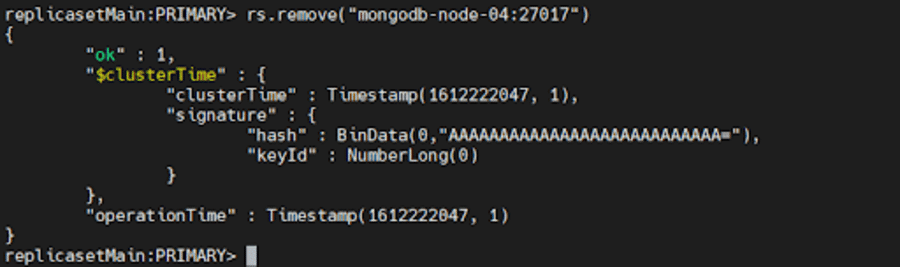
如果副本集需要選舉一個新的主節點,MongoDB 可能會短暫地斷開 shell。 在這種情況下,它會再次自動重新連接。 此外,即使命令成功,它也可能顯示DBClientCursor::init call() failed 錯誤。
方式二:配置MongoDB副本集部署測試
通常,您可以設置副本集以在啟用或禁用 RBAC 的情況下進行測試。 在這種方法中,我們將設置副本集並禁用訪問控制,以便將其部署在測試環境中。

首先,使用以下命令為屬於副本集的所有實例創建目錄:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2此命令將為三個 MongoDB 實例 replicaset0-0、replicaset0-1 和 replicaset0-2 創建目錄。 現在,使用以下一組命令為它們中的每一個啟動 MongoDB 實例:
對於服務器 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128對於服務器 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128對於服務器 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 –oplogSize參數用於防止機器在測試階段過載。 它有助於減少每個磁盤佔用的磁盤空間量。
現在,使用下面的端口號連接到使用 Mongo shell 的實例之一。
mongo --port 27017 我們可以使用rs.initiate()命令啟動複製過程。 您必須將hostname參數替換為您的系統名稱。
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }您現在可以將配置對象文件作為啟動命令的參數傳遞,並按如下方式使用它:
rs.initiate(rsconf)你有它! 您已成功創建用於開發和測試目的的 MongoDB 副本集。
方法 3:將獨立實例轉換為 MongoDB 副本集
MongoDB 允許其用戶將其獨立實例轉換為副本集。 雖然獨立實例主要用於測試和開發階段,但副本集是生產環境的一部分。
首先,讓我們使用以下命令關閉我們的 mongod 實例:
db.adminCommand({"shutdown":"1"}) 通過在命令中使用–repelSet參數來重新啟動您的實例,以指定您將要使用的副本集:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>您必須在命令中指定服務器名稱和唯一地址。
將 shell 與您的 MongoDB 實例連接起來,並使用 initiate 命令啟動複製過程並成功地將實例轉換為副本集。 您可以使用以下命令執行所有基本操作,例如添加或刪除實例:
rs.add(“<host_name:port>”) rs.remove(“host-name”) 此外,您可以使用rs.status()和rs.conf()命令檢查 MongoDB 副本集的狀態。
方法 4:MongoDB Atlas——更簡單的替代方法
複製和分片可以一起工作以形成稱為分片集群的東西。 雖然設置和配置雖然簡單但可能非常耗時,但 MongoDB Atlas 是比前面提到的方法更好的替代方法。
它使您的副本集自動化,使該過程易於實施。 只需點擊幾下,即可部署全局分片副本集,實現容災、易管理、數據本地化、多區域部署。
在 MongoDB Atlas 中,我們需要創建集群——它們可以是副本集,也可以是分片集群。 對於一個特定的項目,其他地區的一個集群中的節點數量限制為總共 40 個。
這不包括免費或共享集群以及相互通信的 Google 雲區域。 任意兩個區域之間的節點總數必須滿足此約束。 例如,如果有一個項目:
- 區域 A 有 15 個節點。
- 區域 B 有 25 個節點
- 區域 C 有 10 個節點
我們只能再分配 5 個節點到區域 C,因為,
- A區+B區=40; 滿足 40 作為允許的最大節點數的約束。
- 區域B+區域C = 25+10+5(分配給C的額外節點)= 40; 滿足 40 作為允許的最大節點數的約束。
- 區域A+區域C=15+10+5(額外分配給C的節點)=30; 滿足 40 作為允許的最大節點數的約束。
如果我們再分配 10 個節點到區域 C,使區域 C 有 20 個節點,那麼區域 B + 區域 C = 45 個節點。 這會超出給定的限制,因此您可能無法創建多區域集群。
當您創建集群時,Atlas 會在項目中為雲提供商創建一個網絡容器(如果之前不存在的話)。 要在 MongoDB Atlas 中創建副本集集群,請在 Atlas CLI 中運行以下命令:
atlas clusters create [name] [options]確保提供一個描述性的集群名稱,因為它在集群創建後無法更改。 參數可以包含 ASCII 字母、數字和連字符。
根據您的要求,有多個選項可用於在 MongoDB 中創建集群。 例如,如果您想要為您的集群進行連續的雲備份,請將--backup設置為 true。
處理複製延遲
複製延遲可能非常令人不快。 這是主節點上的操作與該操作從 oplog 應用到輔助節點之間的延遲。 如果您的業務處理大型數據集,則預計會在某個閾值內出現延遲。 但是,有時外部因素也可能導致延遲增加。 要從最新的複制中獲益,請確保:
- 您在穩定且足夠的帶寬中路由網絡流量。 網絡延遲在影響您的複制方面起著巨大的作用,如果網絡不足以滿足複製過程的需要,則在復制整個副本集中的數據時會出現延遲。
- 您有足夠的磁盤吞吐量。 如果輔助設備上的文件系統和磁盤設備無法像主設備一樣快速地將數據刷新到磁盤,那麼輔助設備將難以跟上。 因此,輔助節點處理寫查詢的速度比主節點慢。 這是大多數多租戶系統中的常見問題,包括虛擬化實例和大規模部署。
- 您在一段時間後請求寫確認寫入關注,以便為輔助節點提供趕上主節點的機會,尤其是當您要執行需要對主節點進行大量寫入的批量加載操作或數據攝取時。 輔助節點將無法足夠快地讀取操作日誌以跟上更改; 特別是對於未確認的寫入問題。
- 您確定正在運行的後台任務。 某些任務(如 cron 作業、服務器更新和安全檢查)可能會對網絡或磁盤使用產生意外影響,從而導致複製過程延遲。
如果您不確定您的應用程序中是否存在復制滯後,請不要擔心——下一節將討論故障排除策略!
