
Robots.txt:它是什麼以及如何創建它(完整指南)
已發表: 2023-05-05如果您擁有一個網站或管理其內容,您可能聽說過 robots.txt。 它是一個文件,指示搜索引擎機器人如何抓取和索引您的網站頁面。 儘管它在搜索引擎優化 (SEO) 中很重要,但許多網站所有者忽視了精心設計的 robots.txt 文件的重要性。
在本完整指南中,我們將探討什麼是 robots.txt、為什麼它對 SEO 很重要,以及如何為您的網站創建 robots.txt 文件。
什麼是 Robots.txt 文件?
robots.txt 是一個文件,它告訴搜索引擎機器人(也稱為爬蟲或蜘蛛)應該抓取或不抓取網站的哪些頁面或部分。 它是位於網站根目錄中的純文本文件,通常包含網站管理員希望阻止搜索引擎索引或抓取的目錄、文件或 URL 的列表。
這是 robots.txt 文件的樣子:

為什麼 Robots.txt 很重要?
robots.txt 對您的網站很重要的三個主要原因:
1.最大化抓取預算
“抓取預算”代表 Google 在任何給定時間將在您的網站上抓取的頁面數量。 數量取決於您網站上反向鏈接的大小、健康狀況和數量。
抓取預算很重要,因為如果您網站上的頁面數量超過抓取預算,您將擁有未編入索引的頁面。
此外,未編入索引的頁面將不會獲得任何排名。
通過使用 robots.txt 來阻止無用的頁面,Googlebot(Google 的網絡抓取工具)可能會將您的更多抓取預算花在重要的頁面上。
2. 屏蔽非公開頁面
您的網站上有許多您不想編入索引的頁面。
例如,您可能有一個內部搜索結果頁面或登錄頁面。 這些頁面需要存在。 但是,您不希望隨機的人落在他們身上。
在這種情況下,您將使用 robots.txt 來防止搜索引擎抓取工具和機器人訪問某些頁面。
3.防止資源索引
有時您會希望 Google 從搜索結果中排除 PDF、視頻和圖像等資源。
可能您希望將這些資源保密,或者您希望 Google 更專注於重要內容。
在這種情況下,使用 robots.txt 是防止它們被編入索引的最佳方法。
Robots.txt 文件如何工作?
Robots.txt 文件指示搜索引擎機器人應該或不應該抓取或索引網站的哪些頁面或目錄。
在爬行時,搜索引擎機器人會查找並跟踪鏈接。 這個過程通過數十億個鏈接和網站引導他們從站點 X 到站點 Y 再到站點 Z。
當機器人訪問站點時,它做的第一件事就是查找 robots.txt 文件。
如果它檢測到一個,它將在執行任何其他操作之前讀取該文件。
例如,假設您希望允許除 DuckDuckGo 之外的所有機器人抓取您的網站:
User-agent: DuckDuckBot Disallow: /
注意: robots.txt 文件只能給出指令; 它不能強加於人。 它類似於行為準則。 好的機器人(例如搜索引擎機器人)會遵守規則,而壞的機器人(例如垃圾郵件機器人)會忽略它們。
如何查找 Robots.txt 文件?
robots.txt 文件與您網站上的任何其他文件一樣,託管在您的服務器上。
任何網站的robots.txt文件都可以通過輸入完整的首頁網址,然後在末尾加上/robots.txt來訪問,比如https://pickupwp.com/robots.txt。
但是,如果該網站沒有 robots.txt 文件,您將收到“404 Not Found”錯誤消息。
如何創建 Robots.txt 文件?
