
WordPress robots.txt 文件……它是什麼以及它的作用
已發表: 2020-11-25你有沒有想過 robots.txt 文件是什麼以及它的作用? Robots.txt 用於與 Google 和其他搜索引擎使用的網絡爬蟲(稱為機器人)進行通信。 它告訴他們要索引您網站的哪些部分以及忽略哪些部分。 因此,robots.txt 文件可以幫助(或可能破壞!)您的 SEO 工作。 如果您希望您的網站排名良好,那麼對 robots.txt 的良好理解至關重要!
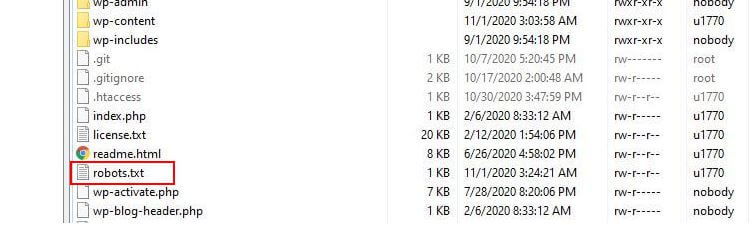
Robots.txt 位於何處?
WordPress 通常運行一個所謂的“虛擬”robots.txt 文件,這意味著它不能通過 SFTP 訪問。 但是,您可以訪問 yourdomain.com/robots.txt 查看其基本內容。 你可能會看到這樣的東西:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php第一行指定規則將應用於哪些機器人。 在我們的示例中,星號表示規則將應用於所有機器人(例如來自 Google、Bing 等的機器人)。
第二行定義了阻止機器人訪問 /wp-admin 文件夾的規則,第三行聲明允許機器人解析 /wp-admin/admin-ajax.php 文件。
添加您自己的規則
對於一個簡單的 WordPress 網站,WordPress 應用於 robots.txt 文件的默認規則可能綽綽有餘。 但是,如果您想要更多控制權並能夠添加自己的規則,以便向搜索引擎機器人提供有關如何索引您的網站的更具體說明,那麼您將需要創建自己的物理 robots.txt 文件並將其放在根目錄下你的安裝目錄。
有幾個原因可能需要重新配置您的 robots.txt 文件並定義這些機器人將被允許抓取的確切內容。 一個關鍵原因是與機器人抓取您的網站所花費的時間有關。 谷歌(和其他)不允許機器人在每個網站上花費無限的時間......對於數以萬億計的頁面,他們必須採取更細緻的方法來處理他們的機器人將抓取的內容以及他們將忽略的內容,以試圖提取最有用的信息關於一個網站。

使用 Pressidium 託管您的網站
60 天退款保證
當您允許機器人抓取您網站上的所有頁面時,部分抓取時間會花在不重要甚至不相關的頁面上。 這使他們有更少的時間來處理您網站中更相關的區域。 通過禁止機器人訪問您網站的某些部分,您可以增加機器人從您網站最相關部分提取信息的時間(希望最終被索引)。 由於抓取速度更快,Google 更有可能重新訪問您的網站並保持他們對您網站的索引是最新的。 這意味著新的博客文章和其他新鮮內容可能會更快地被索引,這是個好消息。
編輯 Robots.txt 的示例
robots.txt 提供了足夠的自定義空間。 因此,我們提供了一系列規則示例,可用於指示機器人如何索引您的網站。
允許或禁止機器人
首先,讓我們看看如何限制特定的機器人。 為此,我們需要做的就是將星號 (*) 替換為我們要阻止的機器人用戶代理的名稱,例如“MSNBot”。 此處提供了已知用戶代理的完整列表。
User-agent: MSNBot Disallow: /在第二行添加破折號將限制機器人對所有目錄的訪問。
為了只允許一個機器人抓取我們的網站,我們將使用兩步過程。 首先,我們將這個機器人設置為例外,然後禁止所有這樣的機器人:
User-agent: Google Disallow: User-agent: * Disallow: /為了允許訪問所有內容的所有機器人,我們添加了這兩行:
User-agent: * Disallow:只需創建一個 robots.txt 文件然後將其留空即可實現相同的效果。
阻止對特定文件的訪問
想要阻止機器人索引您網站上的某些文件嗎? 這很容易! 在下面的示例中,我們阻止了搜索引擎訪問我們網站上的所有 .pdf 文件。
User-agent: * Disallow: /*.pdf$“$”符號用於定義 URL 的結尾。 由於這是區分大小寫的,因此仍會抓取名為 my.PDF 的文件(注意大寫字母)。
複雜的邏輯表達式
一些搜索引擎,如穀歌,了解更複雜的正則表達式的使用。 但需要注意的是,並非所有搜索引擎都能理解 robots.txt 中的邏輯表達式。
一個例子是使用 $ 符號。 在 robots.txt 文件中,此符號表示 URL 的結尾。 因此,在以下示例中,我們阻止了搜索機器人讀取和索引以 .php 結尾的文件
Disallow: /*.php$這意味著 /index.php 不能被索引,但 /index.php?p=1 可以。 這僅在非常特定的情況下有用,需要謹慎使用,否則您可能會阻止機器人訪問您無意訪問的文件!