MongoDB 副本集故障排除
您已經成功設置了副本集,但您注意到您的數據在服務器之間不一致。 這對於大型企業來說是非常令人擔憂的,但是,通過快速的故障排除方法,您可能會找到原因甚至糾正問題! 下面給出了一些可能派上用場的副本集部署故障排除的常見策略:
檢查副本狀態
我們可以通過在連接到副本集主節點的 mongosh 會話中運行以下命令來檢查副本集的當前狀態和每個成員的狀態。
rs.status()檢查復制延遲
如前所述,複製滯後可能是一個嚴重的問題,因為它使“滯後”成員沒有資格快速成為主要成員,並增加了分佈式讀取操作不一致的可能性。 我們可以使用以下命令檢查復制日誌的當前長度:
rs.printSecondaryReplicationInfo() 這將返回syncedTo值,該值是每個成員的最後一個 oplog 條目寫入輔助節點的時間。 這是一個演示相同內容的示例:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary 當主要成員的不活動時間大於members[n].secondaryDelaySecs值時,延遲成員可能會顯示為落後主要成員 0 秒。
測試所有成員之間的連接
副本集的每個成員都必須能夠與其他每個成員連接。 始終確保驗證兩個方向的連接。 大多數情況下,防火牆配置或網絡拓撲會阻止正常和所需的連接,從而阻止複制。
例如,假設 mongod 實例綁定到本地主機和與 IP 地址 198.41.110.1 關聯的主機名“ExampleHostname”:
mongod --bind_ip localhost, ExampleHostname要連接到此實例,遠程客戶端必須指定主機名或 IP 地址:
mongosh --host ExampleHostname mongosh --host 198.41.110.1如果一個副本集由 m1、m2 和 m3 三個成員組成,使用默認端口 27017,您應該按如下方式測試連接:
在 m1 上:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017在 m2 上:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017在 m3 上:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 如果任何方向的任何連接失敗,您必須檢查您的防火牆配置並重新配置它以允許連接。
使用密鑰文件身份驗證確保安全通信
默認情況下,MongoDB 中的密鑰文件身份驗證依賴於加鹽挑戰響應身份驗證機制 (SCRAM)。 為此,MongoDB 必須讀取並驗證用戶提供的憑據,其中包括特定 MongoDB 實例知道的用戶名、密碼和身份驗證數據庫的組合。 這是用於對連接到數據庫時提供密碼的用戶進行身份驗證的確切機制。
當您在 MongoDB 中啟用身份驗證時,將自動為副本集啟用基於角色的訪問控制 (RBAC),並且用戶被授予一個或多個角色,這些角色決定了他們對數據庫資源的訪問權限。 當啟用 RBAC 時,這意味著只有經過身份驗證且具有適當權限的有效 Mongo 用戶才能訪問系統上的資源。
密鑰文件就像集群中每個成員的共享密碼。 這使得副本集中的每個 mongod 實例都可以使用密鑰文件的內容作為共享密碼來驗證部署中的其他成員。
只有具有正確密鑰文件的 mongod 實例才能加入副本集。 密鑰的長度必須介於 6 到 1024 個字符之間,並且只能包含 base64 集中的字符。 請注意,MongoDB 在讀取鍵時會去除空白字符。
您可以使用多種方法生成密鑰文件。 在本教程中,我們使用openssl生成一個由 1024 個隨機字符組成的複雜字符串,用作共享密碼。 然後它使用chmod更改文件權限以僅向文件所有者提供讀取權限。 避免將密鑰文件存儲在可以輕鬆與託管 mongod 實例的硬件斷開連接的存儲介質上,例如 USB 驅動器或網絡附加存儲設備。 下面是生成密鑰文件的命令:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. 例如:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )出現提示時輸入密碼。
If you wish to, you may create additional users to allow clients and interact with the replica set.
瞧! You have successfully enabled keyfile authentication!
概括
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!