在展示如何創建 robots.txt 文件之前,讓我們先看看 robots.txt 語法。
robots.txt 文件的語法可以分解為以下部分:
- 用戶代理:這指定記錄適用的機器人或爬蟲。 例如,“User-agent: Googlebot”僅適用於 Google 的搜索爬蟲,而“User-agent: *”適用於所有爬蟲。
- Disallow:這指定機器人不應抓取的頁面或目錄。 例如,“Disallow: /private/”將阻止機器人抓取“private”目錄中的任何頁面。
- 允許:指定應允許機器人抓取的頁面或目錄,即使父目錄是不允許的。 例如,“允許:/public/”將允許機器人抓取“public”目錄中的任何頁面,即使父目錄是不允許的。
- 抓取延遲:指定機器人在抓取網站之前應等待的時間(以秒為單位)。 例如,“Crawl-delay: 10”會指示機器人在抓取網站之前等待 10 秒。
- 站點地圖:這指定了網站站點地圖的位置。 例如,“站點地圖:https://www.example.com/sitemap.xml”會告知機器人網站站點地圖的位置。
以下是 robots.txt 文件的示例:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
注意:請務必注意,robots.txt 文件區分大小寫,因此在指定 URL 時使用正確的大小寫非常重要。
例如,/public/ 與 /Public/ 不同。
另一方面,像“Allow”和“Disallow”這樣的指令不區分大小寫,因此是否大寫取決於您。
了解 robots.txt 語法後,您可以使用 robots.txt 生成器工具創建 robots.txt 文件或自己創建一個。
以下是如何通過四個步驟創建 robots.txt 文件:
1.新建一個文件,命名為robots.txt
只需使用任何文本編輯器或 Web 瀏覽器打開 .txt 文檔。
接下來,將文檔命名為 robots.txt。 要工作,它必須命名為 robots.txt。
完成後,您現在可以開始輸入指令。
2. 將指令添加到 Robots.txt 文件
robots.txt 文件包含一組或多組指令,每組指令包含多行指令。
每個組都以“用戶代理”開頭,並包含以下數據:
- 該組適用於誰(用戶代理)
- 代理可以訪問哪些目錄(頁面)或文件?
- 代理不能訪問哪些目錄(頁面)或文件?
- 站點地圖(可選),用於通知搜索引擎您認為重要的站點和文件。
不匹配任何這些指令的行將被爬蟲忽略。
例如,您想阻止 Google 抓取您的 /private/ 目錄。
它看起來像這樣:
User-agent: Googlebot Disallow: /private/

如果您有針對 Google 的進一步說明,請將它們放在下面的單獨一行中,如下所示:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
此外,如果您完成了 Google 的特定說明並想要創建一組新的指令。
例如,如果您想阻止所有搜索引擎抓取您的 /archive/ 和 /support/ 目錄。
它看起來像這樣:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
完成後,您可以添加站點地圖。
您完成的 robots.txt 文件應如下所示:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
接下來,保存您的 robots.txt 文件。 請記住,它必須命名為 robots.txt。
有關更多有用的 robots.txt 規則,請查看來自 Google 的有用指南。
3.上傳robots.txt文件
將 robots.txt 文件保存到您的計算機後,將其上傳到您的網站,供搜索引擎抓取。
不幸的是,沒有工具可以幫助完成此步驟。
robots.txt 文件的上傳取決於您網站的文件結構和虛擬主機。
有關如何上傳 robots.txt 文件的說明,請在線搜索或聯繫您的託管服務提供商。