您還可以通過分別指定適用於它們的規則來為每個機器人設置不同的規則。 下面的示例代碼將限制所有機器人對 wp-admin 文件夾的訪問,同時阻止 Bing 搜索引擎對整個站點的訪問。 您不一定想這樣做,但它是一個有用的演示,說明 robots.txt 文件中的規則有多靈活。
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /XML 站點地圖
XML 站點地圖確實可以幫助搜索機器人了解您網站的佈局。 但為了有用,機器人需要知道站點地圖的位置。 “站點地圖指令”用於明確告訴搜索引擎a)您網站的站點地圖存在,以及b)他們可以在哪裡找到它。
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:您還可以指定多個站點地圖位置:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* Disallow機器人抓取延遲
另一個可以通過 robots.txt 文件實現的功能是告訴機器人“減慢”它們對您網站的抓取速度。 如果您發現您的服務器因高 bot 流量級別而過載,這可能是必要的。 為此,您需要指定要減慢速度的用戶代理,然後添加延遲。
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10此示例中的引號 (10) 是您希望在抓取網站上的各個頁面之間發生的延遲。 因此,在上面的示例中,我們要求 Bing Bot 在它爬取的每個頁面之間暫停 10 秒鐘,這樣做給我們的服務器一點喘息的空間。
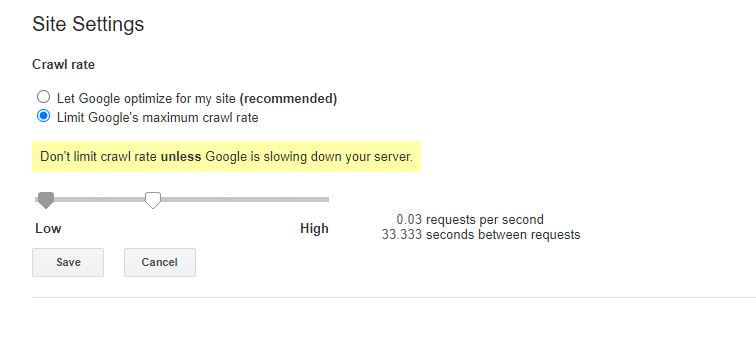
關於這個特定 robots.txt 規則的唯一一點壞消息是 Google 的機器人不尊重它。 但是,您可以在 Google Search Console 中指示他們的機器人放慢速度。
robots.txt 規則注意事項:
- 所有 robots.txt 規則都區分大小寫。 認真打字!