4. 測試你的 Robots.txt
上傳 robots.txt 文件後,接下來您可以檢查是否有人可以看到它以及 Google 是否可以閱讀它。
只需在瀏覽器中打開一個新選項卡並蒐索您的 robots.txt 文件。
例如,https://pickupwp.com/robots.txt。
如果您看到 robots.txt 文件,則您已準備好測試標記(HTML 代碼)。
為此,您可以使用 Google robots.txt 測試器。
注意:您已設置 Search Console 帳戶以使用 robots.txt 測試器測試您的 robots.txt 文件。
robots.txt 測試器會發現任何語法警告或邏輯錯誤並突出顯示它們。
另外,它還在編輯器下方顯示警告和錯誤。
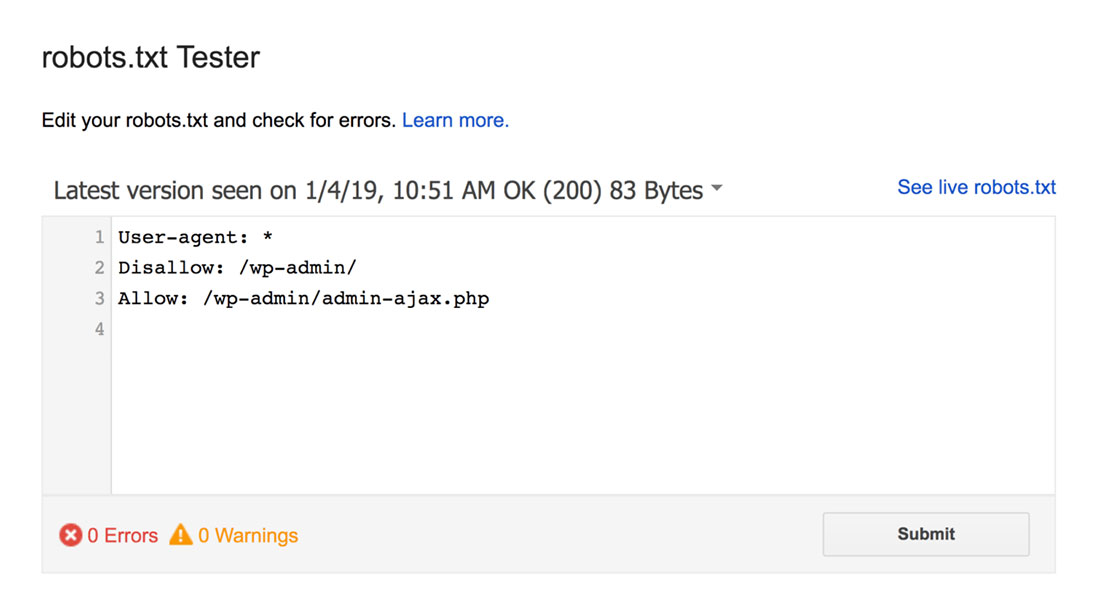
您可以在頁面上編輯錯誤或警告,並根據需要經常重新測試。
請記住,在頁面上所做的更改不會保存到您的網站。
要進行任何更改,請將其複制並粘貼到您網站的 robots.txt 文件中。
Robots.txt 最佳實踐
在創建 robots.txt 文件時請牢記這些最佳做法,以避免一些常見錯誤。
1. 為每個指令使用新行
為防止搜索引擎抓取工具混淆,請將每個指令添加到 robots.txt 文件中的新行。 這適用於 Allow 和 Disallow 規則。
例如,如果您不希望網絡爬蟲爬取您的博客或聯繫頁面,請添加以下規則:
Disallow: /blog/ Disallow: /contact/
2.每個用戶代理只使用一次
如果您反複使用相同的用戶代理,機器人不會有任何問題。
但是,只使用一次可以使事情井井有條並減少人為錯誤的機會。
3.使用通配符簡化指令
如果您要阻止大量頁面,為每個頁面添加一條規則可能會很耗時。 幸運的是,您可以使用通配符來簡化指令。
通配符是可以代表一個或多個字符的字符。 最常用的通配符是星號 (*)。
例如,如果您想阻止所有以 .jpg 結尾的文件,您可以添加以下規則:
Disallow: /*.jpg
4.使用“$”指定URL的結尾
美元符號 ($) 是另一個可用於標識 URL 結尾的通配符。 如果您想限制特定頁面而不是其後的頁面,這將很有用。
假設您想屏蔽聯繫頁面而不是聯繫成功頁面,您可以添加以下規則:
Disallow: /contact$
5. 使用井號 (#) 添加評論
爬蟲會忽略以井號 (#) 開頭的所有內容。
因此,開發人員經常使用哈希向 robots.txt 文件添加註釋。 它使文檔井井有條且可讀。
例如,如果你想阻止所有以 .jpg 結尾的文件,你可以添加以下註釋:
# Block all files that end in .jpg Disallow: /*.jpg
這有助於任何人了解該規則的用途及其存在的原因。
6. 為每個子域使用單獨的 Robots.txt 文件
如果您的網站有多個子域,建議為每個子域創建一個單獨的 robots.txt 文件。 這樣可以使事情井井有條,並幫助搜索引擎爬蟲更輕鬆地掌握您的規則。
包起來!
robots.txt 文件是一個有用的 SEO 工具,因為它指示搜索引擎機器人將哪些內容編入索引,哪些不編入索引。
但是,謹慎使用它很重要。 由於配置錯誤會導致您的網站完全取消索引(例如,使用 Disallow: /)。
通常,好的方法是允許搜索引擎盡可能多地掃描您的網站,同時保留敏感信息並避免重複內容。 例如,您可以使用 Disallow 指令來阻止特定頁面或目錄,或者使用 Allow 指令來覆蓋特定頁面的 Disallow 規則。
還值得一提的是,並非所有機器人都遵循 robots.txt 文件中提供的規則,因此它不是控制索引內容的完美方法。 但它仍然是您的 SEO 策略中的一個有價值的工具。
我們希望本指南能幫助您了解什麼是 robots.txt 文件以及如何創建它。
有關更多信息,您可以查看這些其他有用的資源:
- 給新博主的 15 個可行的博客技巧
- 釋放長尾關鍵詞的力量(新手指南)
最後,在 Twitter 上關注我們,定期更新新文章。