- 確保在行首的命令之前沒有空格。
- robots.txt 中所做的更改可能需要 24-36 小時才能被機器人注意到。
如何測試和提交您的 WordPress robots.txt 文件
當您創建了一個新的 robots.txt 文件時,值得檢查其中沒有錯誤。 您可以使用 Google Search Console 來執行此操作。
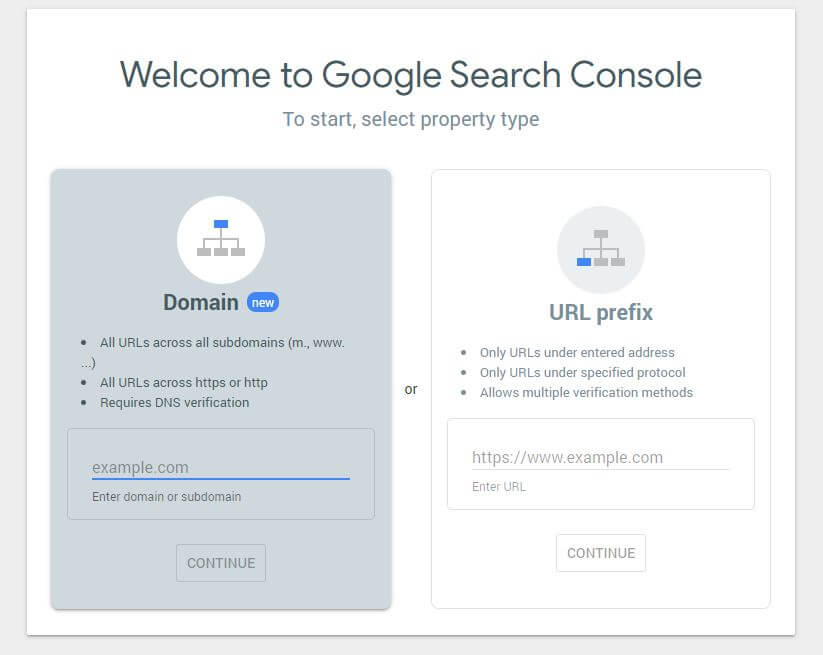
首先,您必須提交您的域(如果您還沒有用於您的網站設置的 Search Console 帳戶)。 Google 將為您提供一個 TXT 記錄,需要將其添加到您的 DNS 中以驗證您的域。
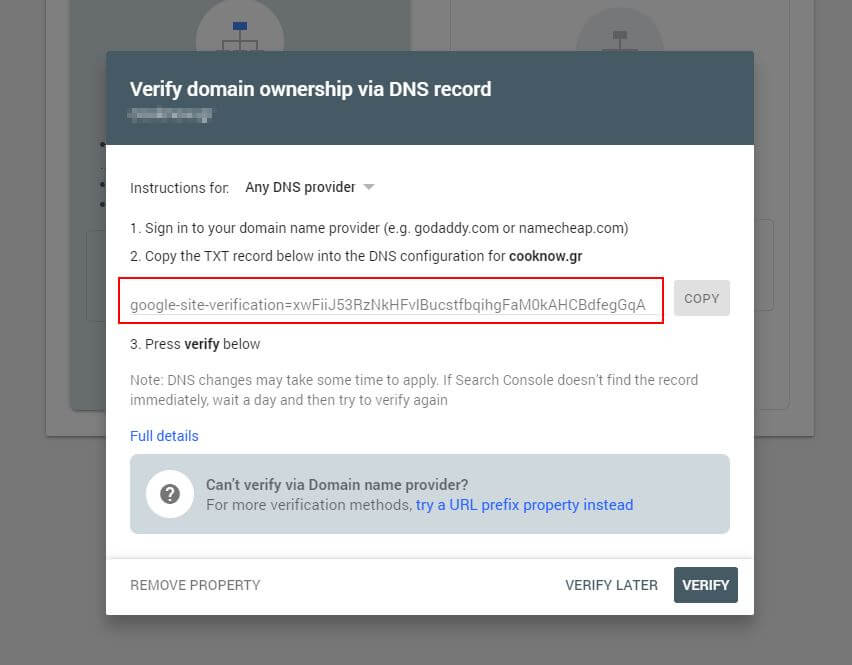
一旦這個 DNS 更新已經傳播(感覺不耐煩......嘗試使用 Cloudflare 來管理您的 DNS),您可以訪問 robots.txt 測試器並檢查是否有任何關於您的 robots.txt 文件內容的警告。
您可以做的另一件事來測試您現有的規則是否具有預期的效果是使用像 Ryte 這樣的 robots.txt 測試工具。
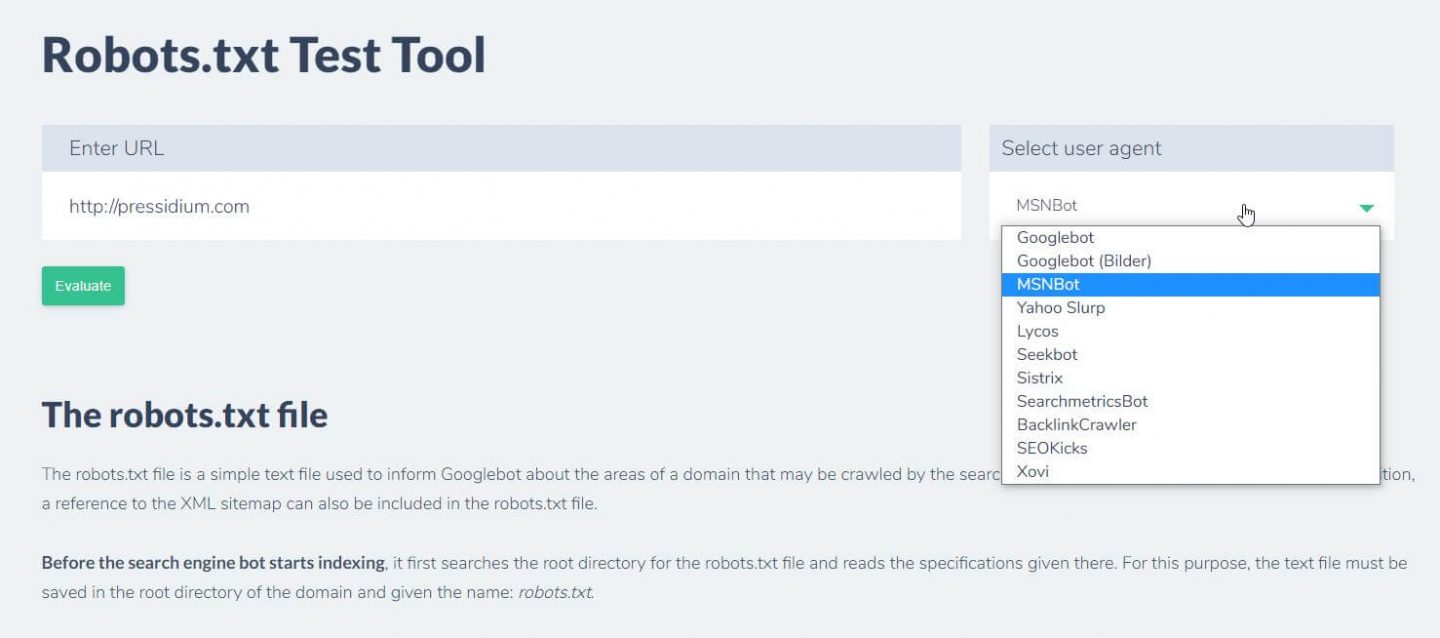
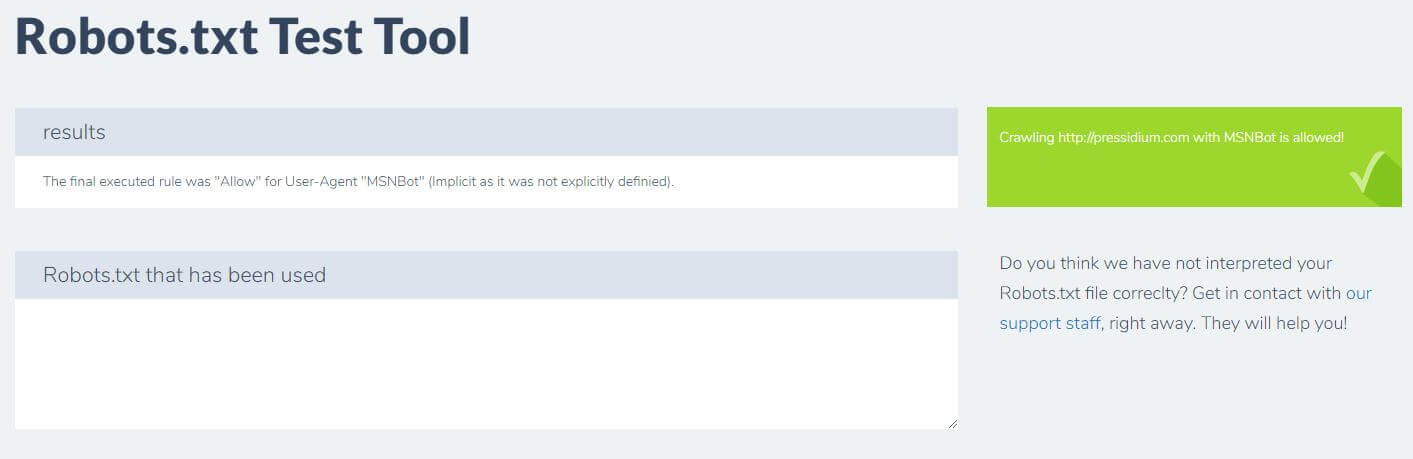
您只需輸入您的域並從右側面板中選擇一個用戶代理。 提交後,您將看到結果。
結論
了解如何使用 robots.txt 是開發人員工具包中的另一個有用工具。 如果您從本教程中獲得的唯一內容是能夠檢查您的 robots.txt 文件是否沒有阻止像 Google 這樣的機器人(您不太可能想要這樣做),那麼這不是壞事! 同樣,如您所見,robots.txt 為您的網站提供了一整套更細粒度的控制,這可能有一天會派上用場。